 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhite-to-Black: Efficient Distillation of Black-Box Adversarial Attacks
Apr 04, 2019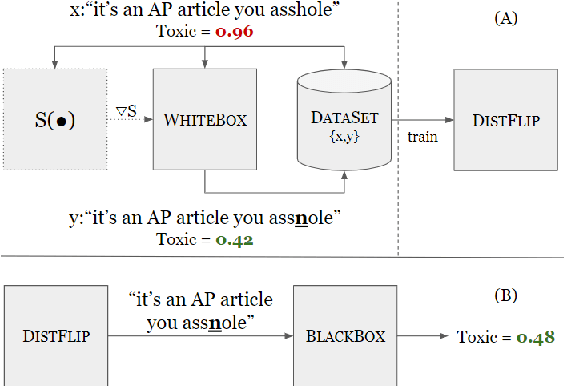

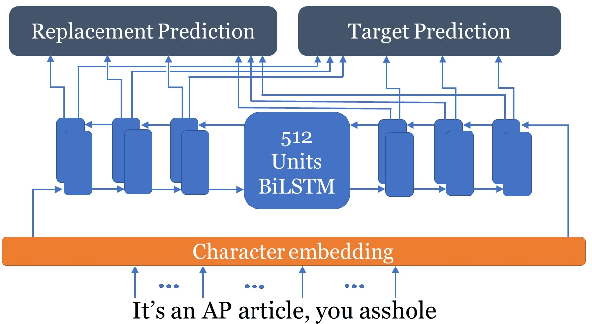

Adversarial examples are important for understanding the behavior of neural models, and can improve their robustness through adversarial training. Recent work in natural language processing generated adversarial examples by assuming white-box access to the attacked model, and optimizing the input directly against it (Ebrahimi et al., 2018). In this work, we show that the knowledge implicit in the optimization procedure can be distilled into another more efficient neural network. We train a model to emulate the behavior of a white-box attack and show that it generalizes well across examples. Moreover, it reduces adversarial example generation time by 19x-39x. We also show that our approach transfers to a black-box setting, by attacking The Google Perspective API and exposing its vulnerability. Our attack flips the API-predicted label in 42\% of the generated examples, while humans maintain high-accuracy in predicting the gold label.