 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECG-Chat: A Large ECG-Language Model for Cardiac Disease Diagnosis
Aug 16, 2024
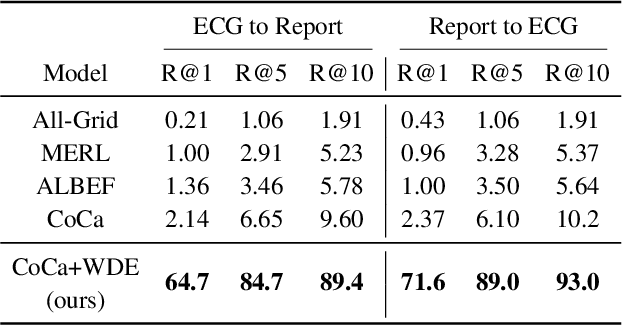
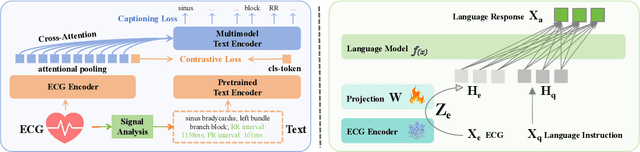
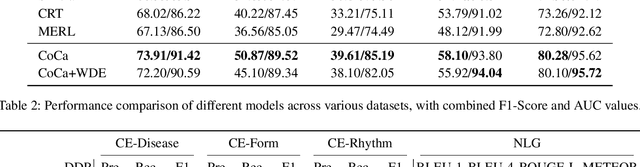
The success of Multimodal Large Language Models (MLLMs) in the medical auxiliary field shows great potential, allowing patients to engage in conversations using physiological signal data. However, general MLLMs perform poorly in cardiac disease diagnosis, particularly in the integration of ECG data analysis and long-text medical report generation, mainly due to the complexity of ECG data analysis and the gap between text and ECG signal modalities. Additionally, models often exhibit severe stability deficiencies in long-text generation due to the lack of precise knowledge strongly related to user queries. To address these issues, we propose ECG-Chat, the first multitask MLLMs focused on ECG medical report generation, providing multimodal conversational capabilities based on cardiology knowledge. We propose a contrastive learning approach that integrates ECG waveform data with text reports, aligning ECG features with reports in a fine-grained manner. This method also results in an ECG encoder that excels in zero-shot report retrieval tasks. Additionally, expanding existing datasets, we constructed a 19k ECG diagnosis dataset and a 25k multi-turn dialogue dataset for training and fine-tuning ECG-Chat, which provides professional diagnostic and conversational capabilities. Furthermore, ECG-Chat can generate comprehensive ECG analysis reports through an automated LaTeX generation pipeline. We established a benchmark for the ECG report generation task and tested our model on multiple baselines. ECG-Chat achieved the best performance in classification, retrieval, multimodal dialogue, and medical report generation tasks. Our report template design has also been widely recognized by medical practitioners.
DoctorGLM: Fine-tuning your Chinese Doctor is not a Herculean Task
Apr 17, 2023



The recent progress of large language models (LLMs), including ChatGPT and GPT-4, in comprehending and responding to human instructions has been remarkable. Nevertheless, these models typically perform better in English and have not been explicitly trained for the medical domain, resulting in suboptimal precision in diagnoses, drug recommendations, and other medical advice. Additionally, training and deploying a dialogue model is still believed to be impossible for hospitals, hindering the promotion of LLMs. To tackle these challenges, we have collected databases of medical dialogues in Chinese with ChatGPT's help and adopted several techniques to train an easy-deploy LLM. Remarkably, we were able to fine-tune the ChatGLM-6B on a single A100 80G in 13 hours, which means having a healthcare-purpose LLM can be very affordable. DoctorGLM is currently an early-stage engineering attempt and contain various mistakes. We are sharing it with the broader community to invite feedback and suggestions to improve its healthcare-focused capabilities: https://github.com/xionghonglin/DoctorGLM.
PGDP5K: A Diagram Parsing Dataset for Plane Geometry Problems
May 20, 2022
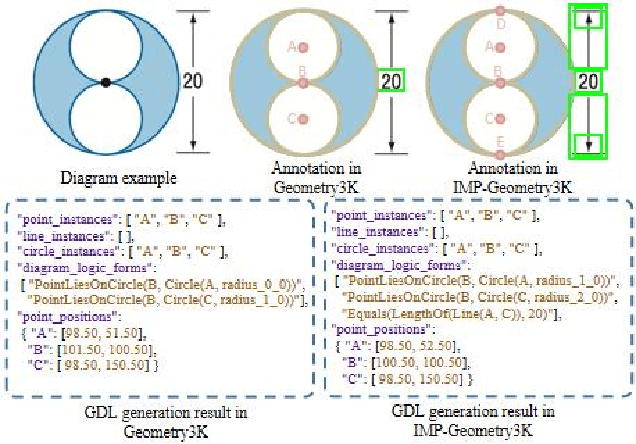
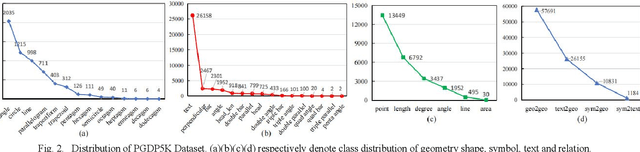
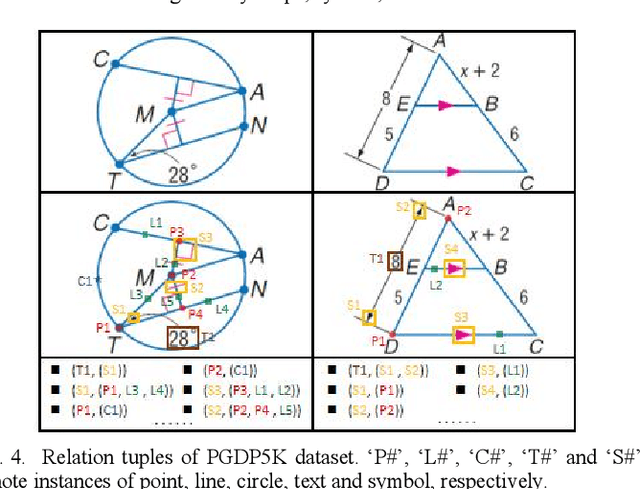
Diagram parsing is an important foundation for geometry problem solving, attracting increasing attention in the field of intelligent education and document image understanding. Due to the complex layout and between-primitive relationship, plane geometry diagram parsing (PGDP) is still a challenging task deserving further research and exploration. An appropriate dataset is critical for the research of PGDP. Although some datasets with rough annotations have been proposed to solve geometric problems, they are either small in scale or not publicly available. The rough annotations also make them not very useful. Thus, we propose a new large-scale geometry diagram dataset named PGDP5K and a novel annotation method. Our dataset consists of 5000 diagram samples composed of 16 shapes, covering 5 positional relations, 22 symbol types and 6 text types. Different from previous datasets, our PGDP5K dataset is labeled with more fine-grained annotations at primitive level, including primitive classes, locations and relationships. What is more, combined with above annotations and geometric prior knowledge, it can generate intelligible geometric propositions automatically and uniquely. We performed experiments on PGDP5K and IMP-Geometry3K datasets reveal that the state-of-the-art (SOTA) method achieves only 66.07% F1 value. This shows that PGDP5K presents a challenge for future research. Our dataset is available at http://www.nlpr.ia.ac.cn/databases/CASIA-PGDP5K/.