 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs the Modality Gap a Bug or a Feature? A Robustness Perspective
Mar 30, 2026Many modern multi-modal models (e.g. CLIP) seek an embedding space in which the two modalities are aligned. Somewhat surprisingly, almost all existing models show a strong modality gap: the distribution of images is well-separated from the distribution of texts in the shared embedding space. Despite a series of recent papers on this topic, it is still not clear why this gap exists nor whether closing the gap in post-processing will lead to better performance on downstream tasks. In this paper we show that under certain conditions, minimizing the contrastive loss yields a representation in which the two modalities are separated by a global gap vector that is orthogonal to their embeddings. We also show that under these conditions the modality gap is monotonically related to robustness: decreasing the gap does not change the clean accuracy of the models but makes it less likely that a model will change its output when the embeddings are perturbed. Our experiments show that for many real-world VLMs we can significantly increase robustness by a simple post-processing step that moves one modality towards the mean of the other modality, without any loss of clean accuracy.
Col-Bandit: Zero-Shot Query-Time Pruning for Late-Interaction Retrieval
Feb 02, 2026Multi-vector late-interaction retrievers such as ColBERT achieve state-of-the-art retrieval quality, but their query-time cost is dominated by exhaustively computing token-level MaxSim interactions for every candidate document. While approximating late interaction with single-vector representations reduces cost, it often incurs substantial accuracy loss. We introduce Col-Bandit, a query-time pruning algorithm that reduces this computational burden by casting reranking as a finite-population Top-$K$ identification problem. Col-Bandit maintains uncertainty-aware bounds over partially observed document scores and adaptively reveals only the (document, query token) MaxSim entries needed to determine the top results under statistical decision bounds with a tunable relaxation. Unlike coarse-grained approaches that prune entire documents or tokens offline, Col-Bandit sparsifies the interaction matrix on the fly. It operates as a zero-shot, drop-in layer over standard multi-vector systems, requiring no index modifications, offline preprocessing, or model retraining. Experiments on textual (BEIR) and multimodal (REAL-MM-RAG) benchmarks show that Col-Bandit preserves ranking fidelity while reducing MaxSim FLOPs by up to 5$\times$, indicating that dense late-interaction scoring contains substantial redundancy that can be identified and pruned efficiently at query time.
Token Maturation: Autoregressive Language Generation via Continuous Token Dynamics
Jan 08, 2026Autoregressive language models are conventionally defined over discrete token sequences, committing to a specific token at every generation step. This early discretization forces uncertainty to be resolved through token-level sampling, often leading to instability, repetition, and sensitivity to decoding heuristics. In this work, we introduce a continuous autoregressive formulation of language generation in which tokens are represented as continuous vectors that \emph{mature} over multiple update steps before being discretized. Rather than sampling tokens, the model evolves continuous token representations through a deterministic dynamical process, committing to a discrete token only when the representation has sufficiently converged. Discrete text is recovered via hard decoding, while uncertainty is maintained and resolved in the continuous space. We show that this maturation process alone is sufficient to produce coherent and diverse text using deterministic decoding (argmax), without reliance on token-level sampling, diffusion-style denoising, or auxiliary stabilization mechanisms. Additional perturbations, such as stochastic dynamics or history smoothing, can be incorporated naturally but are not required for the model to function. To our knowledge, this is the first autoregressive language model that generates text by evolving continuous token representations to convergence prior to discretization, enabling stable generation without token-level sampling.
Complexity as Advantage: A Regret-Based Perspective on Emergent Structure
Nov 06, 2025We introduce Complexity as Advantage (CAA), a framework that defines the complexity of a system relative to a family of observers. Instead of measuring complexity as an intrinsic property, we evaluate how much predictive regret a system induces for different observers attempting to model it. A system is complex when it is easy for some observers and hard for others, creating an information advantage. We show that this formulation unifies several notions of emergent behavior, including multiscale entropy, predictive information, and observer-dependent structure. The framework suggests that "interesting" systems are those positioned to create differentiated regret across observers, providing a quantitative grounding for why complexity can be functionally valuable. We demonstrate the idea through simple dynamical models and discuss implications for learning, evolution, and artificial agents.
REAL-MM-RAG: A Real-World Multi-Modal Retrieval Benchmark
Feb 17, 2025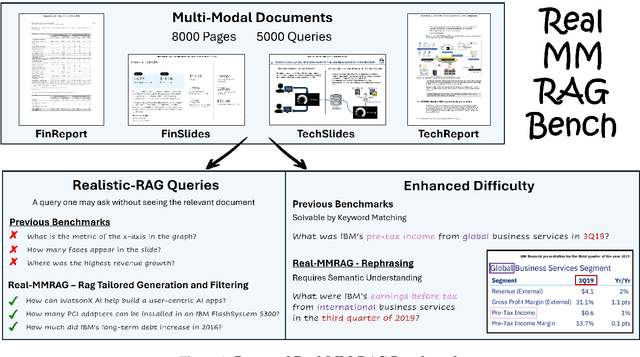
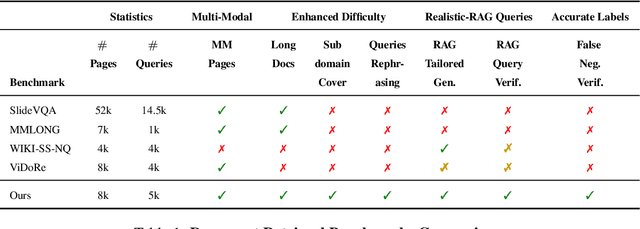

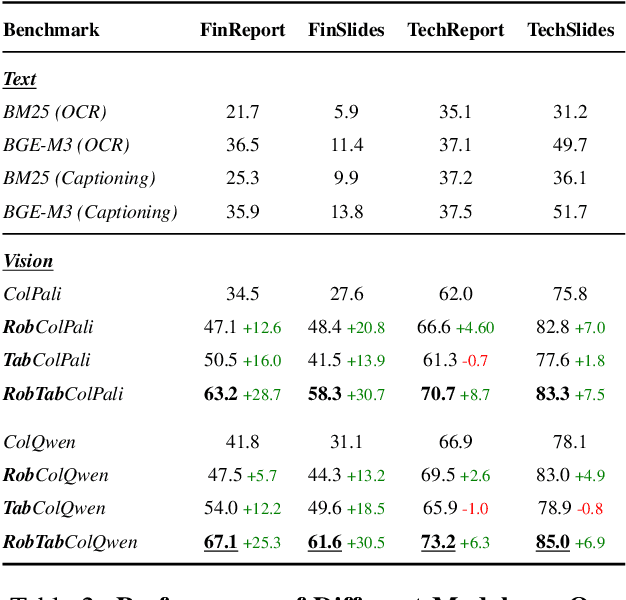
Accurate multi-modal document retrieval is crucial for Retrieval-Augmented Generation (RAG), yet existing benchmarks do not fully capture real-world challenges with their current design. We introduce REAL-MM-RAG, an automatically generated benchmark designed to address four key properties essential for real-world retrieval: (i) multi-modal documents, (ii) enhanced difficulty, (iii) Realistic-RAG queries and (iv) accurate labeling. Additionally, we propose a multi-difficulty-level scheme based on query rephrasing to evaluate models' semantic understanding beyond keyword matching. Our benchmark reveals significant model weaknesses, particularly in handling table-heavy documents and robustness to query rephrasing. To mitigate these shortcomings, we curate a rephrased training set and introduce a new finance-focused, table-heavy dataset. Fine-tuning on these datasets enables models to achieve state-of-the-art retrieval performance on REAL-MM-RAG benchmark. Our work offers a better way to evaluate and improve retrieval in multi-modal RAG systems while also providing training data and models that address current limitations.
KVP10k : A Comprehensive Dataset for Key-Value Pair Extraction in Business Documents
May 01, 2024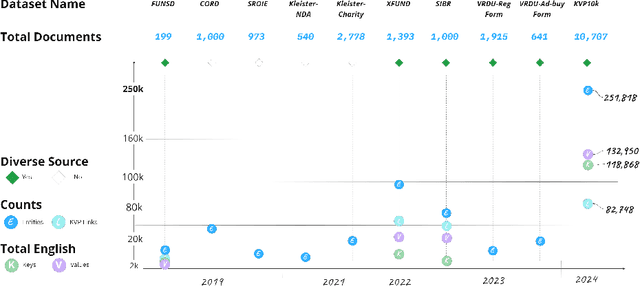
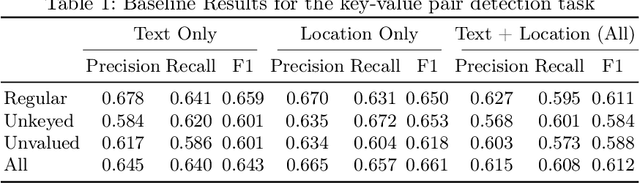
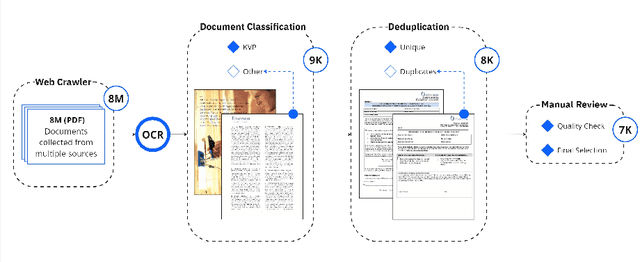

In recent years, the challenge of extracting information from business documents has emerged as a critical task, finding applications across numerous domains. This effort has attracted substantial interest from both industry and academy, highlighting its significance in the current technological landscape. Most datasets in this area are primarily focused on Key Information Extraction (KIE), where the extraction process revolves around extracting information using a specific, predefined set of keys. Unlike most existing datasets and benchmarks, our focus is on discovering key-value pairs (KVPs) without relying on predefined keys, navigating through an array of diverse templates and complex layouts. This task presents unique challenges, primarily due to the absence of comprehensive datasets and benchmarks tailored for non-predetermined KVP extraction. To address this gap, we introduce KVP10k , a new dataset and benchmark specifically designed for KVP extraction. The dataset contains 10707 richly annotated images. In our benchmark, we also introduce a new challenging task that combines elements of KIE as well as KVP in a single task. KVP10k sets itself apart with its extensive diversity in data and richly detailed annotations, paving the way for advancements in the field of information extraction from complex business documents.
BusiNet -- a Light and Fast Text Detection Network for Business Documents
Jul 04, 2022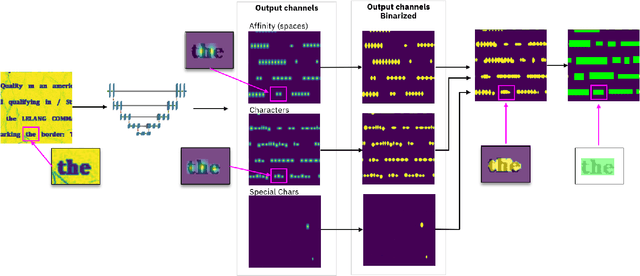
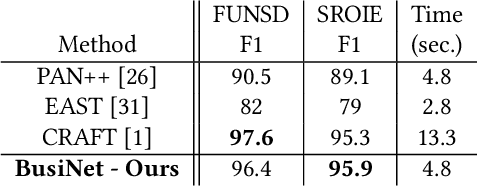

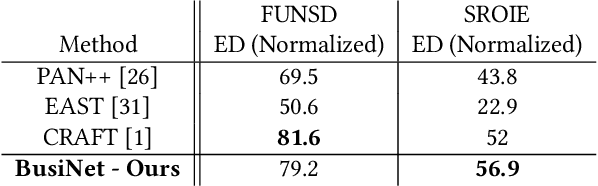
For digitizing or indexing physical documents, Optical Character Recognition (OCR), the process of extracting textual information from scanned documents, is a vital technology. When a document is visually damaged or contains non-textual elements, existing technologies can yield poor results, as erroneous detection results can greatly affect the quality of OCR. In this paper we present a detection network dubbed BusiNet aimed at OCR of business documents. Business documents often include sensitive information and as such they cannot be uploaded to a cloud service for OCR. BusiNet was designed to be fast and light so it could run locally preventing privacy issues. Furthermore, BusiNet is built to handle scanned document corruption and noise using a specialized synthetic dataset. The model is made robust to unseen noise by employing adversarial training strategies. We perform an evaluation on publicly available datasets demonstrating the usefulness and broad applicability of our model.