 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection Masking for Improved OCR on Noisy Documents
Paper and Code
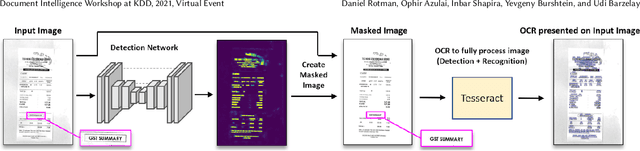
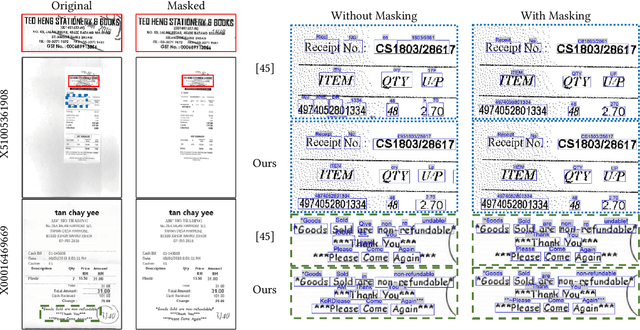

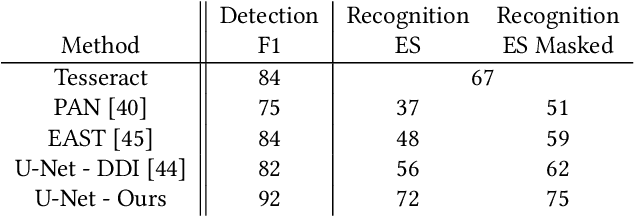
Optical Character Recognition (OCR), the task of extracting textual information from scanned documents is a vital and broadly used technology for digitizing and indexing physical documents. Existing technologies perform well for clean documents, but when the document is visually degraded, or when there are non-textual elements, OCR quality can be greatly impacted, specifically due to erroneous detections. In this paper we present an improved detection network with a masking system to improve the quality of OCR performed on documents. By filtering non-textual elements from the image we can utilize document-level OCR to incorporate contextual information to improve OCR results. We perform a unified evaluation on a publicly available dataset demonstrating the usefulness and broad applicability of our method. Additionally, we present and make publicly available our synthetic dataset with a unique hard-negative component specifically tuned to improve detection results, and evaluate the benefits that can be gained from its usage