 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalls-and-Bins Sampling for DP-SGD
Dec 21, 2024We introduce the Balls-and-Bins sampling for differentially private (DP) optimization methods such as DP-SGD. While it has been common practice to use some form of shuffling in DP-SGD implementations, privacy accounting algorithms have typically assumed that Poisson subsampling is used instead. Recent work by Chua et al. (ICML 2024) however pointed out that shuffling based DP-SGD can have a much larger privacy cost in practical regimes of parameters. We show that the Balls-and-Bins sampling achieves the "best-of-both" samplers, namely, the implementation of Balls-and-Bins sampling is similar to that of Shuffling and models trained using DP-SGD with Balls-and-Bins sampling achieve utility comparable to those trained using DP-SGD with Shuffling at the same noise multiplier, and yet, Balls-and-Bins sampling enjoys similar-or-better privacy amplification as compared to Poisson subsampling in practical regimes.
Optimal Unbiased Randomizers for Regression with Label Differential Privacy
Dec 09, 2023We propose a new family of label randomizers for training regression models under the constraint of label differential privacy (DP). In particular, we leverage the trade-offs between bias and variance to construct better label randomizers depending on a privately estimated prior distribution over the labels. We demonstrate that these randomizers achieve state-of-the-art privacy-utility trade-offs on several datasets, highlighting the importance of reducing bias when training neural networks with label DP. We also provide theoretical results shedding light on the structural properties of the optimal unbiased randomizers.
Regression with Label Differential Privacy
Dec 12, 2022


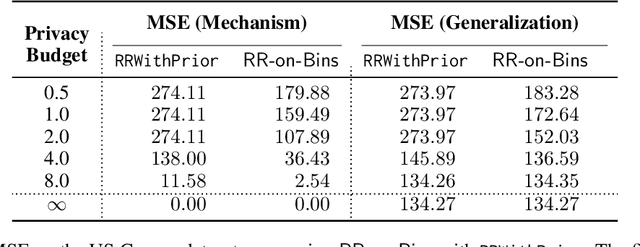
We study the task of training regression models with the guarantee of label differential privacy (DP). Based on a global prior distribution on label values, which could be obtained privately, we derive a label DP randomization mechanism that is optimal under a given regression loss function. We prove that the optimal mechanism takes the form of a ``randomized response on bins'', and propose an efficient algorithm for finding the optimal bin values. We carry out a thorough experimental evaluation on several datasets demonstrating the efficacy of our algorithm.