 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Optimal Sequential Grouping for Video Scene Detection
Paper and Code
May 17, 2022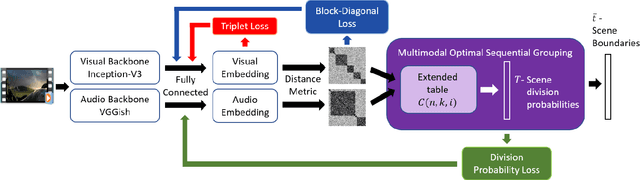
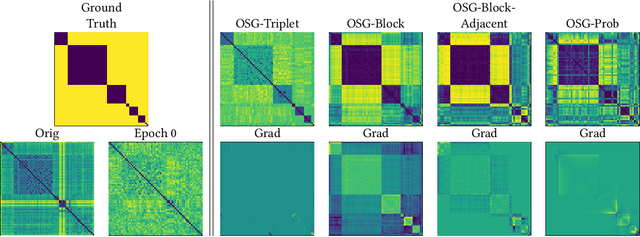
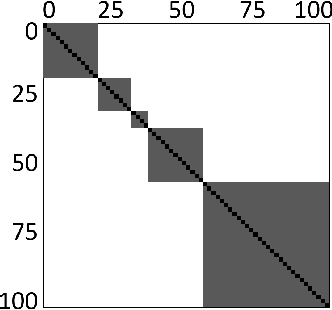
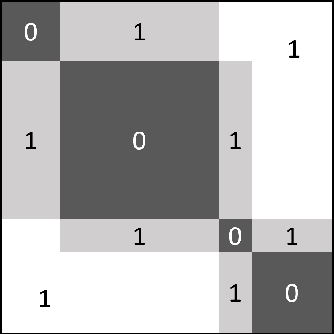
Video scene detection is the task of dividing videos into temporal semantic chapters. This is an important preliminary step before attempting to analyze heterogeneous video content. Recently, Optimal Sequential Grouping (OSG) was proposed as a powerful unsupervised solution to solve a formulation of the video scene detection problem. In this work, we extend the capabilities of OSG to the learning regime. By giving the capability to both learn from examples and leverage a robust optimization formulation, we can boost performance and enhance the versatility of the technology. We present a comprehensive analysis of incorporating OSG into deep learning neural networks under various configurations. These configurations include learning an embedding in a straight-forward manner, a tailored loss designed to guide the solution of OSG, and an integrated model where the learning is performed through the OSG pipeline. With thorough evaluation and analysis, we assess the benefits and behavior of the various configurations, and show that our learnable OSG approach exhibits desirable behavior and enhanced performance compared to the state of the art.