 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Deficient Coverage in Colonoscopies
Jan 26, 2020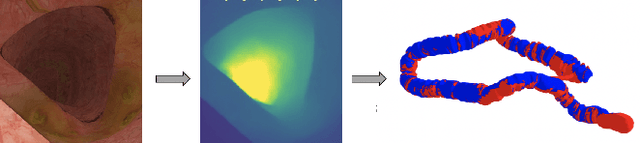
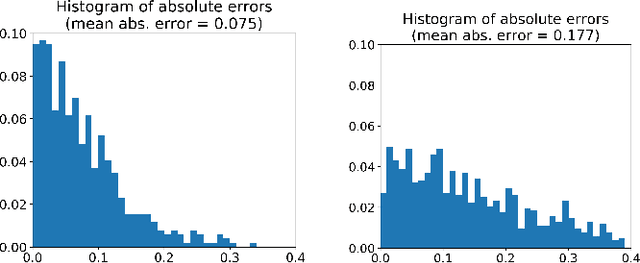
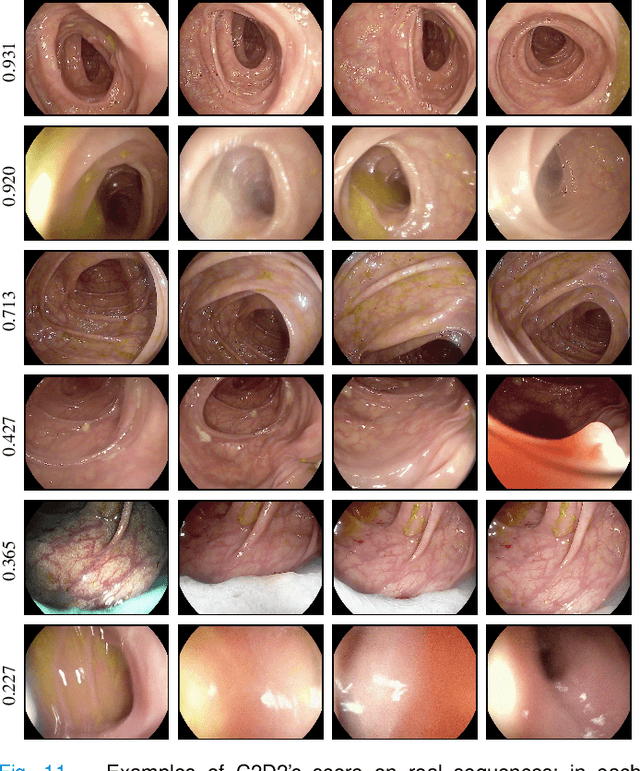
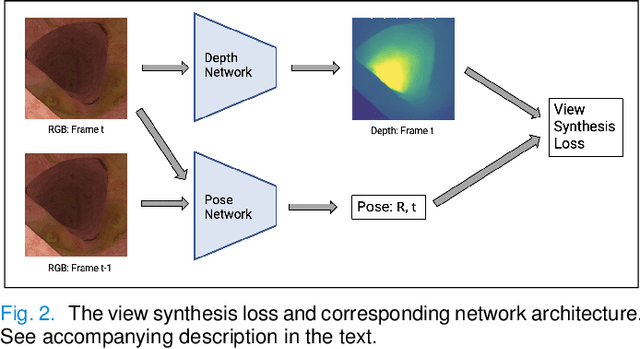
Colorectal Cancer (CRC) is a global health problem, resulting in 900K deaths per year. Colonoscopy is the tool of choice for preventing CRC, by detecting polyps before they become cancerous, and removing them. However, colonoscopy is hampered by the fact that endoscopists routinely miss an average of 22-28% of polyps. While some of these missed polyps appear in the endoscopist's field of view, others are missed simply because of substandard coverage of the procedure, i.e. not all of the colon is seen. This paper attempts to rectify the problem of substandard coverage in colonoscopy through the introduction of the C2D2 (Colonoscopy Coverage Deficiency via Depth) algorithm which detects deficient coverage, and can thereby alert the endoscopist to revisit a given area. More specifically, C2D2 consists of two separate algorithms: the first performs depth estimation of the colon given an ordinary RGB video stream; while the second computes coverage given these depth estimates. Rather than compute coverage for the entire colon, our algorithm computes coverage locally, on a segment-by-segment basis; C2D2 can then indicate in real-time whether a particular area of the colon has suffered from deficient coverage, and if so the endoscopist can return to that area. Our coverage algorithm is the first such algorithm to be evaluated in a large-scale way; while our depth estimation technique is the first calibration-free unsupervised method applied to colonoscopies. The C2D2 algorithm achieves state of the art results in the detection of deficient coverage: it is 2.4 times more accurate than human experts.
LaSO: Label-Set Operations networks for multi-label few-shot learning
Feb 26, 2019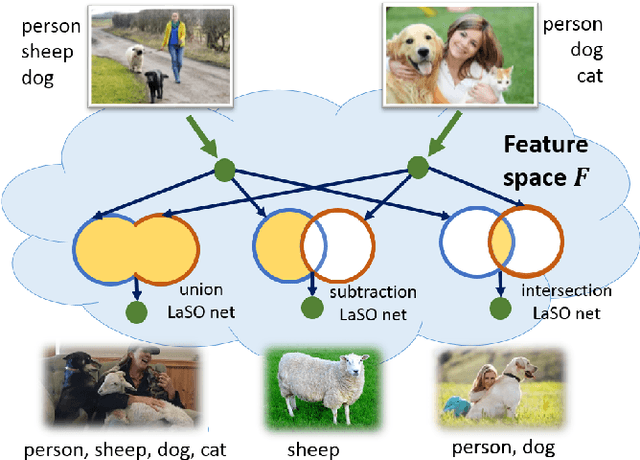
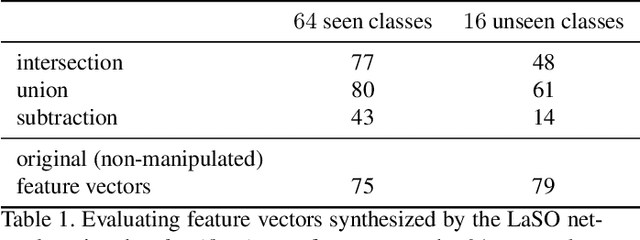

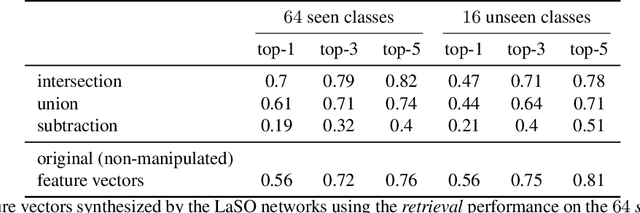
Example synthesis is one of the leading methods to tackle the problem of few-shot learning, where only a small number of samples per class are available. However, current synthesis approaches only address the scenario of a single category label per image. In this work, we propose a novel technique for synthesizing samples with multiple labels for the (yet unhandled) multi-label few-shot classification scenario. We propose to combine pairs of given examples in feature space, so that the resulting synthesized feature vectors will correspond to examples whose label sets are obtained through certain set operations on the label sets of the corresponding input pairs. Thus, our method is capable of producing a sample containing the intersection, union or set-difference of labels present in two input samples. As we show, these set operations generalize to labels unseen during training. This enables performing augmentation on examples of novel categories, thus, facilitating multi-label few-shot classifier learning. We conduct numerous experiments showing promising results for the label-set manipulation capabilities of the proposed approach, both directly (using the classification and retrieval metrics), and in the context of performing data augmentation for multi-label few-shot learning. We propose a benchmark for this new and challenging task and show that our method compares favorably to all the common baselines.
In-situ multi-scattering tomography
Dec 07, 2015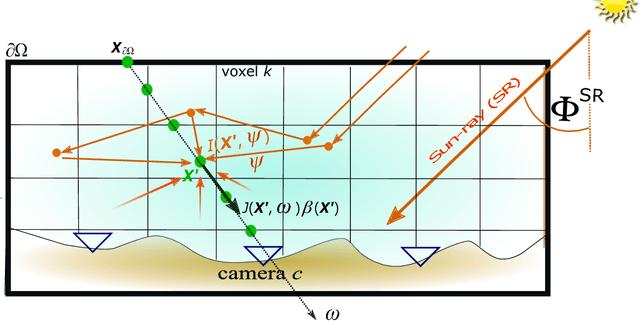
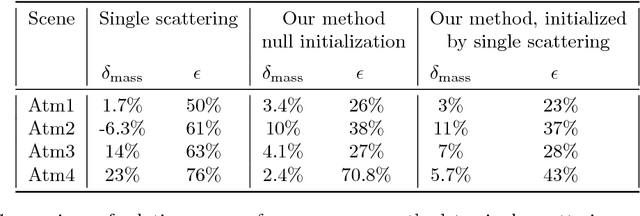
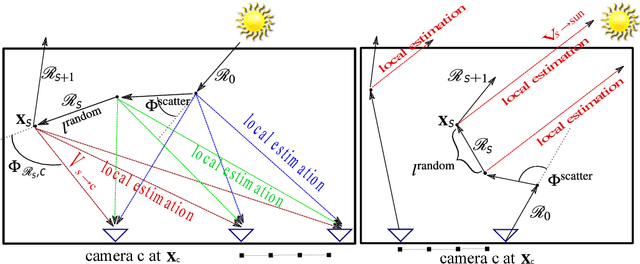

To recover the three dimensional (3D) volumetric distribution of matter in an object, images of the object are captured from multiple directions and locations. Using these images tomographic computations extract the distribution. In highly scattering media and constrained, natural irradiance, tomography must explicitly account for off-axis scattering. Furthermore, the tomographic model and recovery must function when imaging is done in-situ, as occurs in medical imaging and ground-based atmospheric sensing. We formulate tomography that handles arbitrary orders of scattering, using a monte-carlo model. Moreover, the model is highly parallelizable in our formulation. This enables large scale rendering and recovery of volumetric scenes having a large number of variables. We solve stability and conditioning problems that stem from radiative transfer (RT) modeling in-situ.