 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLASH-MAXSIM: IO-Aware Fused Kernels for Late-Interaction Scoring
May 28, 2026Late-interaction retrieval (ColBERT, ColPali) scores a query against a document with the MaxSim operator: for every query token, the maximum similarity over the document tokens, summed over query tokens. The standard implementation materializes the full query-token x document-token similarity tensor in GPU memory; for visual ColPali at 10K documents this tensor alone is 21 GB in FP16, created only to be reduced to one score per document and discarded. It exhausts a 40 GB GPU and bounds the achievable batch size in both inference and training. We present Flash-MaxSim, an IO-aware fused GPU kernel that computes exactly the same scores without ever materializing the tensor, by streaming query and document tiles through on-chip SRAM and folding the row-maximum reduction into the same pass. We extend the IO-aware principle through the training backward pass, an inverse-grid CSR construction that reuses the forward argmax for an atomic-free, destination-owned gradient reduction, and through INT8xINT8 quantization and variable-length (padding-free) scoring. Flash-MaxSim is up to 3.9x faster on an A100 (4.7x on an H100) than naive PyTorch at matched precision, uses up to 16x less inference memory and ~28x less training memory, unlocks corpus and batch sizes that exhaust PyTorch entirely, preserves the exact ranking (100% top-20 agreement with an FP32 reference)
REAL-MM-RAG: A Real-World Multi-Modal Retrieval Benchmark
Feb 17, 2025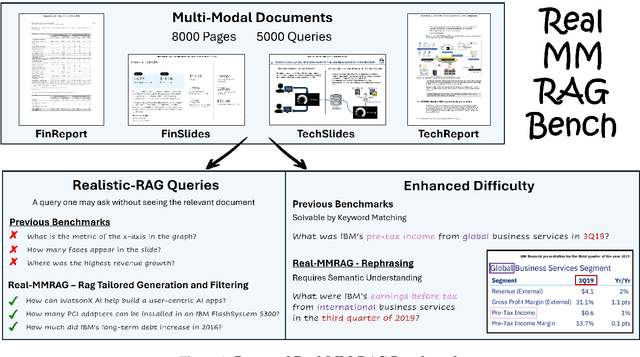
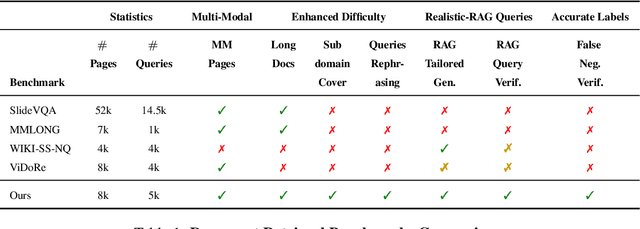

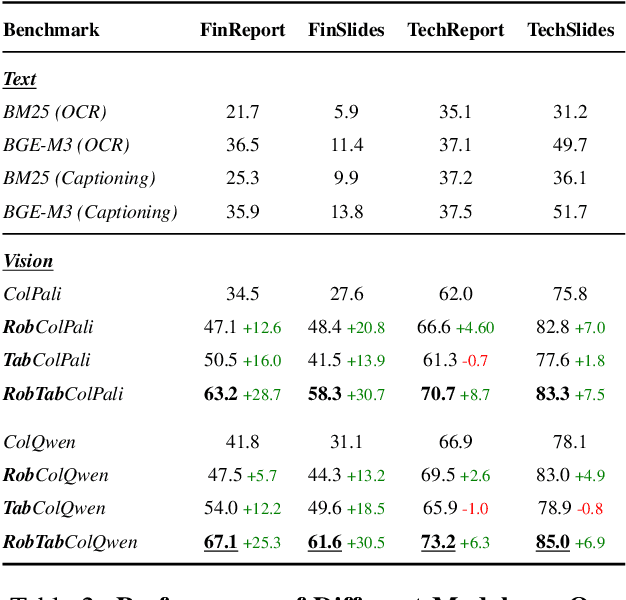
Accurate multi-modal document retrieval is crucial for Retrieval-Augmented Generation (RAG), yet existing benchmarks do not fully capture real-world challenges with their current design. We introduce REAL-MM-RAG, an automatically generated benchmark designed to address four key properties essential for real-world retrieval: (i) multi-modal documents, (ii) enhanced difficulty, (iii) Realistic-RAG queries and (iv) accurate labeling. Additionally, we propose a multi-difficulty-level scheme based on query rephrasing to evaluate models' semantic understanding beyond keyword matching. Our benchmark reveals significant model weaknesses, particularly in handling table-heavy documents and robustness to query rephrasing. To mitigate these shortcomings, we curate a rephrased training set and introduce a new finance-focused, table-heavy dataset. Fine-tuning on these datasets enables models to achieve state-of-the-art retrieval performance on REAL-MM-RAG benchmark. Our work offers a better way to evaluate and improve retrieval in multi-modal RAG systems while also providing training data and models that address current limitations.
KVP10k : A Comprehensive Dataset for Key-Value Pair Extraction in Business Documents
May 01, 2024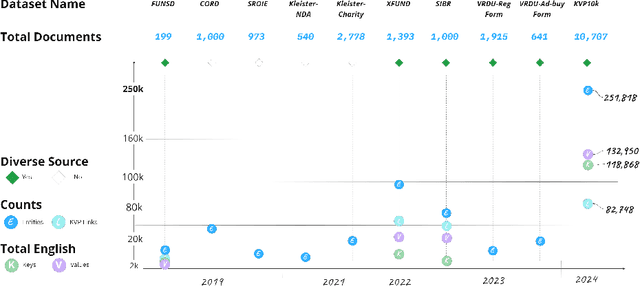
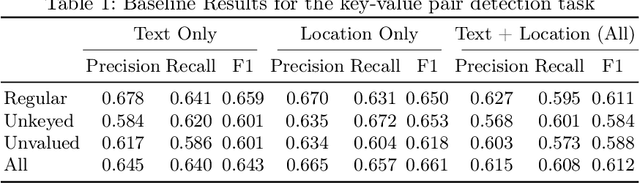
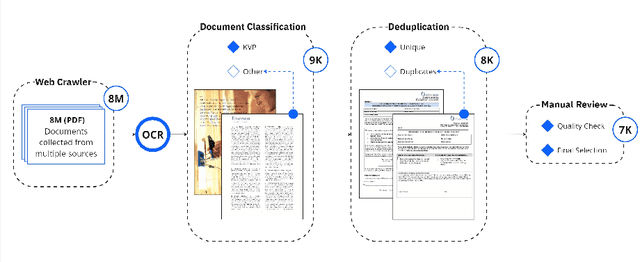

In recent years, the challenge of extracting information from business documents has emerged as a critical task, finding applications across numerous domains. This effort has attracted substantial interest from both industry and academy, highlighting its significance in the current technological landscape. Most datasets in this area are primarily focused on Key Information Extraction (KIE), where the extraction process revolves around extracting information using a specific, predefined set of keys. Unlike most existing datasets and benchmarks, our focus is on discovering key-value pairs (KVPs) without relying on predefined keys, navigating through an array of diverse templates and complex layouts. This task presents unique challenges, primarily due to the absence of comprehensive datasets and benchmarks tailored for non-predetermined KVP extraction. To address this gap, we introduce KVP10k , a new dataset and benchmark specifically designed for KVP extraction. The dataset contains 10707 richly annotated images. In our benchmark, we also introduce a new challenging task that combines elements of KIE as well as KVP in a single task. KVP10k sets itself apart with its extensive diversity in data and richly detailed annotations, paving the way for advancements in the field of information extraction from complex business documents.
CHARTER: heatmap-based multi-type chart data extraction
Nov 28, 2021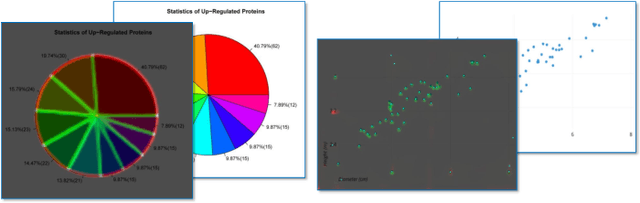
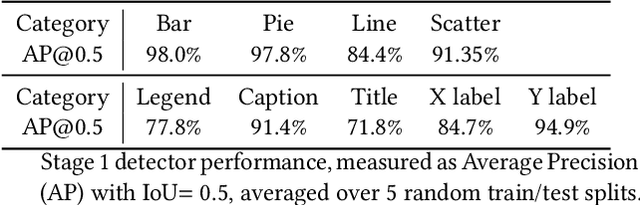
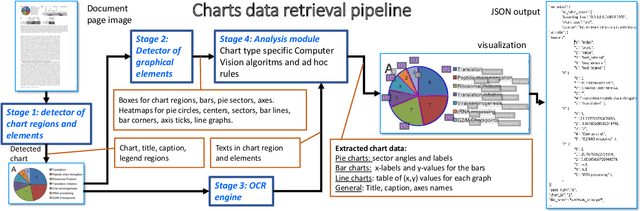
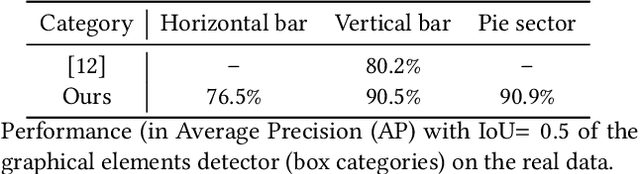
The digital conversion of information stored in documents is a great source of knowledge. In contrast to the documents text, the conversion of the embedded documents graphics, such as charts and plots, has been much less explored. We present a method and a system for end-to-end conversion of document charts into machine readable tabular data format, which can be easily stored and analyzed in the digital domain. Our approach extracts and analyses charts along with their graphical elements and supporting structures such as legends, axes, titles, and captions. Our detection system is based on neural networks, trained solely on synthetic data, eliminating the limiting factor of data collection. As opposed to previous methods, which detect graphical elements using bounding-boxes, our networks feature auxiliary domain specific heatmaps prediction enabling the precise detection of pie charts, line and scatter plots which do not fit the rectangular bounding-box presumption. Qualitative and quantitative results show high robustness and precision, improving upon previous works on popular benchmarks
* Joseph Shtok, Sivan Harary and Leonid Karlinsky had equal contribution