 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIHF-Harmony: Multi-Modality Magnetic Resonance Images Harmonization using Invertible Hierarchy Flow Model
Feb 25, 2026Retrospective MRI harmonization is limited by poor scalability across modalities and reliance on traveling subject datasets. To address these challenges, we introduce IHF-Harmony, a unified invertible hierarchy flow framework for multi-modality harmonization using unpaired data. By decomposing the translation process into reversible feature transformations, IHF-Harmony guarantees bijective mapping and lossless reconstruction to prevent anatomical distortion. Specifically, an invertible hierarchy flow (IHF) performs hierarchical subtractive coupling to progressively remove artefact-related features, while an artefact-aware normalization (AAN) employs anatomy-fixed feature modulation to accurately transfer target characteristics. Combined with anatomy and artefact consistency loss objectives, IHF-Harmony achieves high-fidelity harmonization that retains source anatomy. Experiments across multiple MRI modalities demonstrate that IHF-Harmony outperforms existing methods in both anatomical fidelity and downstream task performance, facilitating robust harmonization for large-scale multi-site imaging studies. Code will be released upon acceptance.
ReactDiff: Latent Diffusion for Facial Reaction Generation
May 20, 2025Given the audio-visual clip of the speaker, facial reaction generation aims to predict the listener's facial reactions. The challenge lies in capturing the relevance between video and audio while balancing appropriateness, realism, and diversity. While prior works have mostly focused on uni-modal inputs or simplified reaction mappings, recent approaches such as PerFRDiff have explored multi-modal inputs and the one-to-many nature of appropriate reaction mappings. In this work, we propose the Facial Reaction Diffusion (ReactDiff) framework that uniquely integrates a Multi-Modality Transformer with conditional diffusion in the latent space for enhanced reaction generation. Unlike existing methods, ReactDiff leverages intra- and inter-class attention for fine-grained multi-modal interaction, while the latent diffusion process between the encoder and decoder enables diverse yet contextually appropriate outputs. Experimental results demonstrate that ReactDiff significantly outperforms existing approaches, achieving a facial reaction correlation of 0.26 and diversity score of 0.094 while maintaining competitive realism. The code is open-sourced at \href{https://github.com/Hunan-Tiger/ReactDiff}{github}.
UniCAD: Efficient and Extendable Architecture for Multi-Task Computer-Aided Diagnosis System
May 15, 2025The growing complexity and scale of visual model pre-training have made developing and deploying multi-task computer-aided diagnosis (CAD) systems increasingly challenging and resource-intensive. Furthermore, the medical imaging community lacks an open-source CAD platform to enable the rapid creation of efficient and extendable diagnostic models. To address these issues, we propose UniCAD, a unified architecture that leverages the robust capabilities of pre-trained vision foundation models to seamlessly handle both 2D and 3D medical images while requiring only minimal task-specific parameters. UniCAD introduces two key innovations: (1) Efficiency: A low-rank adaptation strategy is employed to adapt a pre-trained visual model to the medical image domain, achieving performance on par with fully fine-tuned counterparts while introducing only 0.17% trainable parameters. (2) Plug-and-Play: A modular architecture that combines a frozen foundation model with multiple plug-and-play experts, enabling diverse tasks and seamless functionality expansion. Building on this unified CAD architecture, we establish an open-source platform where researchers can share and access lightweight CAD experts, fostering a more equitable and efficient research ecosystem. Comprehensive experiments across 12 diverse medical datasets demonstrate that UniCAD consistently outperforms existing methods in both accuracy and deployment efficiency. The source code and project page are available at https://mii-laboratory.github.io/UniCAD/.
Med-LEGO: Editing and Adapting toward Generalist Medical Image Diagnosis
Mar 03, 2025


The adoption of visual foundation models has become a common practice in computer-aided diagnosis (CAD). While these foundation models provide a viable solution for creating generalist medical AI, privacy concerns make it difficult to pre-train or continuously update such models across multiple domains and datasets, leading many studies to focus on specialist models. To address this challenge, we propose Med-LEGO, a training-free framework that enables the seamless integration or updating of a generalist CAD model by combining multiple specialist models, similar to assembling LEGO bricks. Med-LEGO enhances LoRA (low-rank adaptation) by incorporating singular value decomposition (SVD) to efficiently capture the domain expertise of each specialist model with minimal additional parameters. By combining these adapted weights through simple operations, Med-LEGO allows for the easy integration or modification of specific diagnostic capabilities without the need for original data or retraining. Finally, the combined model can be further adapted to new diagnostic tasks, making it a versatile generalist model. Our extensive experiments demonstrate that Med-LEGO outperforms existing methods in both cross-domain and in-domain medical tasks while using only 0.18% of full model parameters. These merged models show better convergence and generalization to new tasks, providing an effective path toward generalist medical AI.
MITracker: Multi-View Integration for Visual Object Tracking
Feb 27, 2025Multi-view object tracking (MVOT) offers promising solutions to challenges such as occlusion and target loss, which are common in traditional single-view tracking. However, progress has been limited by the lack of comprehensive multi-view datasets and effective cross-view integration methods. To overcome these limitations, we compiled a Multi-View object Tracking (MVTrack) dataset of 234K high-quality annotated frames featuring 27 distinct objects across various scenes. In conjunction with this dataset, we introduce a novel MVOT method, Multi-View Integration Tracker (MITracker), to efficiently integrate multi-view object features and provide stable tracking outcomes. MITracker can track any object in video frames of arbitrary length from arbitrary viewpoints. The key advancements of our method over traditional single-view approaches come from two aspects: (1) MITracker transforms 2D image features into a 3D feature volume and compresses it into a bird's eye view (BEV) plane, facilitating inter-view information fusion; (2) we propose an attention mechanism that leverages geometric information from fused 3D feature volume to refine the tracking results at each view. MITracker outperforms existing methods on the MVTrack and GMTD datasets, achieving state-of-the-art performance. The code and the new dataset will be available at https://mii-laboratory.github.io/MITracker/.
Inter-slice Super-resolution of Magnetic Resonance Images by Pre-training and Self-supervised Fine-tuning
Jun 10, 2024



In clinical practice, 2D magnetic resonance (MR) sequences are widely adopted. While individual 2D slices can be stacked to form a 3D volume, the relatively large slice spacing can pose challenges for both image visualization and subsequent analysis tasks, which often require isotropic voxel spacing. To reduce slice spacing, deep-learning-based super-resolution techniques are widely investigated. However, most current solutions require a substantial number of paired high-resolution and low-resolution images for supervised training, which are typically unavailable in real-world scenarios. In this work, we propose a self-supervised super-resolution framework for inter-slice super-resolution of MR images. Our framework is first featured by pre-training on video dataset, as temporal correlation of videos is found beneficial for modeling the spatial relation among MR slices. Then, we use public high-quality MR dataset to fine-tune our pre-trained model, for enhancing awareness of our model to medical data. Finally, given a target dataset at hand, we utilize self-supervised fine-tuning to further ensure our model works well with user-specific super-resolution tasks. The proposed method demonstrates superior performance compared to other self-supervised methods and also holds the potential to benefit various downstream applications.
MUC: Mixture of Uncalibrated Cameras for Robust 3D Human Body Reconstruction
Mar 08, 2024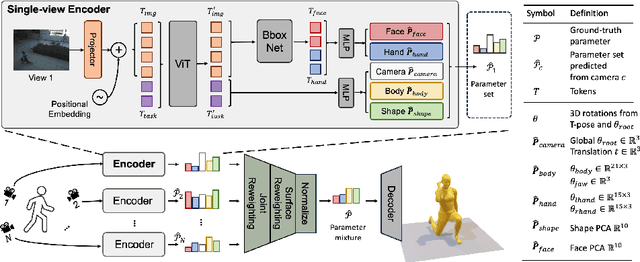
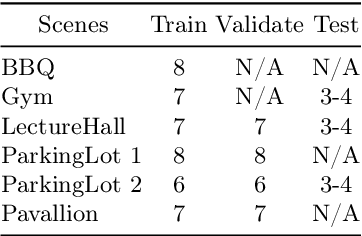
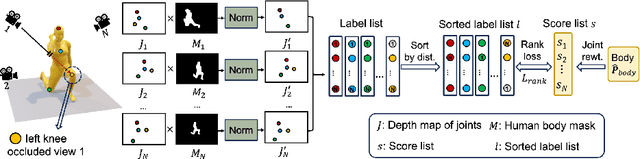

Multiple cameras can provide multi-view video coverage of a person. It is necessary to fuse multi-view data, e.g., for subsequent behavioral analysis, while such fusion often relies on calibration of cameras in traditional solutions. However, it is non-trivial to calibrate multiple cameras. In this work, we propose a method to reconstruct 3D human body from multiple uncalibrated camera views. First, we adopt a pre-trained human body encoder to process each individual camera view, such that human body models and parameters can be reconstructed for each view. Next, instead of simply averaging models across views, we train a network to determine the weights of individual views for their fusion, based on the parameters estimated for joints and hands of human body as well as camera positions. Further, we turn to the mesh surface of human body for dynamic fusion, such that facial expression can be seamlessly integrated into the model of human body. Our method has demonstrated superior performance in reconstructing human body upon two public datasets. More importantly, our method can flexibly support ad-hoc deployment of an arbitrary number of cameras, which has significant potential in related applications. We will release source code upon acceptance of the paper.
MeLo: Low-rank Adaptation is Better than Fine-tuning for Medical Image Diagnosis
Nov 14, 2023The common practice in developing computer-aided diagnosis (CAD) models based on transformer architectures usually involves fine-tuning from ImageNet pre-trained weights. However, with recent advances in large-scale pre-training and the practice of scaling laws, Vision Transformers (ViT) have become much larger and less accessible to medical imaging communities. Additionally, in real-world scenarios, the deployments of multiple CAD models can be troublesome due to problems such as limited storage space and time-consuming model switching. To address these challenges, we propose a new method MeLo (Medical image Low-rank adaptation), which enables the development of a single CAD model for multiple clinical tasks in a lightweight manner. It adopts low-rank adaptation instead of resource-demanding fine-tuning. By fixing the weight of ViT models and only adding small low-rank plug-ins, we achieve competitive results on various diagnosis tasks across different imaging modalities using only a few trainable parameters. Specifically, our proposed method achieves comparable performance to fully fine-tuned ViT models on four distinct medical imaging datasets using about 0.17% trainable parameters. Moreover, MeLo adds only about 0.5MB of storage space and allows for extremely fast model switching in deployment and inference. Our source code and pre-trained weights are available on our website (https://absterzhu.github.io/melo.github.io/).
ChatCAD+: Towards a Universal and Reliable Interactive CAD using LLMs
May 26, 2023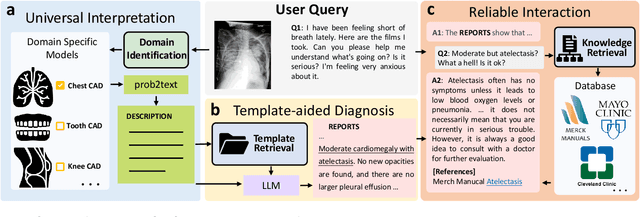
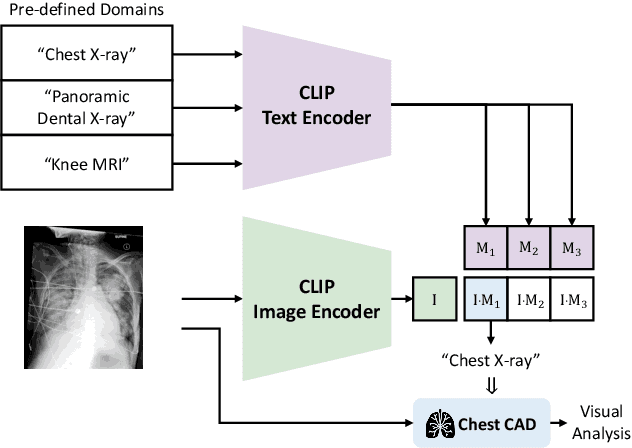
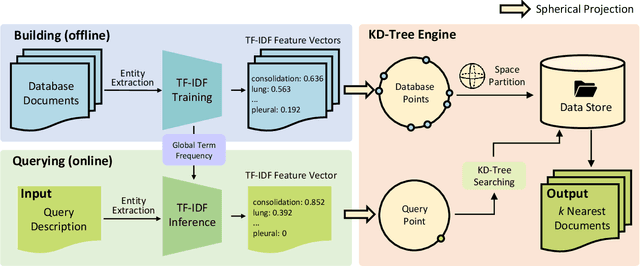
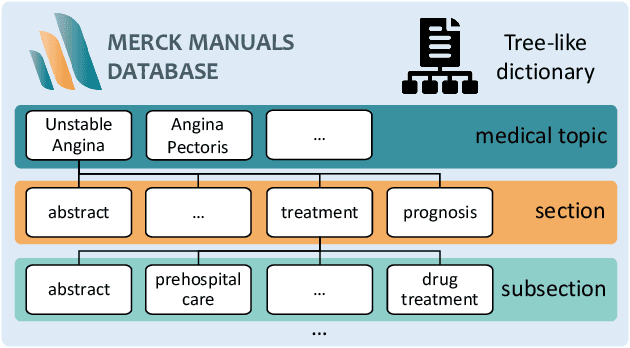
The potential of integrating Computer-Assisted Diagnosis (CAD) with Large Language Models (LLMs) in clinical applications, particularly in digital family doctor and clinic assistant roles, shows promise. However, existing works have limitations in terms of reliability, effectiveness, and their narrow applicability to specific image domains, which restricts their overall processing capabilities. Moreover, the mismatch in writing style between LLMs and radiologists undermines their practical utility. To address these challenges, we present ChatCAD+, an interactive CAD system that is universal, reliable, and capable of handling medical images from diverse domains. ChatCAD+ utilizes current information obtained from reputable medical websites to offer precise medical advice. Additionally, it incorporates a template retrieval system that emulates real-world diagnostic reporting, thereby improving its seamless integration into existing clinical workflows. The source code is available at https://github.com/zhaozh10/ChatCAD. The online demo will be available soon.
DoctorGLM: Fine-tuning your Chinese Doctor is not a Herculean Task
Apr 17, 2023



The recent progress of large language models (LLMs), including ChatGPT and GPT-4, in comprehending and responding to human instructions has been remarkable. Nevertheless, these models typically perform better in English and have not been explicitly trained for the medical domain, resulting in suboptimal precision in diagnoses, drug recommendations, and other medical advice. Additionally, training and deploying a dialogue model is still believed to be impossible for hospitals, hindering the promotion of LLMs. To tackle these challenges, we have collected databases of medical dialogues in Chinese with ChatGPT's help and adopted several techniques to train an easy-deploy LLM. Remarkably, we were able to fine-tune the ChatGLM-6B on a single A100 80G in 13 hours, which means having a healthcare-purpose LLM can be very affordable. DoctorGLM is currently an early-stage engineering attempt and contain various mistakes. We are sharing it with the broader community to invite feedback and suggestions to improve its healthcare-focused capabilities: https://github.com/xionghonglin/DoctorGLM.