 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Self-Supervised Object Detection in Unlabeled Videos
Paper and Code


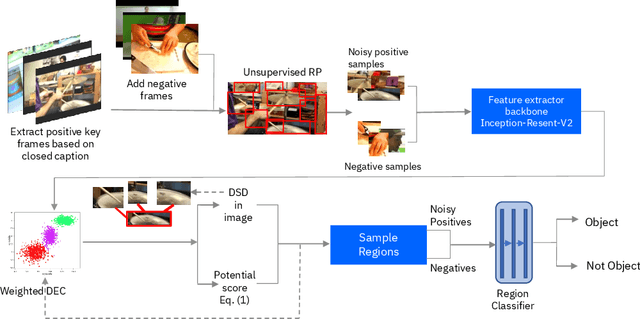
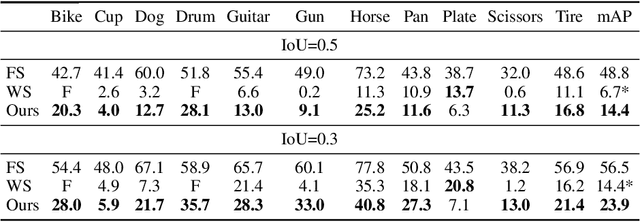
Unlabeled video in the wild presents a valuable, yet so far unharnessed, source of information for learning vision tasks. We present the first attempt of fully self-supervised learning of object detection from subtitled videos without any manual object annotation. To this end, we use the How2 multi-modal collection of instructional videos with English subtitles. We pose the problem as learning with a weakly- and noisily-labeled data, and propose a novel training model that can confront high noise levels, and yet train a classifier to localize the object of interest in the video frames, without any manual labeling involved. We evaluate our approach on a set of 11 manually annotated objects in over 5000 frames and compare it to an existing weakly-supervised approach as baseline. Benchmark data and code will be released upon acceptance of the paper.