 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBusiNet -- a Light and Fast Text Detection Network for Business Documents
Jul 04, 2022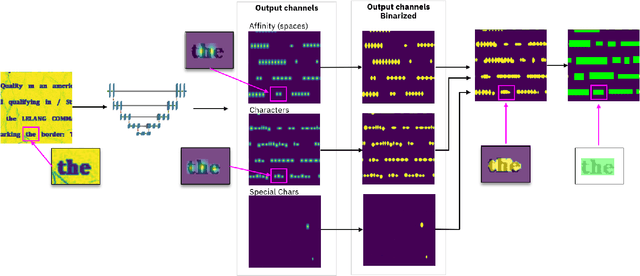
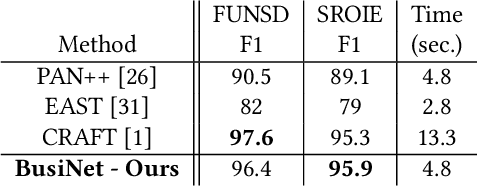

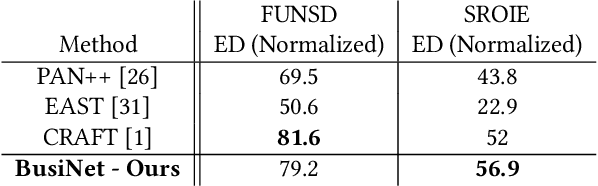
For digitizing or indexing physical documents, Optical Character Recognition (OCR), the process of extracting textual information from scanned documents, is a vital technology. When a document is visually damaged or contains non-textual elements, existing technologies can yield poor results, as erroneous detection results can greatly affect the quality of OCR. In this paper we present a detection network dubbed BusiNet aimed at OCR of business documents. Business documents often include sensitive information and as such they cannot be uploaded to a cloud service for OCR. BusiNet was designed to be fast and light so it could run locally preventing privacy issues. Furthermore, BusiNet is built to handle scanned document corruption and noise using a specialized synthetic dataset. The model is made robust to unseen noise by employing adversarial training strategies. We perform an evaluation on publicly available datasets demonstrating the usefulness and broad applicability of our model.
Detection Masking for Improved OCR on Noisy Documents
May 17, 2022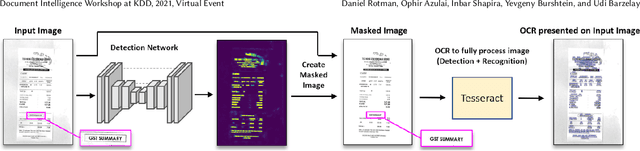
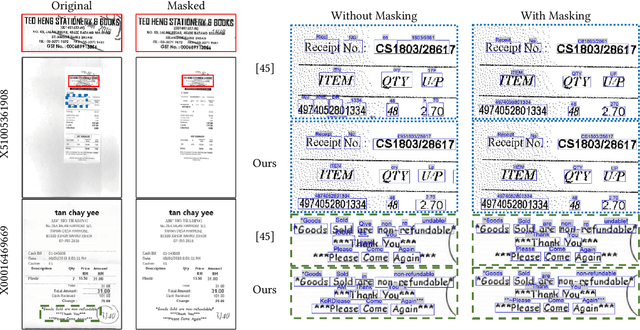

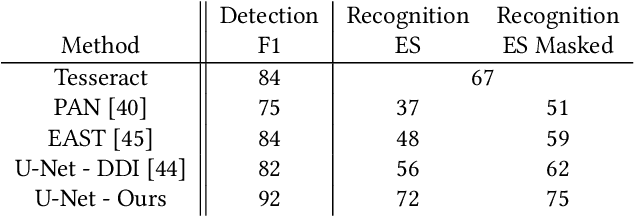
Optical Character Recognition (OCR), the task of extracting textual information from scanned documents is a vital and broadly used technology for digitizing and indexing physical documents. Existing technologies perform well for clean documents, but when the document is visually degraded, or when there are non-textual elements, OCR quality can be greatly impacted, specifically due to erroneous detections. In this paper we present an improved detection network with a masking system to improve the quality of OCR performed on documents. By filtering non-textual elements from the image we can utilize document-level OCR to incorporate contextual information to improve OCR results. We perform a unified evaluation on a publicly available dataset demonstrating the usefulness and broad applicability of our method. Additionally, we present and make publicly available our synthetic dataset with a unique hard-negative component specifically tuned to improve detection results, and evaluate the benefits that can be gained from its usage
Learnable Optimal Sequential Grouping for Video Scene Detection
May 17, 2022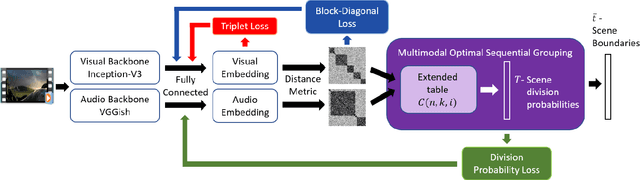
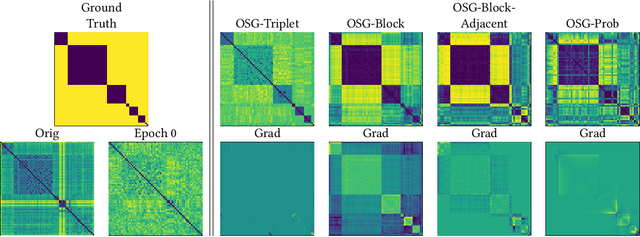
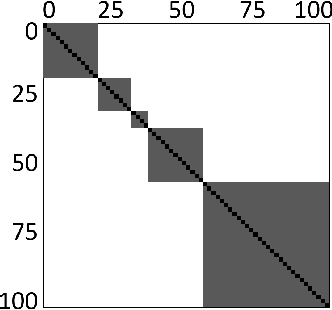
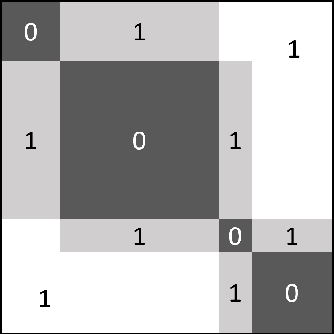
Video scene detection is the task of dividing videos into temporal semantic chapters. This is an important preliminary step before attempting to analyze heterogeneous video content. Recently, Optimal Sequential Grouping (OSG) was proposed as a powerful unsupervised solution to solve a formulation of the video scene detection problem. In this work, we extend the capabilities of OSG to the learning regime. By giving the capability to both learn from examples and leverage a robust optimization formulation, we can boost performance and enhance the versatility of the technology. We present a comprehensive analysis of incorporating OSG into deep learning neural networks under various configurations. These configurations include learning an embedding in a straight-forward manner, a tailored loss designed to guide the solution of OSG, and an integrated model where the learning is performed through the OSG pipeline. With thorough evaluation and analysis, we assess the benefits and behavior of the various configurations, and show that our learnable OSG approach exhibits desirable behavior and enhanced performance compared to the state of the art.
TAEN: Temporal Aware Embedding Network for Few-Shot Action Recognition
Apr 21, 2020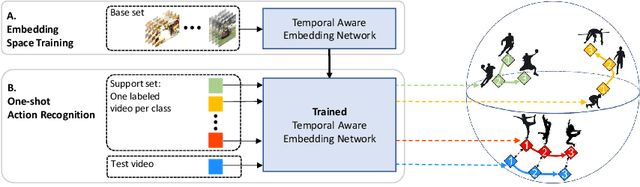
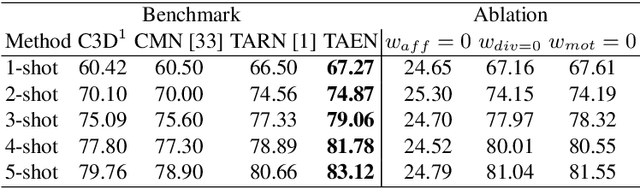
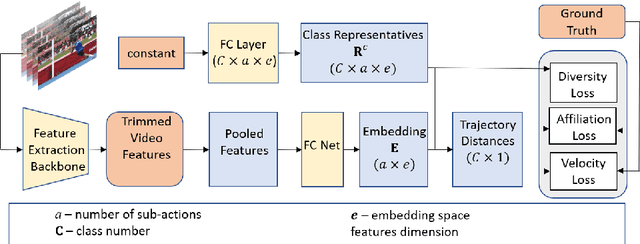
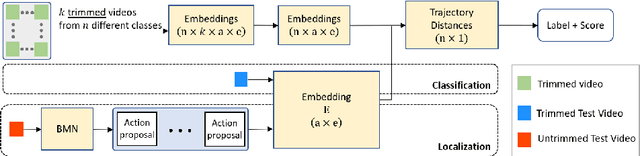
Classification of a new class entities requires collecting and annotating hundreds or thousands of samples that is often prohibitively time consuming and costly. Few-shot learning (FSL) suggests learning to classify new classes using just a few examples. Only a small number of studies address the challenge of using just a few labeled samples to learn a new spatio-temporal pattern such as videos. In this paper, we present a Temporal Aware Embedding Network (TAEN) for few-shot action recognition, that learns to represent actions, in a metric space as a trajectory, conveying both short term semantics and longer term connectivity between sub-actions. We demonstrate the effectiveness of TAEN on two few shot tasks, video classification and temporal action detection. We achieve state-of-the-art results on the Kinetics few-shot benchmark and on the ActivityNet 1.2 few-shot temporal action detection task. Code will be released upon acceptance of the paper.
Noise Estimation Using Density Estimation for Self-Supervised Multimodal Learning
Mar 06, 2020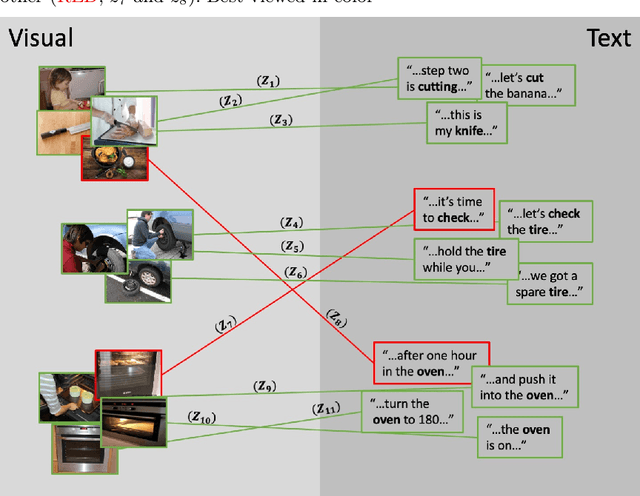
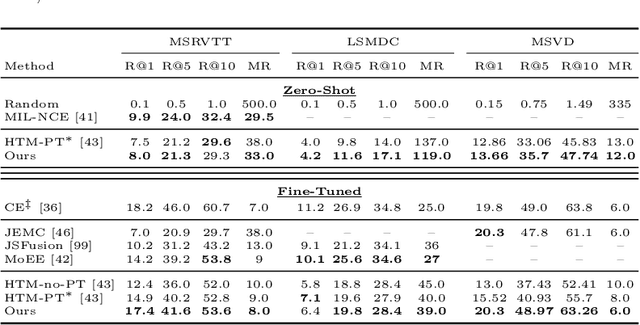
One of the key factors of enabling machine learning models to comprehend and solve real-world tasks is to leverage multimodal data. Unfortunately, annotation of multimodal data is challenging and expensive. Recently, self-supervised multimodal methods that combine vision and language were proposed to learn multimodal representations without annotation. However, these methods choose to ignore the presence of high levels of noise and thus yield sub-optimal results. In this work, we show that the problem of noise estimation for multimodal data can be reduced to a multimodal density estimation task. Using multimodal density estimation, we propose a noise estimation building block for multimodal representation learning that is based strictly on the inherent correlation between different modalities. We demonstrate how our noise estimation can be broadly integrated and achieves comparable results to state-of-the-art performance on five different benchmark datasets for two challenging multimodal tasks: Video Question Answering and Text-To-Video Retrieval.
ILS-SUMM: Iterated Local Search for Unsupervised Video Summarization
Dec 08, 2019
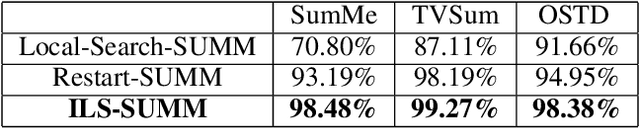

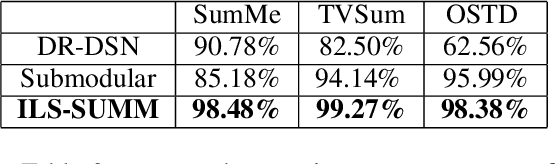
In recent years, there has been an increasing interest in building video summarization tools, where the goal is to automatically create a short summary of an input video that properly represents the original content. We consider shot-based video summarization where the summary consists of a subset of the video shots which can be of various lengths. A straightforward approach to maximize the representativeness of a subset of shots is by minimizing the total distance between shots and their nearest selected shots. We formulate the task of video summarization as an optimization problem with a knapsack-like constraint on the total summary duration. Previous studies have proposed greedy algorithms to solve this problem approximately, but no experiments were presented to measure the ability of these methods to obtain solutions with low total distance. Indeed, our experiments on video summarization datasets show that the success of current methods in obtaining results with low total distance still has much room for improvement. In this paper, we develop ILS-SUMM, a novel video summarization algorithm to solve the subset selection problem under the knapsack constraint. Our algorithm is based on the well-known metaheuristic optimization framework -- Iterated Local Search (ILS), known for its ability to avoid weak local minima and obtain a good near-global minimum. Extensive experiments show that our method finds solutions with significantly better total distance than previous methods. Moreover, to indicate the high scalability of ILS-SUMM, we introduce a new dataset consisting of videos of various lengths.