 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring and Mitigating Adversarial Manipulation of Voting-Based Leaderboards
Jan 13, 2025



It is now common to evaluate Large Language Models (LLMs) by having humans manually vote to evaluate model outputs, in contrast to typical benchmarks that evaluate knowledge or skill at some particular task. Chatbot Arena, the most popular benchmark of this type, ranks models by asking users to select the better response between two randomly selected models (without revealing which model was responsible for the generations). These platforms are widely trusted as a fair and accurate measure of LLM capabilities. In this paper, we show that if bot protection and other defenses are not implemented, these voting-based benchmarks are potentially vulnerable to adversarial manipulation. Specifically, we show that an attacker can alter the leaderboard (to promote their favorite model or demote competitors) at the cost of roughly a thousand votes (verified in a simulated, offline version of Chatbot Arena). Our attack consists of two steps: first, we show how an attacker can determine which model was used to generate a given reply with more than $95\%$ accuracy; and then, the attacker can use this information to consistently vote for (or against) a target model. Working with the Chatbot Arena developers, we identify, propose, and implement mitigations to improve the robustness of Chatbot Arena against adversarial manipulation, which, based on our analysis, substantially increases the cost of such attacks. Some of these defenses were present before our collaboration, such as bot protection with Cloudflare, malicious user detection, and rate limiting. Others, including reCAPTCHA and login are being integrated to strengthen the security in Chatbot Arena.
Conformal Policy Learning for Sensorimotor Control Under Distribution Shifts
Nov 02, 2023This paper focuses on the problem of detecting and reacting to changes in the distribution of a sensorimotor controller's observables. The key idea is the design of switching policies that can take conformal quantiles as input, which we define as conformal policy learning, that allows robots to detect distribution shifts with formal statistical guarantees. We show how to design such policies by using conformal quantiles to switch between base policies with different characteristics, e.g. safety or speed, or directly augmenting a policy observation with a quantile and training it with reinforcement learning. Theoretically, we show that such policies achieve the formal convergence guarantees in finite time. In addition, we thoroughly evaluate their advantages and limitations on two compelling use cases: simulated autonomous driving and active perception with a physical quadruped. Empirical results demonstrate that our approach outperforms five baselines. It is also the simplest of the baseline strategies besides one ablation. Being easy to use, flexible, and with formal guarantees, our work demonstrates how conformal prediction can be an effective tool for sensorimotor learning under uncertainty.
Learned, Uncertainty-driven Adaptive Acquisition for Photon-Efficient Multiphoton Microscopy
Oct 24, 2023Multiphoton microscopy (MPM) is a powerful imaging tool that has been a critical enabler for live tissue imaging. However, since most multiphoton microscopy platforms rely on point scanning, there is an inherent trade-off between acquisition time, field of view (FOV), phototoxicity, and image quality, often resulting in noisy measurements when fast, large FOV, and/or gentle imaging is needed. Deep learning could be used to denoise multiphoton microscopy measurements, but these algorithms can be prone to hallucination, which can be disastrous for medical and scientific applications. We propose a method to simultaneously denoise and predict pixel-wise uncertainty for multiphoton imaging measurements, improving algorithm trustworthiness and providing statistical guarantees for the deep learning predictions. Furthermore, we propose to leverage this learned, pixel-wise uncertainty to drive an adaptive acquisition technique that rescans only the most uncertain regions of a sample. We demonstrate our method on experimental noisy MPM measurements of human endometrium tissues, showing that we can maintain fine features and outperform other denoising methods while predicting uncertainty at each pixel. Finally, with our adaptive acquisition technique, we demonstrate a 120X reduction in acquisition time and total light dose while successfully recovering fine features in the sample. We are the first to demonstrate distribution-free uncertainty quantification for a denoising task with real experimental data and the first to propose adaptive acquisition based on reconstruction uncertainty
Linear Revolution-Invariance: Modeling and Deblurring Spatially-Varying Imaging Systems
Jun 17, 2022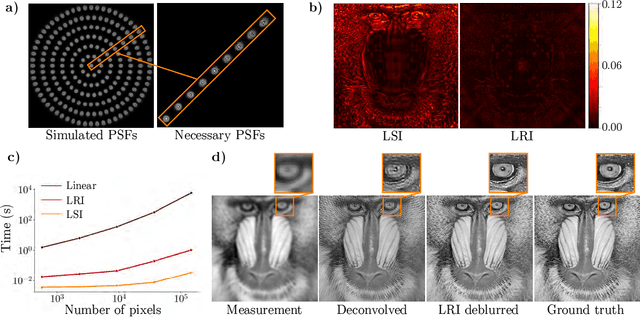
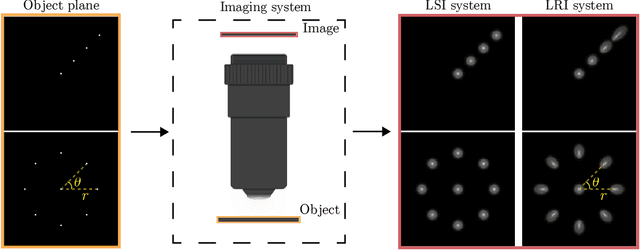
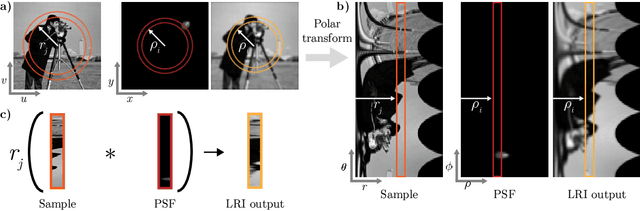
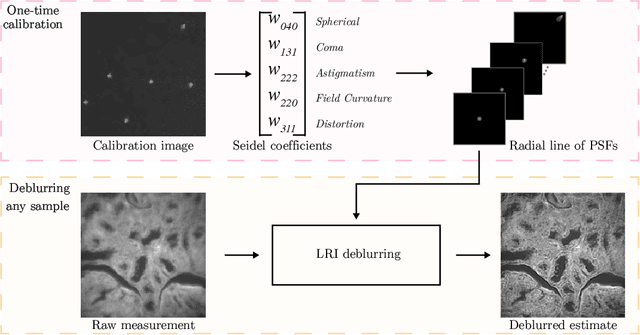
We develop theory and algorithms for modeling and deblurring imaging systems that are composed of rotationally-symmetric optics. Such systems have point spread functions (PSFs) which are spatially-varying, but only vary radially, a property we call linear revolution-invariance (LRI). From the LRI property we develop an exact theory for linear imaging with radially-varying optics, including an analog of the Fourier Convolution Theorem. This theory, in tandem with a calibration procedure using Seidel aberration coefficients, yields an efficient forward model and deblurring algorithm which requires only a single calibration image -- one that is easier to measure than a single PSF. We test these methods in simulation and experimentally on images of resolution targets, rabbit liver tissue, and live tardigrades obtained using the UCLA Miniscope v3. We find that the LRI forward model generates accurate radially-varying blur, and LRI deblurring improves resolution, especially near the edges of the field-of-view. These methods are available for use as a Python package at https://github.com/apsk14/lri.
Online Active Learning with Dynamic Marginal Gain Thresholding
Jan 25, 2022
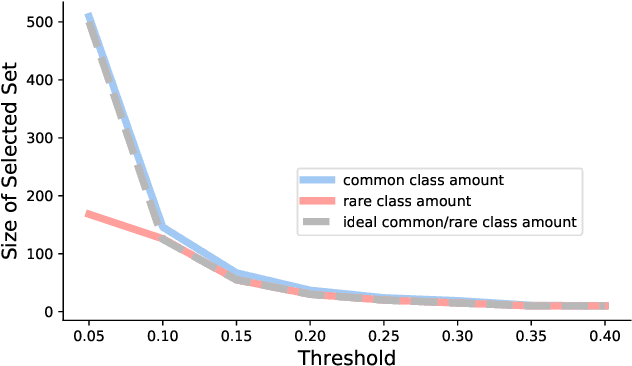
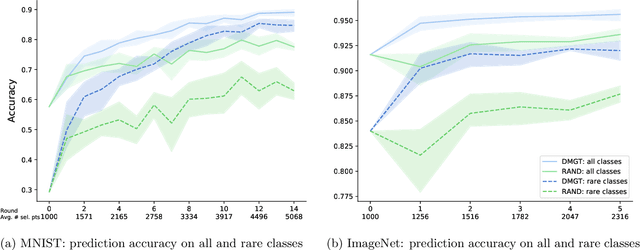
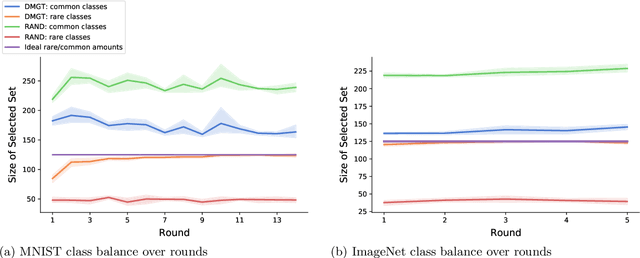
The blessing of ubiquitous data also comes with a curse: the communication, storage, and labeling of massive, mostly redundant datasets. In our work, we seek to solve the problem at its source, collecting only valuable data and throwing out the rest, via active learning. We propose an online algorithm which, given any stream of data, any assessment of its value, and any formulation of its selection cost, extracts the most valuable subset of the stream up to a constant factor while using minimal memory. Notably, our analysis also holds for the federated setting, in which multiple agents select online from individual data streams without coordination and with potentially very different appraisals of cost. One particularly important use case is selecting and labeling training sets from unlabeled collections of data that maximize the test-time performance of a given classifier. In prediction tasks on ImageNet and MNIST, we show that our selection method outperforms random selection by up to 5-20%.
Distribution-Free, Risk-Controlling Prediction Sets
Jan 30, 2021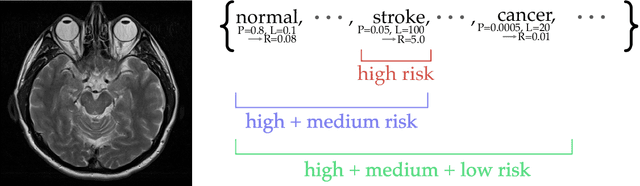
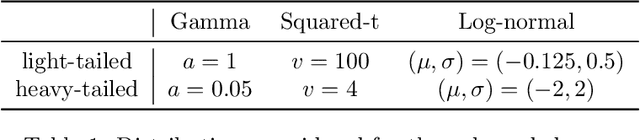
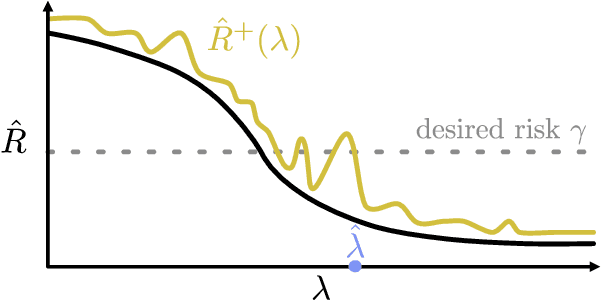
While improving prediction accuracy has been the focus of machine learning in recent years, this alone does not suffice for reliable decision-making. Deploying learning systems in consequential settings also requires calibrating and communicating the uncertainty of predictions. To convey instance-wise uncertainty for prediction tasks, we show how to generate set-valued predictions from a black-box predictor that control the expected loss on future test points at a user-specified level. Our approach provides explicit finite-sample guarantees for any dataset by using a holdout set to calibrate the size of the prediction sets. This framework enables simple, distribution-free, rigorous error control for many tasks, and we demonstrate it in five large-scale machine learning problems: (1) classification problems where some mistakes are more costly than others; (2) multi-label classification, where each observation has multiple associated labels; (3) classification problems where the labels have a hierarchical structure; (4) image segmentation, where we wish to predict a set of pixels containing an object of interest; and (5) protein structure prediction. Lastly, we discuss extensions to uncertainty quantification for ranking, metric learning and distributionally robust learning.
Uncertainty Sets for Image Classifiers using Conformal Prediction
Sep 29, 2020
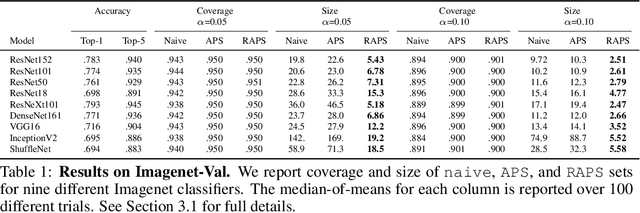
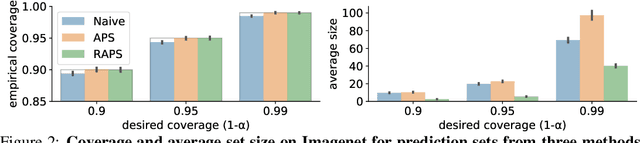
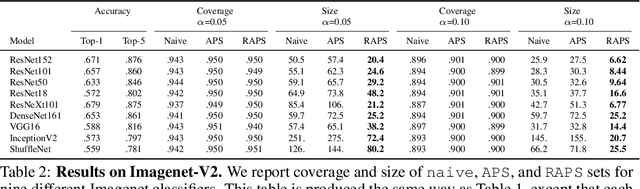
Convolutional image classifiers can achieve high predictive accuracy, but quantifying their uncertainty remains an unresolved challenge, hindering their deployment in consequential settings. Existing uncertainty quantification techniques, such as Platt scaling, attempt to calibrate the network's probability estimates, but they do not have formal guarantees. We present an algorithm that modifies any classifier to output a predictive set containing the true label with a user-specified probability, such as 90%. The algorithm is simple and fast like Platt scaling, but provides a formal finite-sample coverage guarantee for every model and dataset. Furthermore, our method generates much smaller predictive sets than alternative methods, since we introduce a regularizer to stabilize the small scores of unlikely classes after Platt scaling. In experiments on both Imagenet and Imagenet-V2 with a ResNet-152 and other classifiers, our scheme outperforms existing approaches, achieving exact coverage with sets that are often factors of 5 to 10 smaller.