 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample- and Parameter-Efficient Auto-Regressive Image Models
Nov 23, 2024



We introduce XTRA, a vision model pre-trained with a novel auto-regressive objective that significantly enhances both sample and parameter efficiency compared to previous auto-regressive image models. Unlike contrastive or masked image modeling methods, which have not been demonstrated as having consistent scaling behavior on unbalanced internet data, auto-regressive vision models exhibit scalable and promising performance as model and dataset size increase. In contrast to standard auto-regressive models, XTRA employs a Block Causal Mask, where each Block represents k $\times$ k tokens rather than relying on a standard causal mask. By reconstructing pixel values block by block, XTRA captures higher-level structural patterns over larger image regions. Predicting on blocks allows the model to learn relationships across broader areas of pixels, enabling more abstract and semantically meaningful representations than traditional next-token prediction. This simple modification yields two key results. First, XTRA is sample-efficient. Despite being trained on 152$\times$ fewer samples (13.1M vs. 2B), XTRA ViT-H/14 surpasses the top-1 average accuracy of the previous state-of-the-art auto-regressive model across 15 diverse image recognition benchmarks. Second, XTRA is parameter-efficient. Compared to auto-regressive models trained on ImageNet-1k, XTRA ViT-B/16 outperforms in linear and attentive probing tasks, using 7-16$\times$ fewer parameters (85M vs. 1.36B/0.63B).
KVP10k : A Comprehensive Dataset for Key-Value Pair Extraction in Business Documents
May 01, 2024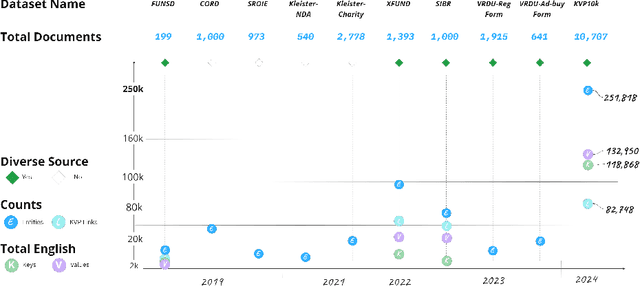
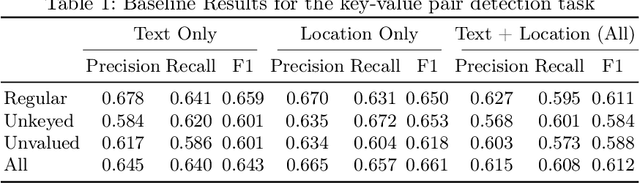
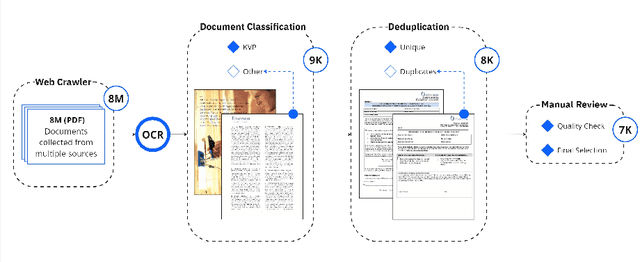

In recent years, the challenge of extracting information from business documents has emerged as a critical task, finding applications across numerous domains. This effort has attracted substantial interest from both industry and academy, highlighting its significance in the current technological landscape. Most datasets in this area are primarily focused on Key Information Extraction (KIE), where the extraction process revolves around extracting information using a specific, predefined set of keys. Unlike most existing datasets and benchmarks, our focus is on discovering key-value pairs (KVPs) without relying on predefined keys, navigating through an array of diverse templates and complex layouts. This task presents unique challenges, primarily due to the absence of comprehensive datasets and benchmarks tailored for non-predetermined KVP extraction. To address this gap, we introduce KVP10k , a new dataset and benchmark specifically designed for KVP extraction. The dataset contains 10707 richly annotated images. In our benchmark, we also introduce a new challenging task that combines elements of KIE as well as KVP in a single task. KVP10k sets itself apart with its extensive diversity in data and richly detailed annotations, paving the way for advancements in the field of information extraction from complex business documents.
Learnable Optimal Sequential Grouping for Video Scene Detection
May 17, 2022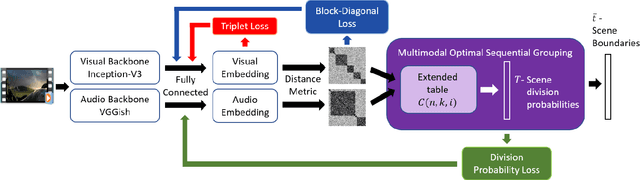
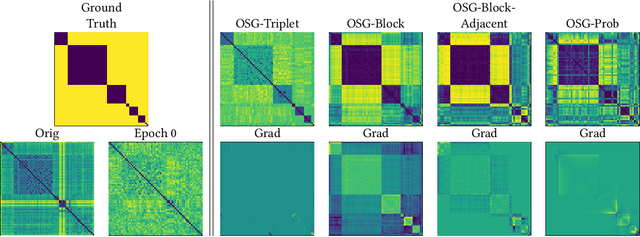
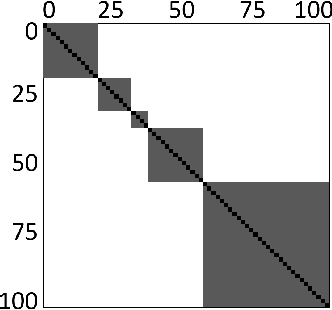
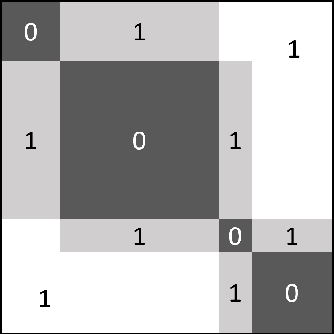
Video scene detection is the task of dividing videos into temporal semantic chapters. This is an important preliminary step before attempting to analyze heterogeneous video content. Recently, Optimal Sequential Grouping (OSG) was proposed as a powerful unsupervised solution to solve a formulation of the video scene detection problem. In this work, we extend the capabilities of OSG to the learning regime. By giving the capability to both learn from examples and leverage a robust optimization formulation, we can boost performance and enhance the versatility of the technology. We present a comprehensive analysis of incorporating OSG into deep learning neural networks under various configurations. These configurations include learning an embedding in a straight-forward manner, a tailored loss designed to guide the solution of OSG, and an integrated model where the learning is performed through the OSG pipeline. With thorough evaluation and analysis, we assess the benefits and behavior of the various configurations, and show that our learnable OSG approach exhibits desirable behavior and enhanced performance compared to the state of the art.
Unsupervised Domain Generalization by Learning a Bridge Across Domains
Dec 04, 2021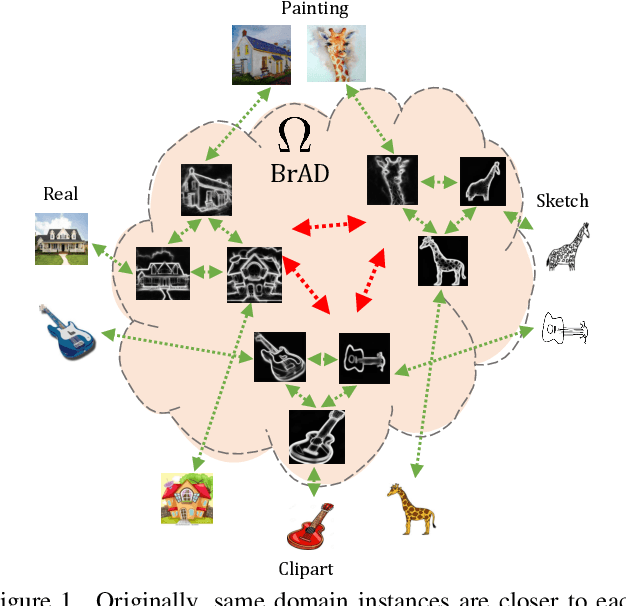
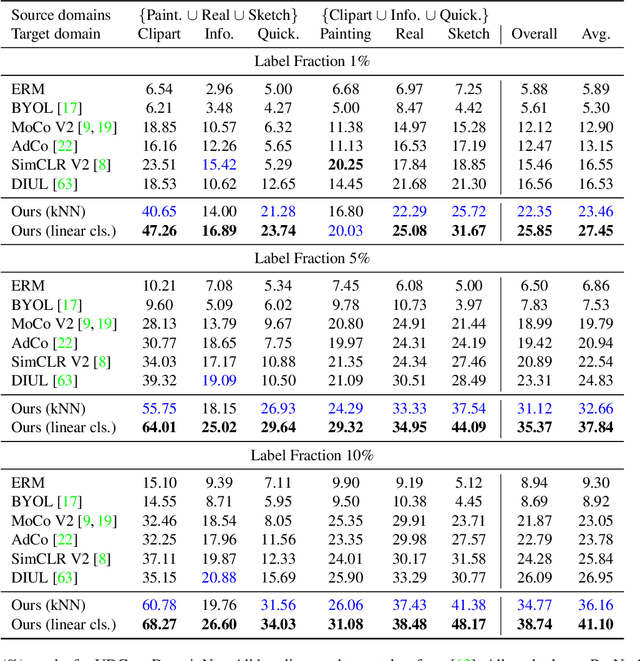
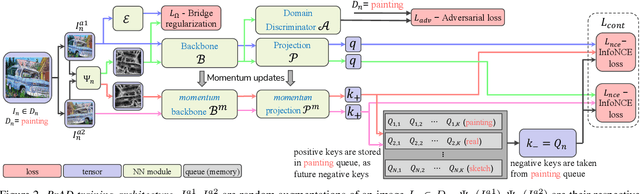
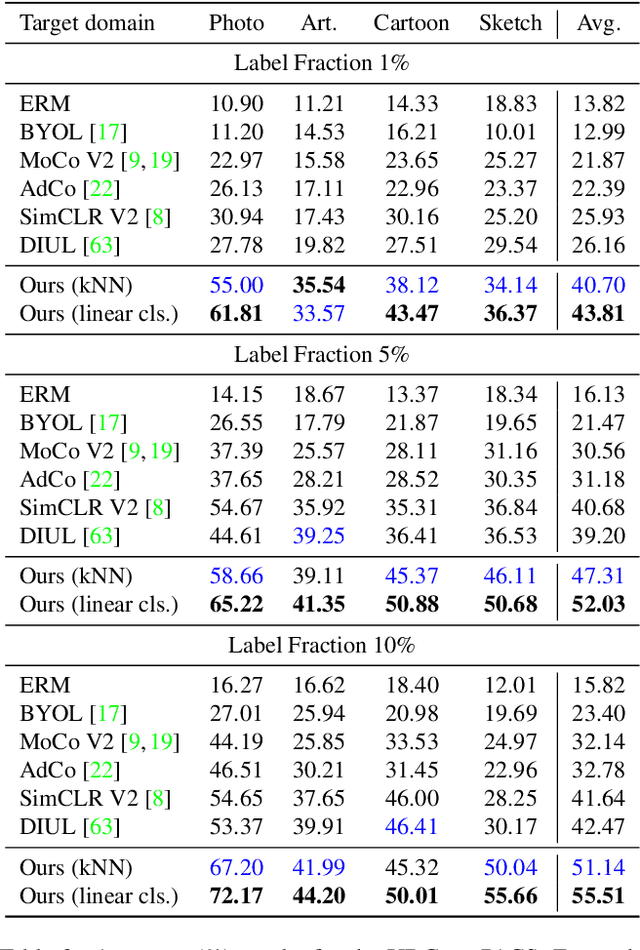
The ability to generalize learned representations across significantly different visual domains, such as between real photos, clipart, paintings, and sketches, is a fundamental capacity of the human visual system. In this paper, different from most cross-domain works that utilize some (or full) source domain supervision, we approach a relatively new and very practical Unsupervised Domain Generalization (UDG) setup of having no training supervision in neither source nor target domains. Our approach is based on self-supervised learning of a Bridge Across Domains (BrAD) - an auxiliary bridge domain accompanied by a set of semantics preserving visual (image-to-image) mappings to BrAD from each of the training domains. The BrAD and mappings to it are learned jointly (end-to-end) with a contrastive self-supervised representation model that semantically aligns each of the domains to its BrAD-projection, and hence implicitly drives all the domains (seen or unseen) to semantically align to each other. In this work, we show how using an edge-regularized BrAD our approach achieves significant gains across multiple benchmarks and a range of tasks, including UDG, Few-shot UDA, and unsupervised generalization across multi-domain datasets (including generalization to unseen domains and classes).
Self-Supervised Classification Network
Mar 19, 2021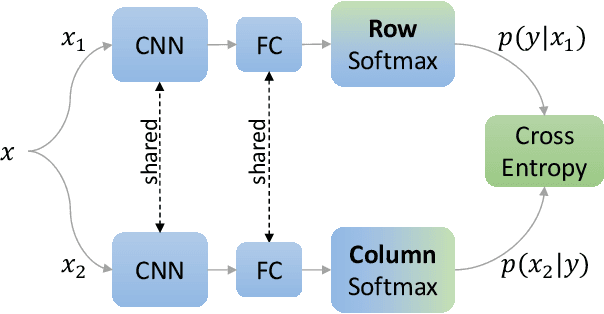
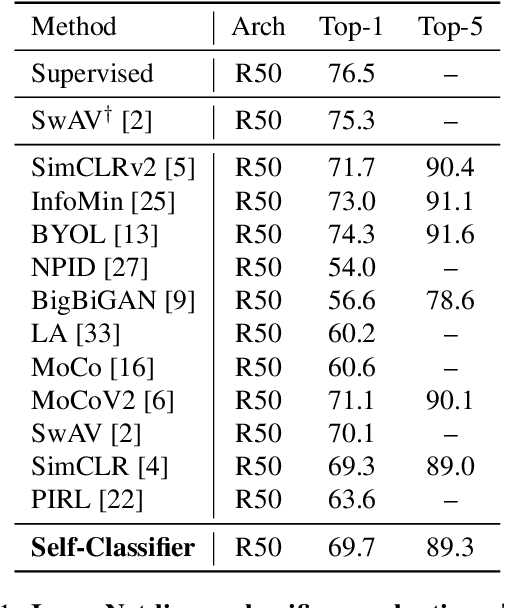
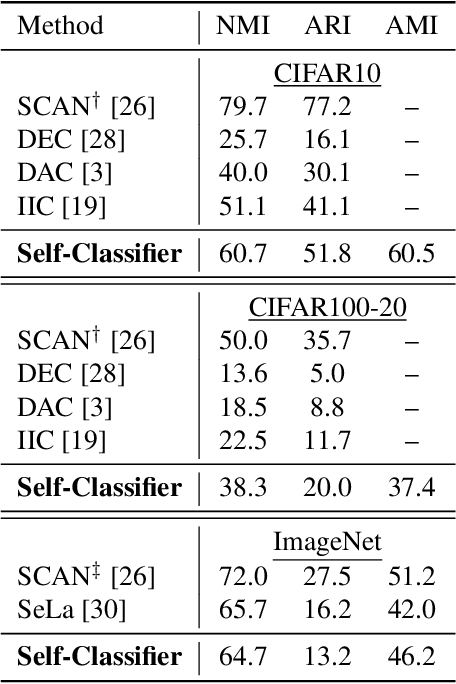
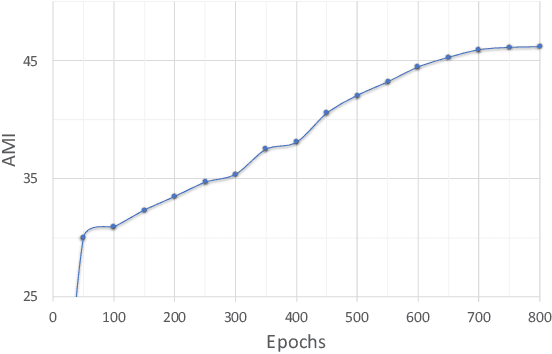
We present Self-Classifier -- a novel self-supervised end-to-end classification neural network. Self-Classifier learns labels and representations simultaneously in a single-stage end-to-end manner by optimizing for same-class prediction of two augmented views of the same sample. To guarantee non-degenerate solutions (i.e., solutions where all labels are assigned to the same class), a uniform prior is asserted on the labels. We show mathematically that unlike the regular cross-entropy loss, our approach avoids such solutions. Self-Classifier is simple to implement and is scalable to practically unlimited amounts of data. Unlike other unsupervised classification approaches, it does not require any form of pre-training or the use of expectation maximization algorithms, pseudo-labelling or external clustering. Unlike other contrastive learning representation learning approaches, it does not require a memory bank or a second network. Despite its relative simplicity, our approach achieves comparable results to state-of-the-art performance with ImageNet, CIFAR10 and CIFAR100 for its two objectives: unsupervised classification and unsupervised representation learning. Furthermore, it is the first unsupervised end-to-end classification network to perform well on the large-scale ImageNet dataset. Code will be made available.
Noise Estimation Using Density Estimation for Self-Supervised Multimodal Learning
Mar 06, 2020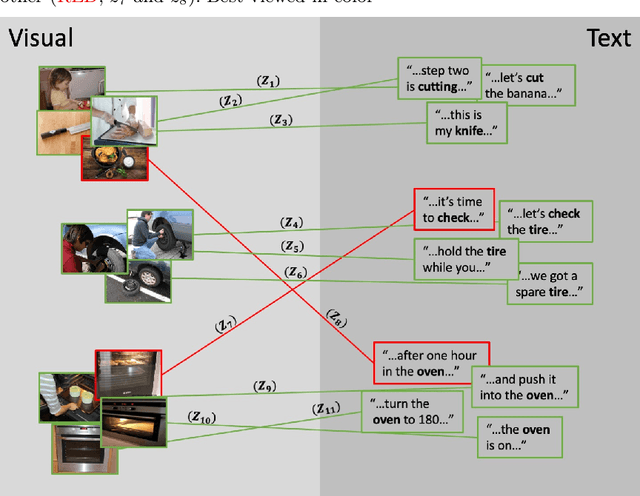
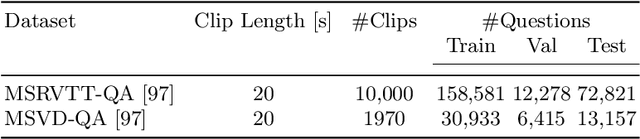
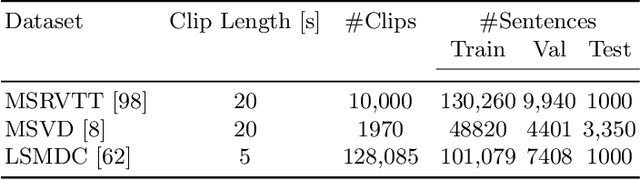
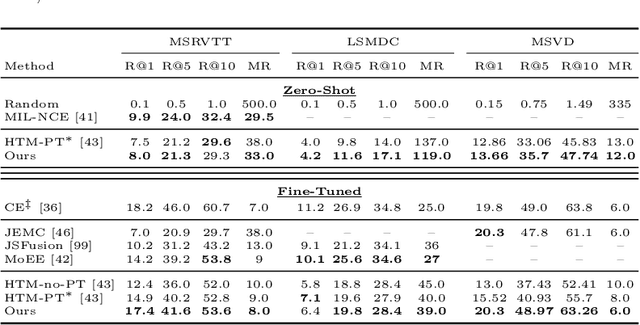
One of the key factors of enabling machine learning models to comprehend and solve real-world tasks is to leverage multimodal data. Unfortunately, annotation of multimodal data is challenging and expensive. Recently, self-supervised multimodal methods that combine vision and language were proposed to learn multimodal representations without annotation. However, these methods choose to ignore the presence of high levels of noise and thus yield sub-optimal results. In this work, we show that the problem of noise estimation for multimodal data can be reduced to a multimodal density estimation task. Using multimodal density estimation, we propose a noise estimation building block for multimodal representation learning that is based strictly on the inherent correlation between different modalities. We demonstrate how our noise estimation can be broadly integrated and achieves comparable results to state-of-the-art performance on five different benchmark datasets for two challenging multimodal tasks: Video Question Answering and Text-To-Video Retrieval.
Toward Self-Supervised Object Detection in Unlabeled Videos
May 27, 2019

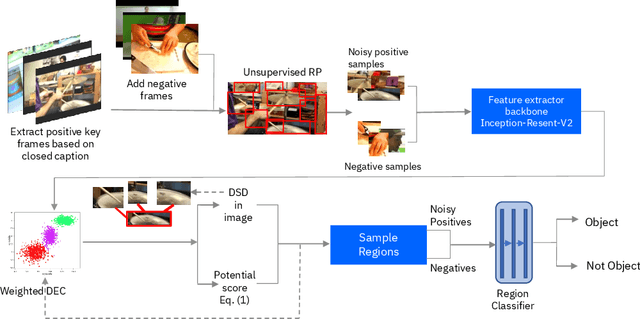
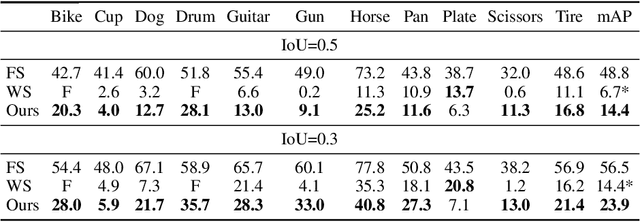
Unlabeled video in the wild presents a valuable, yet so far unharnessed, source of information for learning vision tasks. We present the first attempt of fully self-supervised learning of object detection from subtitled videos without any manual object annotation. To this end, we use the How2 multi-modal collection of instructional videos with English subtitles. We pose the problem as learning with a weakly- and noisily-labeled data, and propose a novel training model that can confront high noise levels, and yet train a classifier to localize the object of interest in the video frames, without any manual labeling involved. We evaluate our approach on a set of 11 manually annotated objects in over 5000 frames and compare it to an existing weakly-supervised approach as baseline. Benchmark data and code will be released upon acceptance of the paper.