 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
StarCoder 2 and The Stack v2: The Next Generation
Feb 29, 2024



The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
Semi-Supervised Semantic Segmentation via Marginal Contextual Information
Aug 26, 2023
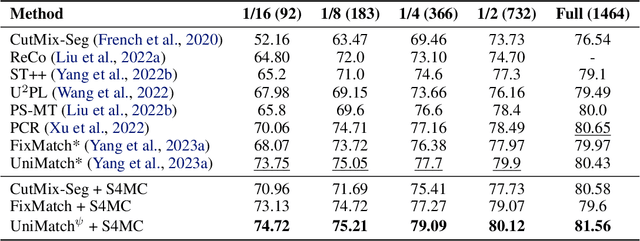
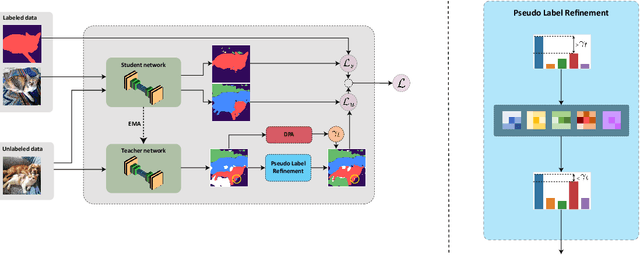
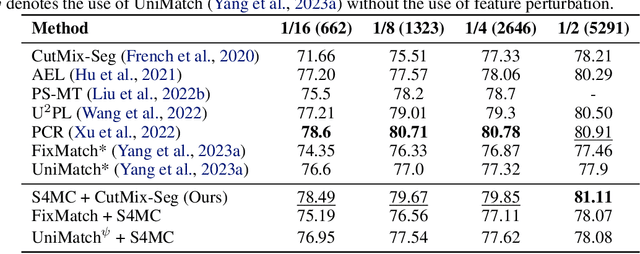
We present a novel confidence refinement scheme that enhances pseudo-labels in semi-supervised semantic segmentation. Unlike current leading methods, which filter pixels with low-confidence predictions in isolation, our approach leverages the spatial correlation of labels in segmentation maps by grouping neighboring pixels and considering their pseudo-labels collectively. With this contextual information, our method, named S4MC, increases the amount of unlabeled data used during training while maintaining the quality of the pseudo-labels, all with negligible computational overhead. Through extensive experiments on standard benchmarks, we demonstrate that S4MC outperforms existing state-of-the-art semi-supervised learning approaches, offering a promising solution for reducing the cost of acquiring dense annotations. For example, S4MC achieves a 1.29 mIoU improvement over the prior state-of-the-art method on PASCAL VOC 12 with 366 annotated images. The code to reproduce our experiments is available at https://s4mcontext.github.io/
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
GoToNet: Fast Monocular Scene Exposure and Exploration
Jun 13, 2022


Autonomous scene exposure and exploration, especially in localization or communication-denied areas, useful for finding targets in unknown scenes, remains a challenging problem in computer navigation. In this work, we present a novel method for real-time environment exploration, whose only requirements are a visually similar dataset for pre-training, enough lighting in the scene, and an on-board forward-looking RGB camera for environmental sensing. As opposed to existing methods, our method requires only one look (image) to make a good tactical decision, and therefore works at a non-growing, constant time. Two direction predictions, characterized by pixels dubbed the Goto and Lookat pixels, comprise the core of our method. These pixels encode the recommended flight instructions in the following way: the Goto pixel defines the direction in which the agent should move by one distance unit, and the Lookat pixel defines the direction in which the camera should be pointing at in the next step. These flying-instruction pixels are optimized to expose the largest amount of currently unexplored areas. Our method presents a novel deep learning-based navigation approach that is able to solve this problem and demonstrate its ability in an even more complicated setup, i.e., when computational power is limited. In addition, we propose a way to generate a navigation-oriented dataset, enabling efficient training of our method using RGB and depth images. Tests conducted in a simulator evaluating both the sparse pixels' coordinations inferring process, and 2D and 3D test flights aimed to unveil areas and decrease distances to targets achieve promising results. Comparison against a state-of-the-art algorithm shows our method is able to overperform it, that while measuring the new voxels per camera pose, minimum distance to target, percentage of surface voxels seen, and compute time metrics.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
On Recoverability of Graph Neural Network Representations
Jan 30, 2022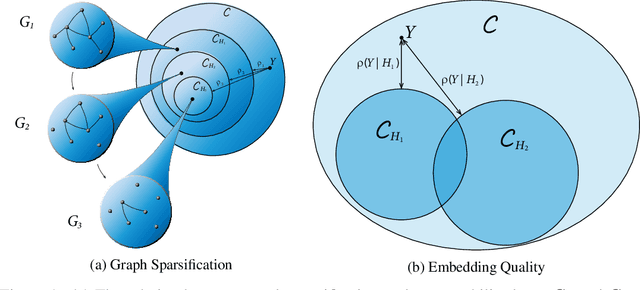
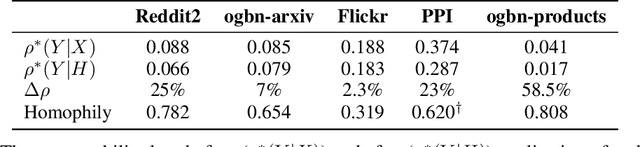
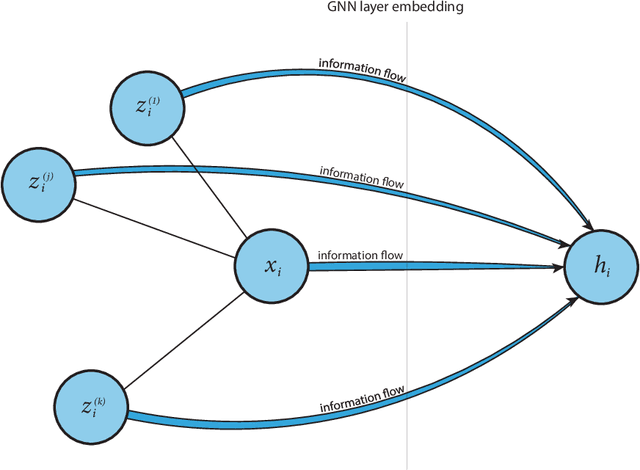

Despite their growing popularity, graph neural networks (GNNs) still have multiple unsolved problems, including finding more expressive aggregation methods, propagation of information to distant nodes, and training on large-scale graphs. Understanding and solving such problems require developing analytic tools and techniques. In this work, we propose the notion of recoverability, which is tightly related to information aggregation in GNNs, and based on this concept, develop the method for GNN embedding analysis. We define recoverability theoretically and propose a method for its efficient empirical estimation. We demonstrate, through extensive experimental results on various datasets and different GNN architectures, that estimated recoverability correlates with aggregation method expressivity and graph sparsification quality. Therefore, we believe that the proposed method could provide an essential tool for understanding the roots of the aforementioned problems, and potentially lead to a GNN design that overcomes them. The code to reproduce our experiments is available at https://github.com/Anonymous1252022/Recoverability
End-to-End Referring Video Object Segmentation with Multimodal Transformers
Nov 29, 2021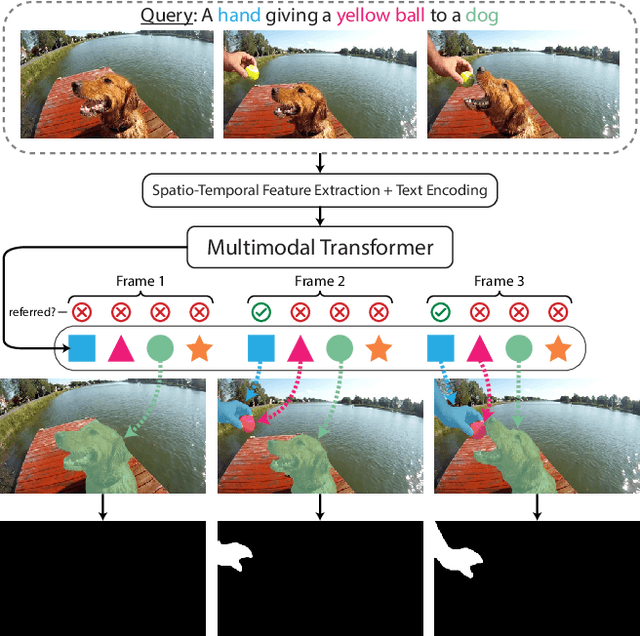
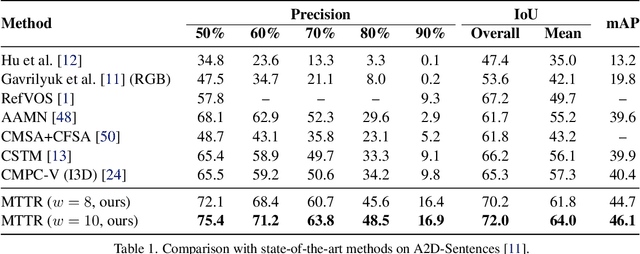
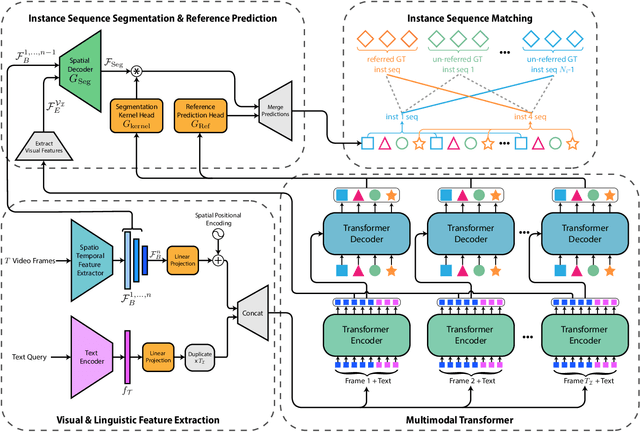
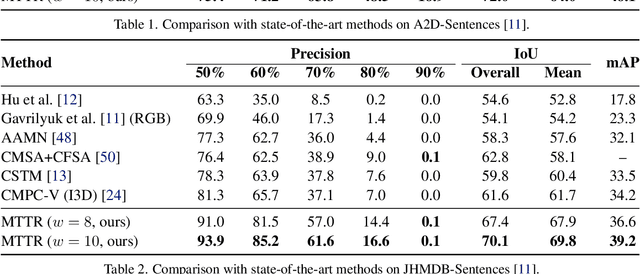
The referring video object segmentation task (RVOS) involves segmentation of a text-referred object instance in the frames of a given video. Due to the complex nature of this multimodal task, which combines text reasoning, video understanding, instance segmentation and tracking, existing approaches typically rely on sophisticated pipelines in order to tackle it. In this paper, we propose a simple Transformer-based approach to RVOS. Our framework, termed Multimodal Tracking Transformer (MTTR), models the RVOS task as a sequence prediction problem. Following recent advancements in computer vision and natural language processing, MTTR is based on the realization that video and text can both be processed together effectively and elegantly by a single multimodal Transformer model. MTTR is end-to-end trainable, free of text-related inductive bias components and requires no additional mask-refinement post-processing steps. As such, it simplifies the RVOS pipeline considerably compared to existing methods. Evaluation on standard benchmarks reveals that MTTR significantly outperforms previous art across multiple metrics. In particular, MTTR shows impressive +5.7 and +5.0 mAP gains on the A2D-Sentences and JHMDB-Sentences datasets respectively, while processing 76 frames per second. In addition, we report strong results on the public validation set of Refer-YouTube-VOS, a more challenging RVOS dataset that has yet to receive the attention of researchers. The code to reproduce our experiments is available at https://github.com/mttr2021/MTTR
Contrast to Divide: Self-Supervised Pre-Training for Learning with Noisy Labels
Mar 25, 2021
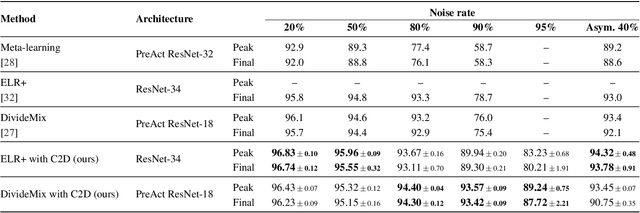
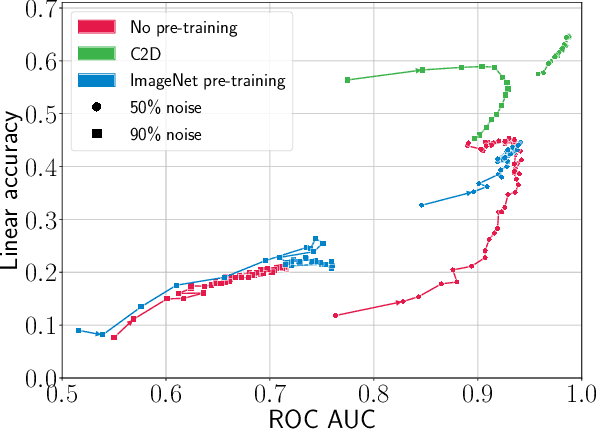
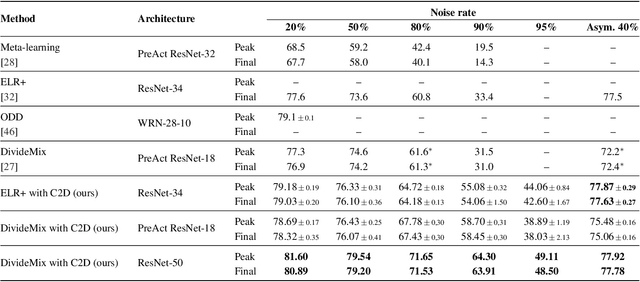
The success of learning with noisy labels (LNL) methods relies heavily on the success of a warm-up stage where standard supervised training is performed using the full (noisy) training set. In this paper, we identify a "warm-up obstacle": the inability of standard warm-up stages to train high quality feature extractors and avert memorization of noisy labels. We propose "Contrast to Divide" (C2D), a simple framework that solves this problem by pre-training the feature extractor in a self-supervised fashion. Using self-supervised pre-training boosts the performance of existing LNL approaches by drastically reducing the warm-up stage's susceptibility to noise level, shortening its duration, and increasing extracted feature quality. C2D works out of the box with existing methods and demonstrates markedly improved performance, especially in the high noise regime, where we get a boost of more than 27% for CIFAR-100 with 90% noise over the previous state of the art. In real-life noise settings, C2D trained on mini-WebVision outperforms previous works both in WebVision and ImageNet validation sets by 3% top-1 accuracy. We perform an in-depth analysis of the framework, including investigating the performance of different pre-training approaches and estimating the effective upper bound of the LNL performance with semi-supervised learning. Code for reproducing our experiments is available at https://github.com/ContrastToDivide/C2D
Single-Node Attack for Fooling Graph Neural Networks
Nov 06, 2020
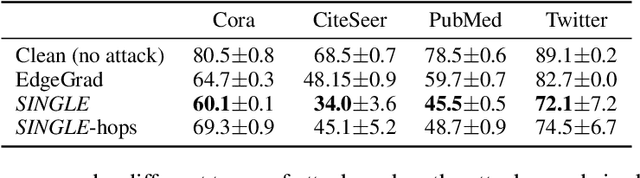
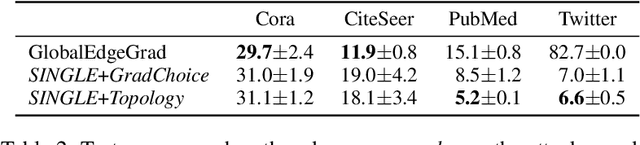
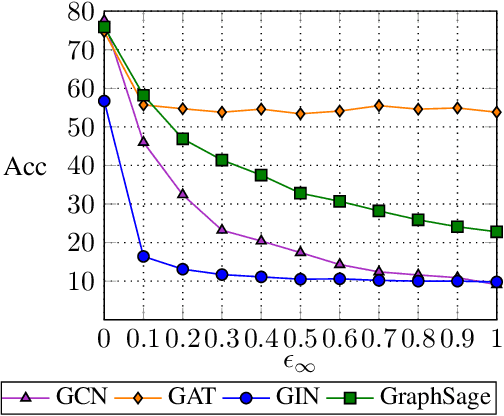
Graph neural networks (GNNs) have shown broad applicability in a variety of domains. Some of these domains, such as social networks and product recommendations, are fertile ground for malicious users and behavior. In this paper, we show that GNNs are vulnerable to the extremely limited scenario of a single-node adversarial example, where the node cannot be picked by the attacker. That is, an attacker can force the GNN to classify any target node to a chosen label by only slightly perturbing another single arbitrary node in the graph, even when not being able to pick that specific attacker node. When the adversary is allowed to pick a specific attacker node, the attack is even more effective. We show that this attack is effective across various GNN types, such as GraphSAGE, GCN, GAT, and GIN, across a variety of real-world datasets, and as a targeted and a non-targeted attack. Our code is available at https://github.com/benfinkelshtein/SINGLE .