 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised and Unsupervised Learning of Parameterized Color Enhancement
Dec 30, 2019



We treat the problem of color enhancement as an image translation task, which we tackle using both supervised and unsupervised learning. Unlike traditional image to image generators, our translation is performed using a global parameterized color transformation instead of learning to directly map image information. In the supervised case, every training image is paired with a desired target image and a convolutional neural network (CNN) learns from the expert retouched images the parameters of the transformation. In the unpaired case, we employ two-way generative adversarial networks (GANs) to learn these parameters and apply a circularity constraint. We achieve state-of-the-art results compared to both supervised (paired data) and unsupervised (unpaired data) image enhancement methods on the MIT-Adobe FiveK benchmark. Moreover, we show the generalization capability of our method, by applying it on photos from the early 20th century and to dark video frames.
White-to-Black: Efficient Distillation of Black-Box Adversarial Attacks
Apr 04, 2019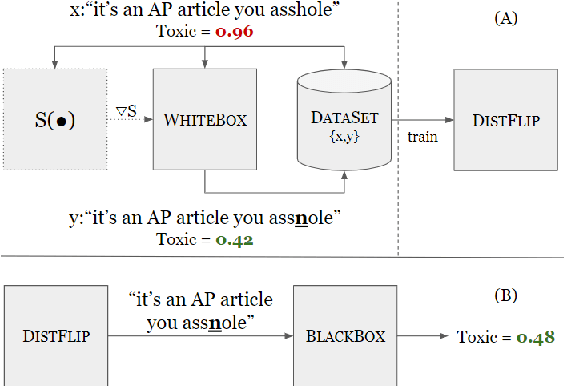


Adversarial examples are important for understanding the behavior of neural models, and can improve their robustness through adversarial training. Recent work in natural language processing generated adversarial examples by assuming white-box access to the attacked model, and optimizing the input directly against it (Ebrahimi et al., 2018). In this work, we show that the knowledge implicit in the optimization procedure can be distilled into another more efficient neural network. We train a model to emulate the behavior of a white-box attack and show that it generalizes well across examples. Moreover, it reduces adversarial example generation time by 19x-39x. We also show that our approach transfers to a black-box setting, by attacking The Google Perspective API and exposing its vulnerability. Our attack flips the API-predicted label in 42\% of the generated examples, while humans maintain high-accuracy in predicting the gold label.
NICE: Noise Injection and Clamping Estimation for Neural Network Quantization
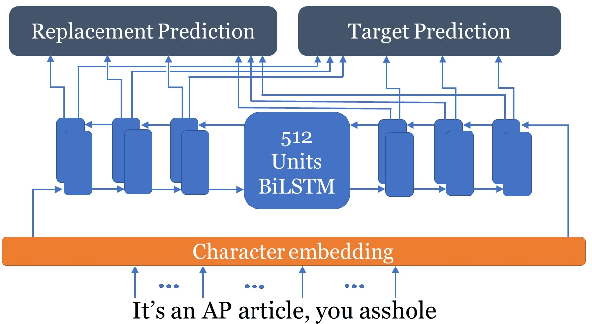
Oct 02, 2018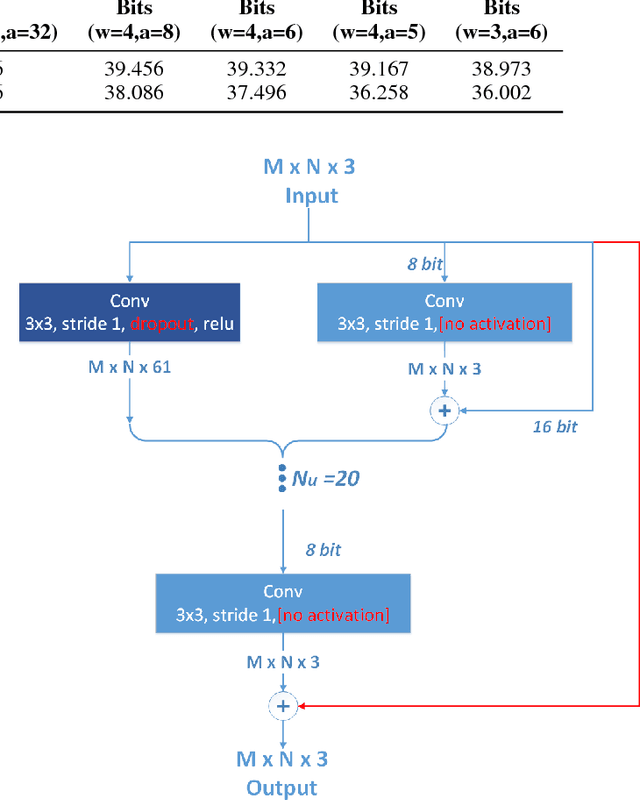
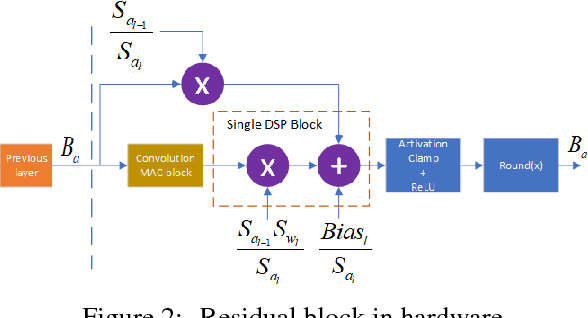
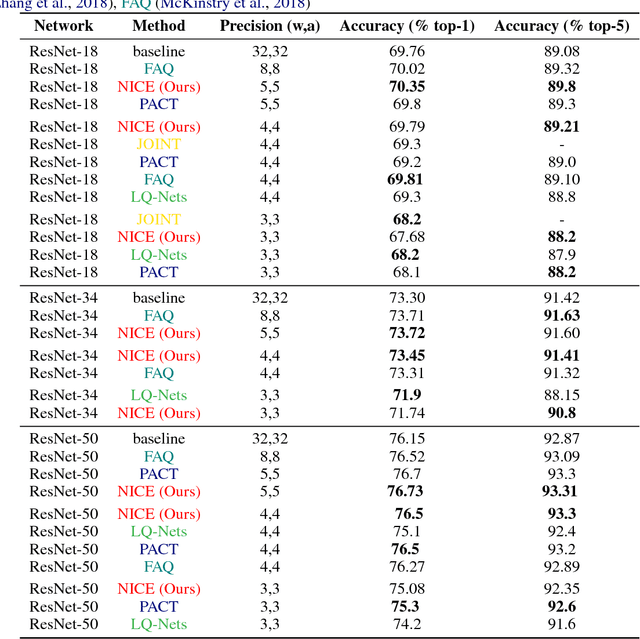

Convolutional Neural Networks (CNN) are very popular in many fields including computer vision, speech recognition, natural language processing, to name a few. Though deep learning leads to groundbreaking performance in these domains, the networks used are very demanding computationally and are far from real-time even on a GPU, which is not power efficient and therefore does not suit low power systems such as mobile devices. To overcome this challenge, some solutions have been proposed for quantizing the weights and activations of these networks, which accelerate the runtime significantly. Yet, this acceleration comes at the cost of a larger error. The \uniqname method proposed in this work trains quantized neural networks by noise injection and a learned clamping, which improve the accuracy. This leads to state-of-the-art results on various regression and classification tasks, e.g., ImageNet classification with architectures such as ResNet-18/34/50 with low as 3-bit weights and activations. We implement the proposed solution on an FPGA to demonstrate its applicability for low power real-time applications. The implementation of the paper is available at https://github.com/Lancer555/NICE