 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Noises Are Linearly Separable for (Nearly) Random Neural Networks
Paper and Code
Jun 09, 2022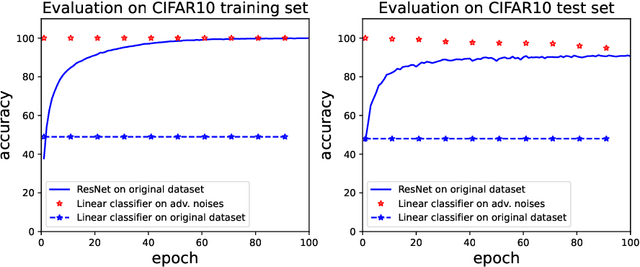

Adversarial examples, which are usually generated for specific inputs with a specific model, are ubiquitous for neural networks. In this paper we unveil a surprising property of adversarial noises when they are put together, i.e., adversarial noises crafted by one-step gradient methods are linearly separable if equipped with the corresponding labels. We theoretically prove this property for a two-layer network with randomly initialized entries and the neural tangent kernel setup where the parameters are not far from initialization. The proof idea is to show the label information can be efficiently backpropagated to the input while keeping the linear separability. Our theory and experimental evidence further show that the linear classifier trained with the adversarial noises of the training data can well classify the adversarial noises of the test data, indicating that adversarial noises actually inject a distributional perturbation to the original data distribution. Furthermore, we empirically demonstrate that the adversarial noises may become less linearly separable when the above conditions are compromised while they are still much easier to classify than original features.