 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECG-Chat: A Large ECG-Language Model for Cardiac Disease Diagnosis
Aug 16, 2024
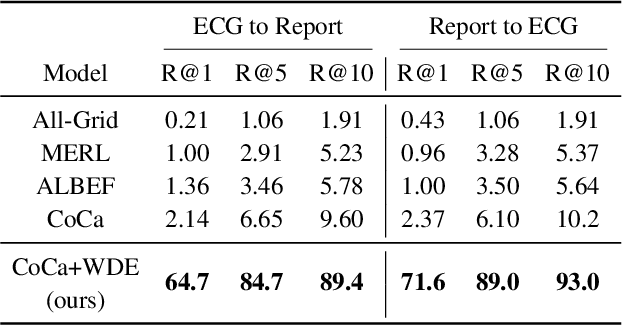
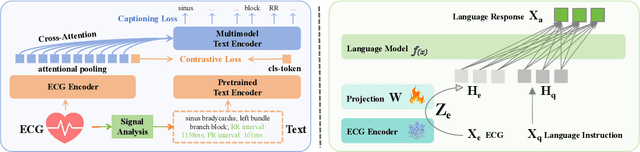
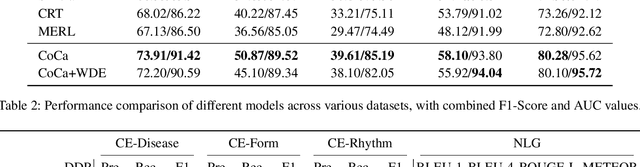
The success of Multimodal Large Language Models (MLLMs) in the medical auxiliary field shows great potential, allowing patients to engage in conversations using physiological signal data. However, general MLLMs perform poorly in cardiac disease diagnosis, particularly in the integration of ECG data analysis and long-text medical report generation, mainly due to the complexity of ECG data analysis and the gap between text and ECG signal modalities. Additionally, models often exhibit severe stability deficiencies in long-text generation due to the lack of precise knowledge strongly related to user queries. To address these issues, we propose ECG-Chat, the first multitask MLLMs focused on ECG medical report generation, providing multimodal conversational capabilities based on cardiology knowledge. We propose a contrastive learning approach that integrates ECG waveform data with text reports, aligning ECG features with reports in a fine-grained manner. This method also results in an ECG encoder that excels in zero-shot report retrieval tasks. Additionally, expanding existing datasets, we constructed a 19k ECG diagnosis dataset and a 25k multi-turn dialogue dataset for training and fine-tuning ECG-Chat, which provides professional diagnostic and conversational capabilities. Furthermore, ECG-Chat can generate comprehensive ECG analysis reports through an automated LaTeX generation pipeline. We established a benchmark for the ECG report generation task and tested our model on multiple baselines. ECG-Chat achieved the best performance in classification, retrieval, multimodal dialogue, and medical report generation tasks. Our report template design has also been widely recognized by medical practitioners.