 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Motion for Structured Illumination Fluorescence Microscopy
Feb 05, 2025



Structured illumination microscopy (SIM) uses a set of images captured with different patterned illumination to computationally reconstruct resolution beyond the diffraction limit. Here, we propose an alternative approach using a static speckle illumination pattern and relying on inherent sample motion to encode the super-resolved information in multiple raw images, for the case of fluorescence microscopy. From a set of sequentially captured raw images, we jointly estimate the sample motion and the super-resolved image. We demonstrate the feasibility of the proposed method both in simulation and in experiment.
Multi-modal deformable image registration using untrained neural networks
Nov 04, 2024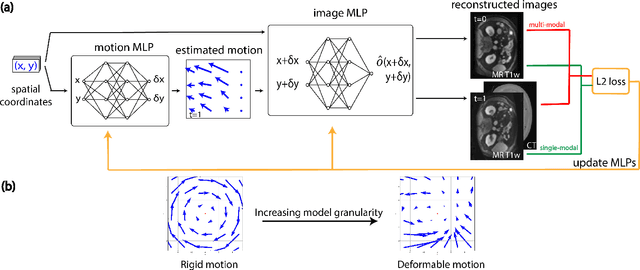



Image registration techniques usually assume that the images to be registered are of a certain type (e.g. single- vs. multi-modal, 2D vs. 3D, rigid vs. deformable) and there lacks a general method that can work for data under all conditions. We propose a registration method that utilizes neural networks for image representation. Our method uses untrained networks with limited representation capacity as an implicit prior to guide for a good registration. Unlike previous approaches that are specialized for specific data types, our method handles both rigid and non-rigid, as well as single- and multi-modal registration, without requiring changes to the model or objective function. We have performed a comprehensive evaluation study using a variety of datasets and demonstrated promising performance.
Noise2Image: Noise-Enabled Static Scene Recovery for Event Cameras
Apr 01, 2024Event cameras capture changes of intensity over time as a stream of 'events' and generally cannot measure intensity itself; hence, they are only used for imaging dynamic scenes. However, fluctuations due to random photon arrival inevitably trigger noise events, even for static scenes. While previous efforts have been focused on filtering out these undesirable noise events to improve signal quality, we find that, in the photon-noise regime, these noise events are correlated with the static scene intensity. We analyze the noise event generation and model its relationship to illuminance. Based on this understanding, we propose a method, called Noise2Image, to leverage the illuminance-dependent noise characteristics to recover the static parts of a scene, which are otherwise invisible to event cameras. We experimentally collect a dataset of noise events on static scenes to train and validate Noise2Image. Our results show that Noise2Image can robustly recover intensity images solely from noise events, providing a novel approach for capturing static scenes in event cameras, without additional hardware.
Dynamic Structured Illumination Microscopy with a Neural Space-time Model
Jun 03, 2022
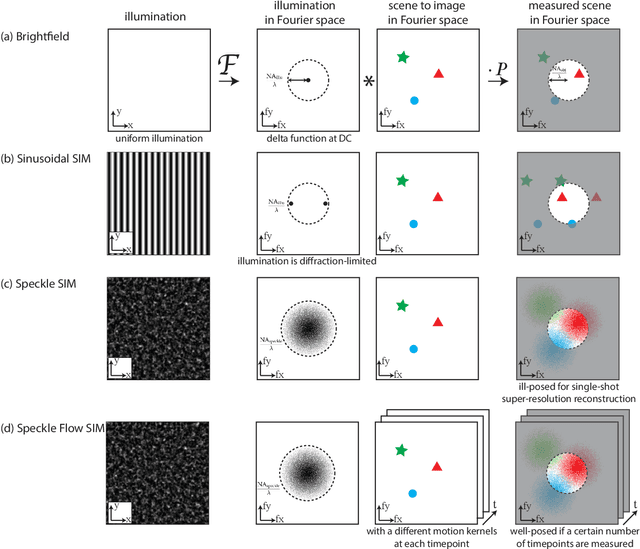
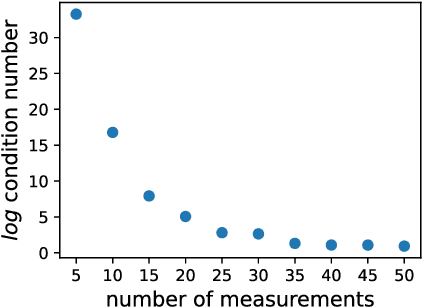
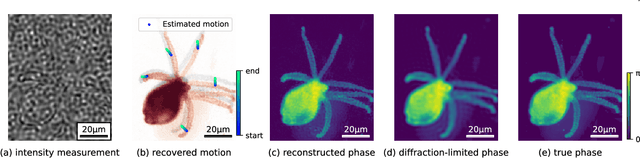
Structured illumination microscopy (SIM) reconstructs a super-resolved image from multiple raw images; hence, acquisition speed is limited, making it unsuitable for dynamic scenes. We propose a new method, Speckle Flow SIM, that models sample motion during the data capture in order to reconstruct dynamic scenes with super-resolution. Speckle Flow SIM uses fixed speckle illumination and relies on sample motion to capture a sequence of raw images. Then, the spatio-temporal relationship of the dynamic scene is modeled using a neural space-time model with coordinate-based multi-layer perceptrons (MLPs), and the motion dynamics and the super-resolved scene are jointly recovered. We validated Speckle Flow SIM in simulation and built a simple, inexpensive experimental setup with off-the-shelf components. We demonstrated that Speckle Flow SIM can reconstruct a dynamic scene with deformable motion and 1.88x the diffraction-limited resolution in experiment.
Prostate cancer inference via weakly-supervised learning using a large collection of negative MRI
Oct 05, 2019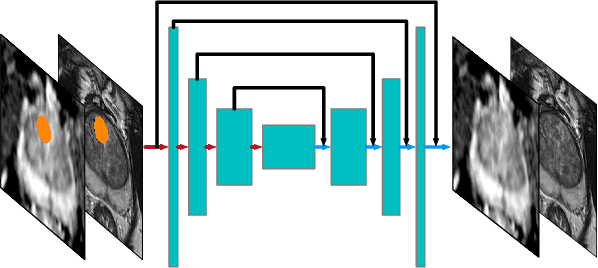
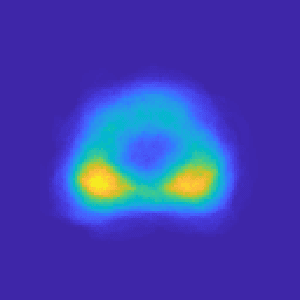
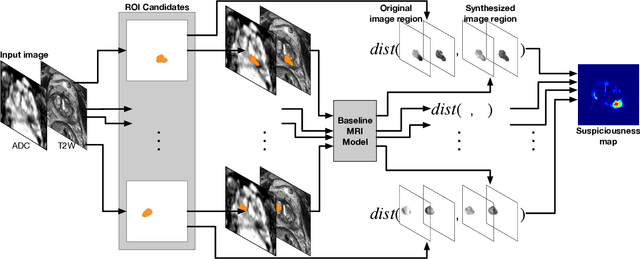
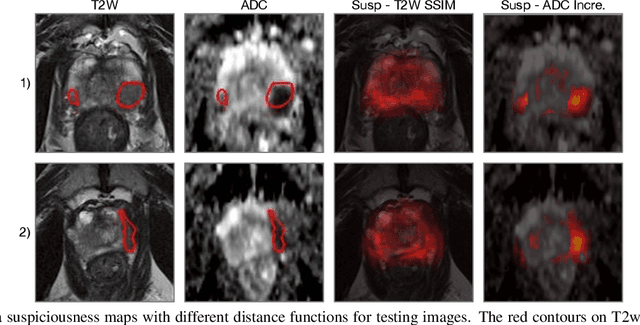
Recent advances in medical imaging techniques have led to significant improvements in the management of prostate cancer (PCa). In particular, multi-parametric MRI (mp-MRI) continues to gain clinical acceptance as the preferred imaging technique for non-invasive detection and grading of PCa. However, the machine learning-based diagnosis systems for PCa are often constrained by the limited access to accurate lesion ground truth annotations for training. The performance of the machine learning system is highly dependable on both quality and quantity of lesion annotations associated with histopathologic findings, resulting in limited scalability and clinical validation. Here, we propose the baseline MRI model to alternatively learn the appearance of mp-MRI using radiology-confirmed negative MRI cases via weakly supervised learning. Since PCa lesions are case-specific and highly heterogeneous, it is assumed to be challenging to synthesize PCa lesions using the baseline MRI model, while it would be relatively easier to synthesize the normal appearance in mp-MRI. We then utilize the baseline MRI model to infer the pixel-wise suspiciousness of PCa by comparing the original and synthesized MRI with two distance functions. We trained and validated the baseline MRI model using 1,145 negative prostate mp-MRI scans. For evaluation, we used separated 232 mp-MRI scans, consisting of both positive and negative MRI cases. The 116 positive MRI scans were annotated by radiologists, confirmed with post-surgical whole-gland specimens. The suspiciousness map was evaluated by receiver operating characteristic (ROC) analysis for PCa lesions versus non-PCa regions classification and free-response receiver operating characteristic (FROC) analysis for PCa localization. Our proposed method achieved 0.84 area under the ROC curve and 77.0% sensitivity at one false positive per patient in FROC analysis.
Explanatory Graphs for CNNs
Dec 18, 2018

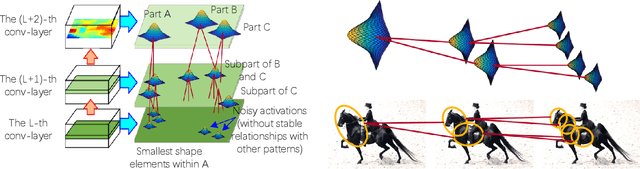

This paper introduces a graphical model, namely an explanatory graph, which reveals the knowledge hierarchy hidden inside conv-layers of a pre-trained CNN. Each filter in a conv-layer of a CNN for object classification usually represents a mixture of object parts. We develop a simple yet effective method to disentangle object-part pattern components from each filter. We construct an explanatory graph to organize the mined part patterns, where a node represents a part pattern, and each edge encodes co-activation relationships and spatial relationships between patterns. More crucially, given a pre-trained CNN, the explanatory graph is learned without a need of annotating object parts. Experiments show that each graph node consistently represented the same object part through different images, which boosted the transferability of CNN features. We transferred part patterns in the explanatory graph to the task of part localization, and our method significantly outperformed other approaches.
Mining Interpretable AOG Representations from Convolutional Networks via Active Question Answering
Dec 18, 2018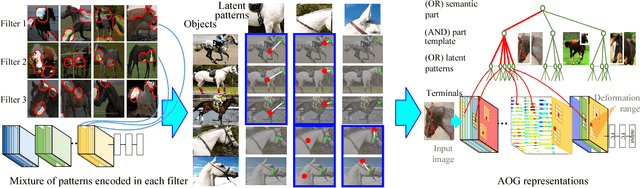
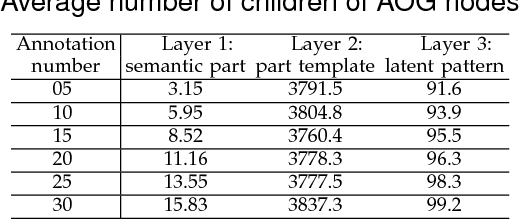
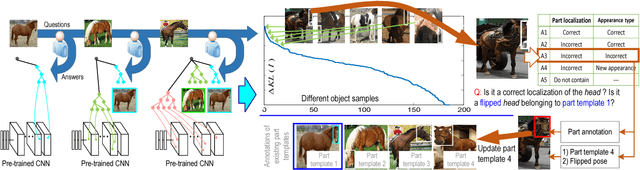
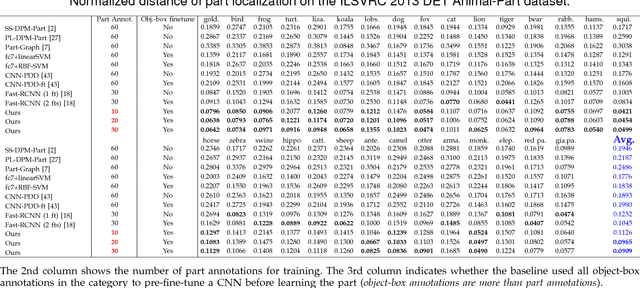
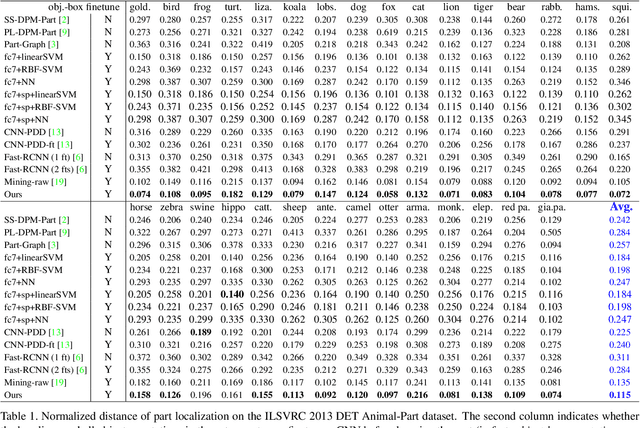
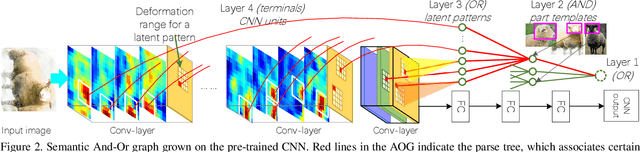
In this paper, we present a method to mine object-part patterns from conv-layers of a pre-trained convolutional neural network (CNN). The mined object-part patterns are organized by an And-Or graph (AOG). This interpretable AOG representation consists of a four-layer semantic hierarchy, i.e., semantic parts, part templates, latent patterns, and neural units. The AOG associates each object part with certain neural units in feature maps of conv-layers. The AOG is constructed in a weakly-supervised manner, i.e., very few annotations (e.g., 3-20) of object parts are used to guide the learning of AOGs. We develop a question-answering (QA) method that uses active human-computer communications to mine patterns from a pre-trained CNN, in order to incrementally explain more features in conv-layers. During the learning process, our QA method uses the current AOG for part localization. The QA method actively identifies objects, whose feature maps cannot be explained by the AOG. Then, our method asks people to annotate parts on the unexplained objects, and uses answers to discover CNN patterns corresponding to the newly labeled parts. In this way, our method gradually grows new branches and refines existing branches on the AOG to semanticize CNN representations. In experiments, our method exhibited a high learning efficiency. Our method used about 1/6-1/3 of the part annotations for training, but achieved similar or better part-localization performance than fast-RCNN methods.
Interactively Transferring CNN Patterns for Part Localization
Nov 22, 2017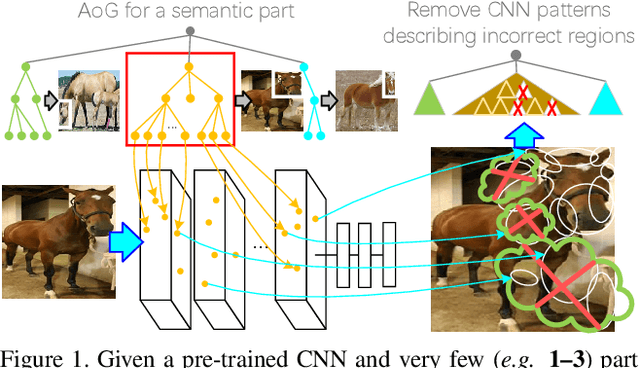

In the scenario of one/multi-shot learning, conventional end-to-end learning strategies without sufficient supervision are usually not powerful enough to learn correct patterns from noisy signals. Thus, given a CNN pre-trained for object classification, this paper proposes a method that first summarizes the knowledge hidden inside the CNN into a dictionary of latent activation patterns, and then builds a new model for part localization by manually assembling latent patterns related to the target part via human interactions. We use very few (e.g., three) annotations of a semantic object part to retrieve certain latent patterns from conv-layers to represent the target part. We then visualize these latent patterns and ask users to further remove incorrect patterns, in order to refine part representation. With the guidance of human interactions, our method exhibited superior performance of part localization in experiments.
Interpreting CNN Knowledge via an Explanatory Graph
Nov 22, 2017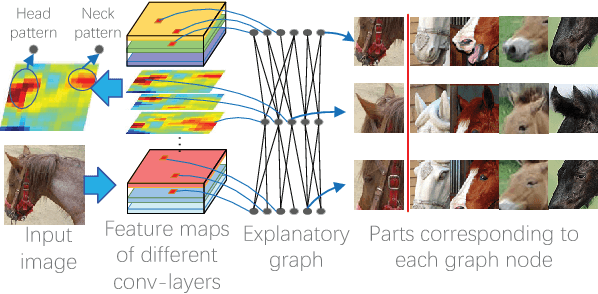

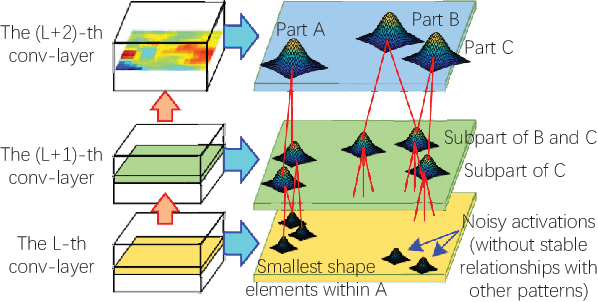

This paper learns a graphical model, namely an explanatory graph, which reveals the knowledge hierarchy hidden inside a pre-trained CNN. Considering that each filter in a conv-layer of a pre-trained CNN usually represents a mixture of object parts, we propose a simple yet efficient method to automatically disentangles different part patterns from each filter, and construct an explanatory graph. In the explanatory graph, each node represents a part pattern, and each edge encodes co-activation relationships and spatial relationships between patterns. More importantly, we learn the explanatory graph for a pre-trained CNN in an unsupervised manner, i.e., without a need of annotating object parts. Experiments show that each graph node consistently represents the same object part through different images. We transfer part patterns in the explanatory graph to the task of part localization, and our method significantly outperforms other approaches.
Mining Object Parts from CNNs via Active Question-Answering
Apr 11, 2017

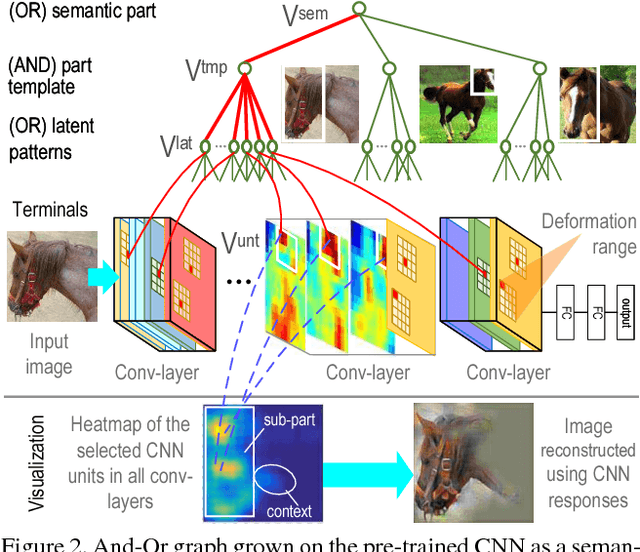
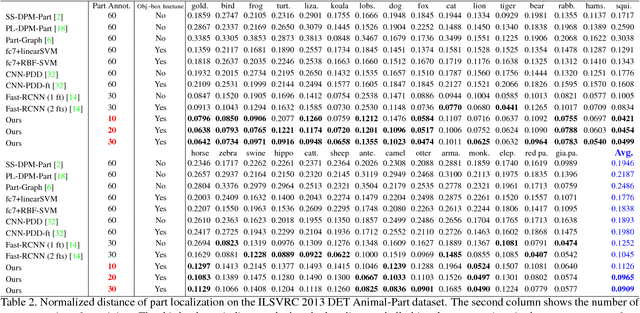
Given a convolutional neural network (CNN) that is pre-trained for object classification, this paper proposes to use active question-answering to semanticize neural patterns in conv-layers of the CNN and mine part concepts. For each part concept, we mine neural patterns in the pre-trained CNN, which are related to the target part, and use these patterns to construct an And-Or graph (AOG) to represent a four-layer semantic hierarchy of the part. As an interpretable model, the AOG associates different CNN units with different explicit object parts. We use an active human-computer communication to incrementally grow such an AOG on the pre-trained CNN as follows. We allow the computer to actively identify objects, whose neural patterns cannot be explained by the current AOG. Then, the computer asks human about the unexplained objects, and uses the answers to automatically discover certain CNN patterns corresponding to the missing knowledge. We incrementally grow the AOG to encode new knowledge discovered during the active-learning process. In experiments, our method exhibits high learning efficiency. Our method uses about 1/6-1/3 of the part annotations for training, but achieves similar or better part-localization performance than fast-RCNN methods.
* Published in CVPR 2017