 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Feedback Generation in Automated Skeletal Movement Assessment: A Comprehensive Overview
Apr 14, 2024The application of machine-learning solutions to movement assessment from skeleton videos has attracted significant research attention in recent years. This advancement has made rehabilitation at home more accessible, utilizing movement assessment algorithms that can operate on affordable equipment for human pose detection from 2D or 3D videos. While the primary objective of automatic assessment tasks is to score movements, the automatic generation of feedback highlighting key movement issues has the potential to significantly enhance and accelerate the rehabilitation process. In this study, we explain the types of feedback that can be generated, review existing solutions for automatic feedback generation, and discuss future research directions. To our knowledge, this is the first comprehensive review of feedback generation in skeletal movement assessment.
Accuracy Prediction for NAS Acceleration using Feature Selection and Extrapolation
Nov 22, 2022Predicting the accuracy of candidate neural architectures is an important capability of NAS-based solutions. When a candidate architecture has properties that are similar to other known architectures, the prediction task is rather straightforward using off-the-shelf regression algorithms. However, when a candidate architecture lies outside of the known space of architectures, a regression model has to perform extrapolated predictions, which is not only a challenging task, but also technically impossible using the most popular regression algorithm families, which are based on decision trees. In this work, we are trying to address two problems. The first one is improving regression accuracy using feature selection, whereas the other one is the evaluation of regression algorithms on extrapolating accuracy prediction tasks. We extend the NAAP-440 dataset with new tabular features and introduce NAAP-440e, which we use for evaluation. We observe a dramatic improvement from the old baseline, namely, the new baseline requires 3x shorter training processes of candidate architectures, while maintaining the same mean-absolute-error and achieving almost 2x fewer monotonicity violations, compared to the old baseline's best reported performance. The extended dataset and code used in the study have been made public in the NAAP-440 repository.
NAAP-440 Dataset and Baseline for Neural Architecture Accuracy Prediction
Sep 28, 2022
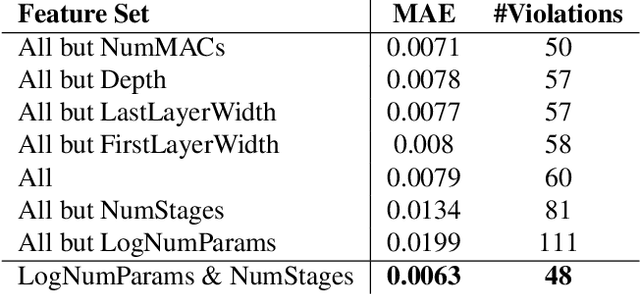
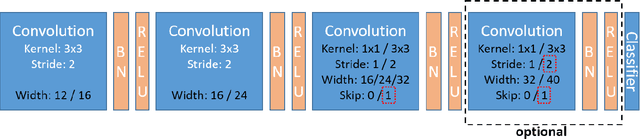

Neural architecture search (NAS) has become a common approach to developing and discovering new neural architectures for different target platforms and purposes. However, scanning the search space is comprised of long training processes of many candidate architectures, which is costly in terms of computational resources and time. Regression algorithms are a common tool to predicting a candidate architecture's accuracy, which can dramatically accelerate the search procedure. We aim at proposing a new baseline that will support the development of regression algorithms that can predict an architecture's accuracy just from its scheme, or by only training it for a minimal number of epochs. Therefore, we introduce the NAAP-440 dataset of 440 neural architectures, which were trained on CIFAR10 using a fixed recipe. Our experiments indicate that by using off-the-shelf regression algorithms and running up to 10% of the training process, not only is it possible to predict an architecture's accuracy rather precisely, but that the values predicted for the architectures also maintain their accuracy order with a minimal number of monotonicity violations. This approach may serve as a powerful tool for accelerating NAS-based studies and thus dramatically increase their efficiency. The dataset and code used in the study have been made public.
A Comprehensive Review of Skeleton-based Movement Assessment Methods
Jul 29, 2020



The raising availability of 3D cameras and dramatic improvement of computer vision algorithms in the recent decade, accelerated the research of automatic movement assessment solutions. Such solutions can be implemented at home, using affordable equipment and dedicated software. In this paper, we divide the movement assessment task into secondary tasks and explain why they are needed and how they can be addressed. We review the recent solutions for automatic movement assessment from skeleton videos, comparing them by their objectives, features, movement domains and algorithmic approaches. In addition, we discuss the status of the research on this topic in a high level.
A-MAL: Automatic Motion Assessment Learning from Properly Performed Motions in 3D Skeleton Videos
Aug 29, 2019


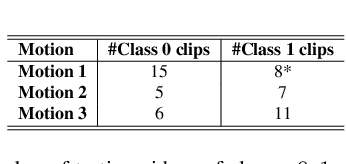
Assessment of motion quality has recently gained high demand in a variety of domains. The ability to automatically assess subject motion in videos that were captured by cheap devices, such as Kinect cameras, is essential for monitoring clinical rehabilitation processes, for improving motor skills and for motion learning tasks. The need to pay attention to low-level details while accurately tracking the motion stages, makes this task very challenging. In this work, we introduce A-MAL, an automatic, strong motion assessment learning algorithm that only learns from properly-performed motion videos without further annotations, powered by a deviation time-segmentation algorithm, a parameter relevance detection algorithm, a novel time-warping algorithm that is based on automatic detection of common temporal points-of-interest and a textual-feedback generation mechanism. We demonstrate our method on motions from the Fugl-Meyer Assessment (FMA) test, which is typically held by occupational therapists in order to monitor patients' recovery processes after strokes.
Toward Self-Supervised Object Detection in Unlabeled Videos
May 27, 2019

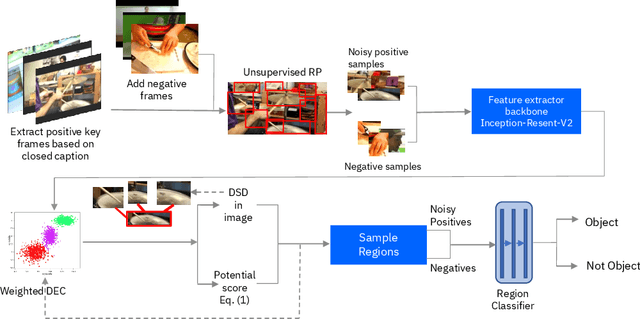
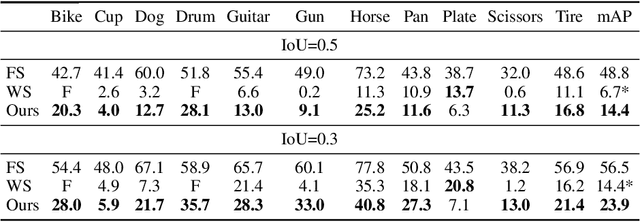
Unlabeled video in the wild presents a valuable, yet so far unharnessed, source of information for learning vision tasks. We present the first attempt of fully self-supervised learning of object detection from subtitled videos without any manual object annotation. To this end, we use the How2 multi-modal collection of instructional videos with English subtitles. We pose the problem as learning with a weakly- and noisily-labeled data, and propose a novel training model that can confront high noise levels, and yet train a classifier to localize the object of interest in the video frames, without any manual labeling involved. We evaluate our approach on a set of 11 manually annotated objects in over 5000 frames and compare it to an existing weakly-supervised approach as baseline. Benchmark data and code will be released upon acceptance of the paper.