 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractively Transferring CNN Patterns for Part Localization
Nov 22, 2017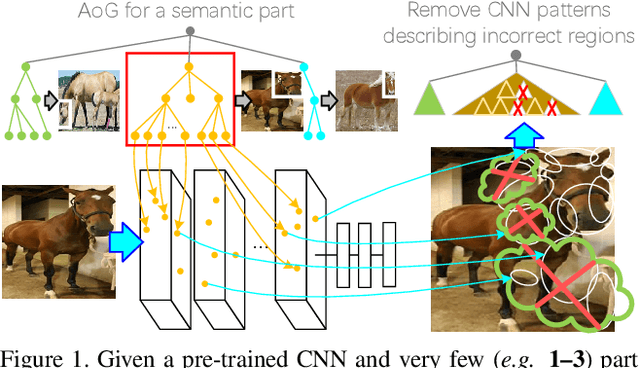
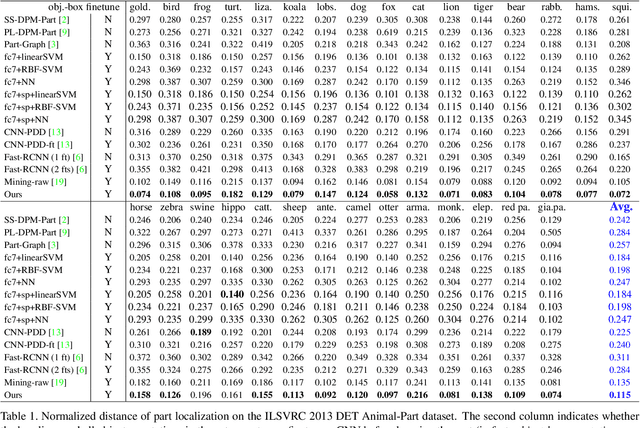
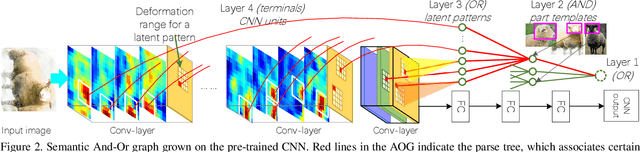

In the scenario of one/multi-shot learning, conventional end-to-end learning strategies without sufficient supervision are usually not powerful enough to learn correct patterns from noisy signals. Thus, given a CNN pre-trained for object classification, this paper proposes a method that first summarizes the knowledge hidden inside the CNN into a dictionary of latent activation patterns, and then builds a new model for part localization by manually assembling latent patterns related to the target part via human interactions. We use very few (e.g., three) annotations of a semantic object part to retrieve certain latent patterns from conv-layers to represent the target part. We then visualize these latent patterns and ask users to further remove incorrect patterns, in order to refine part representation. With the guidance of human interactions, our method exhibited superior performance of part localization in experiments.