 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise2Image: Noise-Enabled Static Scene Recovery for Event Cameras
Apr 01, 2024Event cameras capture changes of intensity over time as a stream of 'events' and generally cannot measure intensity itself; hence, they are only used for imaging dynamic scenes. However, fluctuations due to random photon arrival inevitably trigger noise events, even for static scenes. While previous efforts have been focused on filtering out these undesirable noise events to improve signal quality, we find that, in the photon-noise regime, these noise events are correlated with the static scene intensity. We analyze the noise event generation and model its relationship to illuminance. Based on this understanding, we propose a method, called Noise2Image, to leverage the illuminance-dependent noise characteristics to recover the static parts of a scene, which are otherwise invisible to event cameras. We experimentally collect a dataset of noise events on static scenes to train and validate Noise2Image. Our results show that Noise2Image can robustly recover intensity images solely from noise events, providing a novel approach for capturing static scenes in event cameras, without additional hardware.
Wavefront Randomization Improves Deconvolution
Feb 13, 2024The performance of an imaging system is limited by optical aberrations, which cause blurriness in the resulting image. Digital correction techniques, such as deconvolution, have limited ability to correct the blur, since some spatial frequencies in the scene are not measured adequately (i.e., 'zeros' of the system transfer function). We prove that the addition of a random mask to an imaging system removes its dependence on aberrations, reducing the likelihood of zeros in the transfer function and consequently decreasing the sensitivity to noise during deconvolution. In simulation, we show that this strategy improves image quality over a range of aberration types, aberration strengths, and signal-to-noise ratios.
Linear Revolution-Invariance: Modeling and Deblurring Spatially-Varying Imaging Systems
Jun 17, 2022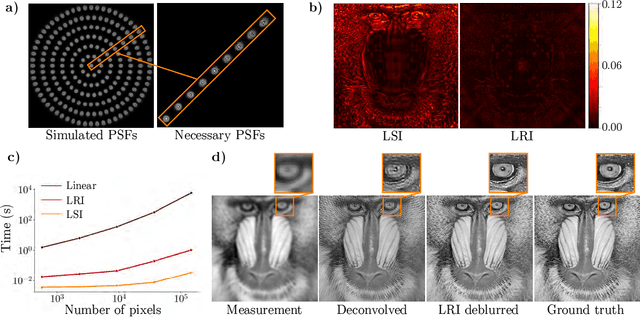
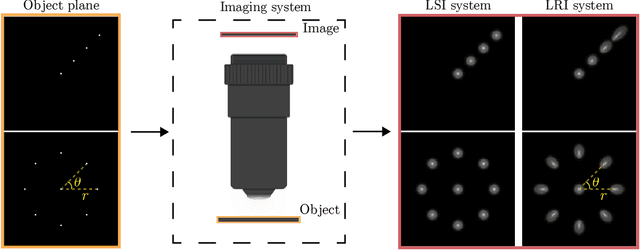
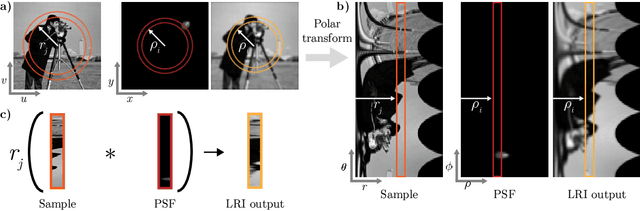
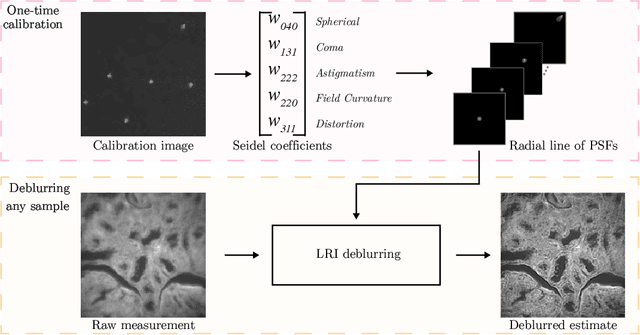
We develop theory and algorithms for modeling and deblurring imaging systems that are composed of rotationally-symmetric optics. Such systems have point spread functions (PSFs) which are spatially-varying, but only vary radially, a property we call linear revolution-invariance (LRI). From the LRI property we develop an exact theory for linear imaging with radially-varying optics, including an analog of the Fourier Convolution Theorem. This theory, in tandem with a calibration procedure using Seidel aberration coefficients, yields an efficient forward model and deblurring algorithm which requires only a single calibration image -- one that is easier to measure than a single PSF. We test these methods in simulation and experimentally on images of resolution targets, rabbit liver tissue, and live tardigrades obtained using the UCLA Miniscope v3. We find that the LRI forward model generates accurate radially-varying blur, and LRI deblurring improves resolution, especially near the edges of the field-of-view. These methods are available for use as a Python package at https://github.com/apsk14/lri.
Inferring Semantic Information with 3D Neural Scene Representations
Mar 28, 2020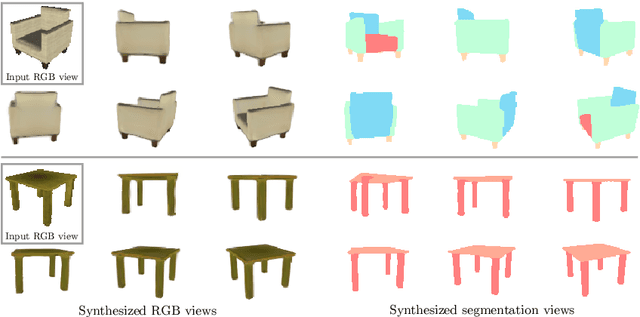

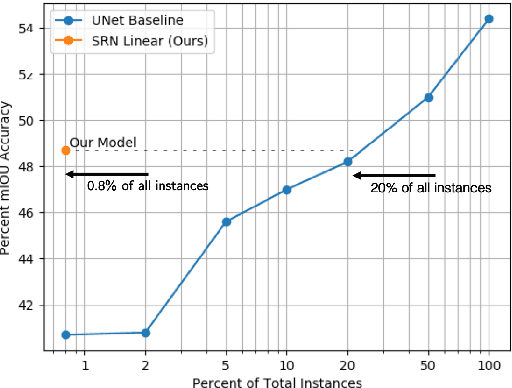
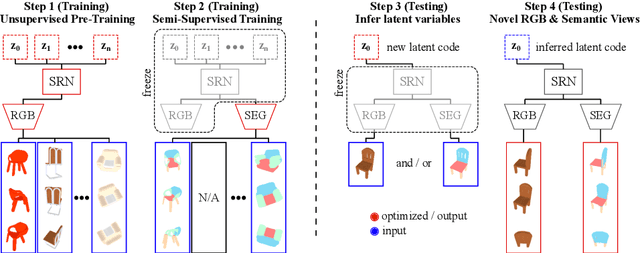
Biological vision infers multi-modal 3D representations that support reasoning about scene properties such as materials, appearance, affordance, and semantics in 3D. These rich representations enable us humans, for example, to acquire new skills, such as the learning of a new semantic class, with extremely limited supervision. Motivated by this ability of biological vision, we demonstrate that 3D-structure-aware representation learning leads to multi-modal representations that enable 3D semantic segmentation with extremely limited, 2D-only supervision. Building on emerging neural scene representations, which have been developed for modeling the shape and appearance of 3D scenes supervised exclusively by posed 2D images, we are first to demonstrate a representation that jointly encodes shape, appearance, and semantics in a 3D-structure-aware manner. Surprisingly, we find that only a few tens of labeled 2D segmentation masks are required to achieve dense 3D semantic segmentation using a semi-supervised learning strategy. We explore two novel applications for our semantically aware neural scene representation: 3D novel view and semantic label synthesis given only a single input RGB image or 2D label mask, as well as 3D interpolation of appearance and semantics.