 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHAT: Beyond Contrastive Graph Transformer for Link Prediction in Heterogeneous Networks
Jan 06, 2025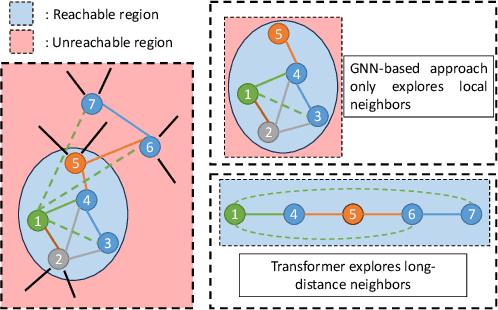


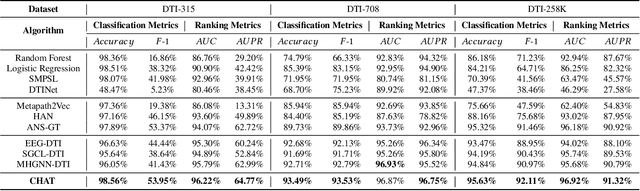
Link prediction in heterogeneous networks is crucial for understanding the intricacies of network structures and forecasting their future developments. Traditional methodologies often face significant obstacles, including over-smoothing-wherein the excessive aggregation of node features leads to the loss of critical structural details-and a dependency on human-defined meta-paths, which necessitate extensive domain knowledge and can be inherently restrictive. These limitations hinder the effective prediction and analysis of complex heterogeneous networks. In response to these challenges, we propose the Contrastive Heterogeneous grAph Transformer (CHAT). CHAT introduces a novel sampling-based graph transformer technique that selectively retains nodes of interest, thereby obviating the need for predefined meta-paths. The method employs an innovative connection-aware transformer to encode node sequences and their interconnections with high fidelity, guided by a dual-faceted loss function specifically designed for heterogeneous network link prediction. Additionally, CHAT incorporates an ensemble link predictor that synthesizes multiple samplings to achieve enhanced prediction accuracy. We conducted comprehensive evaluations of CHAT using three distinct drug-target interaction (DTI) datasets. The empirical results underscore CHAT's superior performance, outperforming both general-task approaches and models specialized in DTI prediction. These findings substantiate the efficacy of CHAT in addressing the complex problem of link prediction in heterogeneous networks.
Meta-Path-based Probabilistic Soft Logic for Drug-Target Interaction Prediction
Jun 25, 2023



Drug-target interaction (DTI) prediction, which aims at predicting whether a drug will be bounded to a target, have received wide attention recently, with the goal to automate and accelerate the costly process of drug design. Most of the recently proposed methods use single drug-drug similarity and target-target similarity information for DTI prediction, which are unable to take advantage of the abundant information regarding various types of similarities between them. Very recently, some methods are proposed to leverage multi-similarity information, however, they still lack the ability to take into consideration the rich topological information of all sorts of knowledge bases where the drugs and targets reside in. More importantly, the time consumption of these approaches is very high, which prevents the usage of large-scale network information. We thus propose a network-based drug-target interaction prediction approach, which applies probabilistic soft logic (PSL) to meta-paths on a heterogeneous network that contains multiple sources of information, including drug-drug similarities, target-target similarities, drug-target interactions, and other potential information. Our approach is based on the PSL graphical model and uses meta-path counts instead of path instances to reduce the number of rule instances of PSL. We compare our model against five methods, on three open-source datasets. The experimental results show that our approach outperforms all the five baselines in terms of AUPR score and AUC score.
Masked Vision-Language Transformers for Scene Text Recognition
Nov 09, 2022



Scene text recognition (STR) enables computers to recognize and read the text in various real-world scenes. Recent STR models benefit from taking linguistic information in addition to visual cues into consideration. We propose a novel Masked Vision-Language Transformers (MVLT) to capture both the explicit and the implicit linguistic information. Our encoder is a Vision Transformer, and our decoder is a multi-modal Transformer. MVLT is trained in two stages: in the first stage, we design a STR-tailored pretraining method based on a masking strategy; in the second stage, we fine-tune our model and adopt an iterative correction method to improve the performance. MVLT attains superior results compared to state-of-the-art STR models on several benchmarks. Our code and model are available at https://github.com/onealwj/MVLT.
Interactively Transferring CNN Patterns for Part Localization
Nov 22, 2017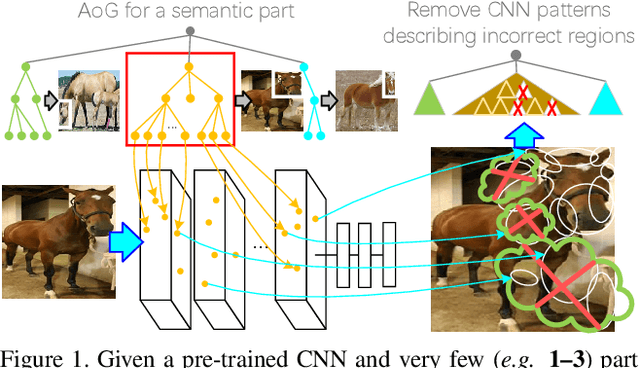
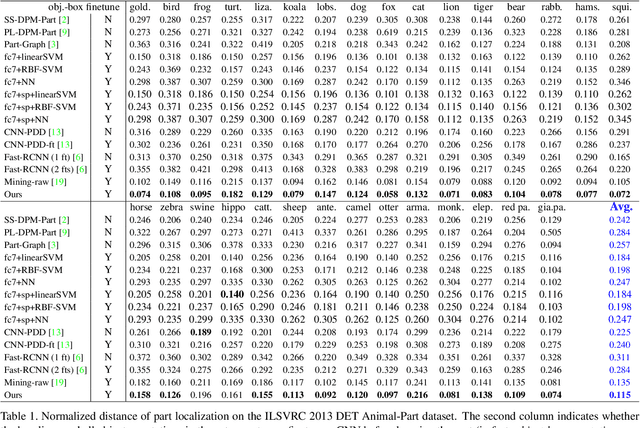
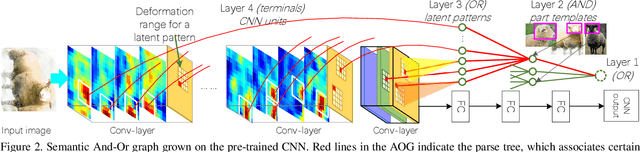

In the scenario of one/multi-shot learning, conventional end-to-end learning strategies without sufficient supervision are usually not powerful enough to learn correct patterns from noisy signals. Thus, given a CNN pre-trained for object classification, this paper proposes a method that first summarizes the knowledge hidden inside the CNN into a dictionary of latent activation patterns, and then builds a new model for part localization by manually assembling latent patterns related to the target part via human interactions. We use very few (e.g., three) annotations of a semantic object part to retrieve certain latent patterns from conv-layers to represent the target part. We then visualize these latent patterns and ask users to further remove incorrect patterns, in order to refine part representation. With the guidance of human interactions, our method exhibited superior performance of part localization in experiments.
Depth Image Inpainting: Improving Low Rank Matrix Completion with Low Gradient Regularization
Apr 20, 2016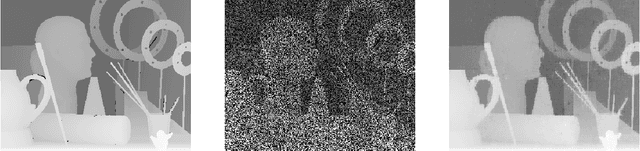


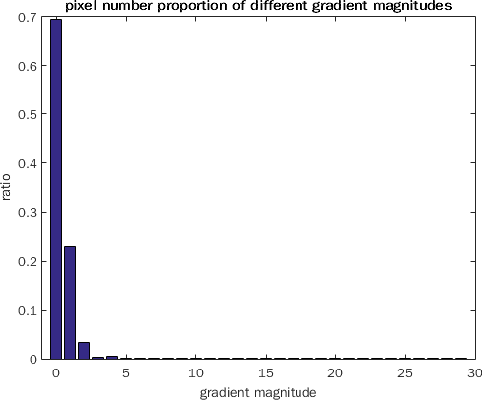
We consider the case of inpainting single depth images. Without corresponding color images, previous or next frames, depth image inpainting is quite challenging. One natural solution is to regard the image as a matrix and adopt the low rank regularization just as inpainting color images. However, the low rank assumption does not make full use of the properties of depth images. A shallow observation may inspire us to penalize the non-zero gradients by sparse gradient regularization. However, statistics show that though most pixels have zero gradients, there is still a non-ignorable part of pixels whose gradients are equal to 1. Based on this specific property of depth images , we propose a low gradient regularization method in which we reduce the penalty for gradient 1 while penalizing the non-zero gradients to allow for gradual depth changes. The proposed low gradient regularization is integrated with the low rank regularization into the low rank low gradient approach for depth image inpainting. We compare our proposed low gradient regularization with sparse gradient regularization. The experimental results show the effectiveness of our proposed approach.