 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's All in the Head: Representation Knowledge Distillation through Classifier Sharing
Jan 18, 2022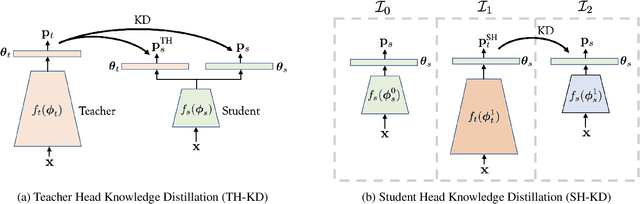
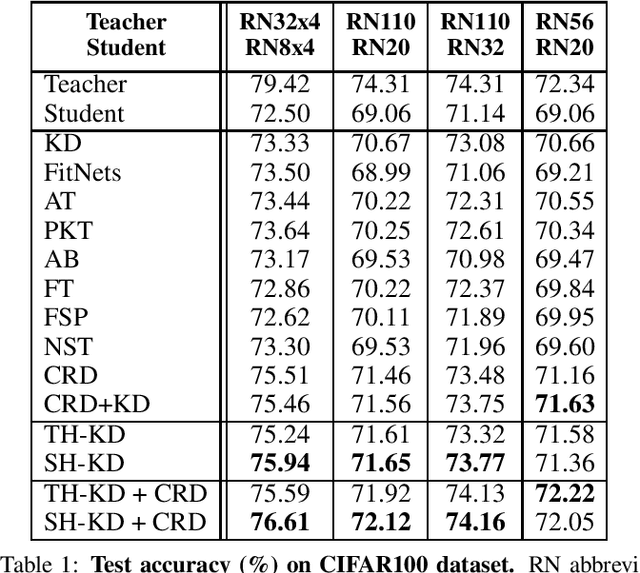
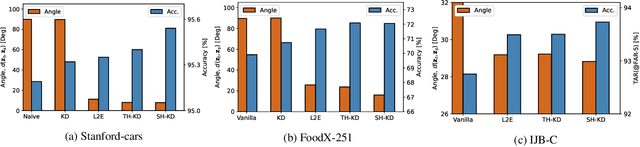
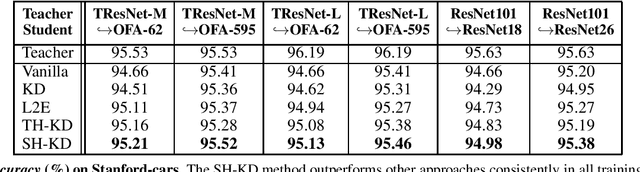
Representation knowledge distillation aims at transferring rich information from one model to another. Current approaches for representation distillation mainly focus on the direct minimization of distance metrics between the models' embedding vectors. Such direct methods may be limited in transferring high-order dependencies embedded in the representation vectors, or in handling the capacity gap between the teacher and student models. In this paper, we introduce two approaches for enhancing representation distillation using classifier sharing between the teacher and student. Specifically, we first show that connecting the teacher's classifier to the student backbone and freezing its parameters is beneficial for the process of representation distillation, yielding consistent improvements. Then, we propose an alternative approach that asks to tailor the teacher model to a student with limited capacity. This approach competes with and in some cases surpasses the first method. Via extensive experiments and analysis, we show the effectiveness of the proposed methods on various datasets and tasks, including image classification, fine-grained classification, and face verification. For example, we achieve state-of-the-art performance for face verification on the IJB-C dataset for a MobileFaceNet model: TAR@(FAR=1e-5)=93.7\%. Code is available at https://github.com/Alibaba-MIIL/HeadSharingKD.