 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation for Semantic Segmentation with Maximum Squares Loss
Sep 30, 2019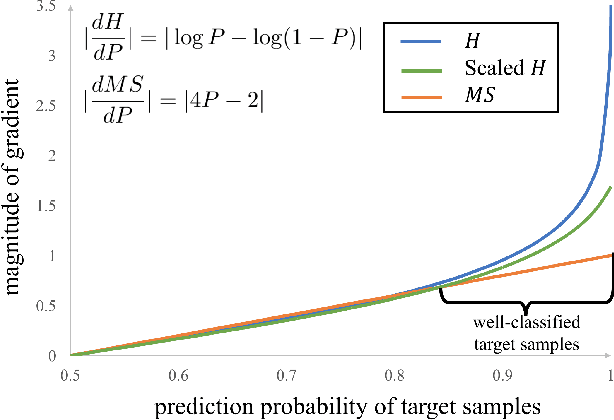
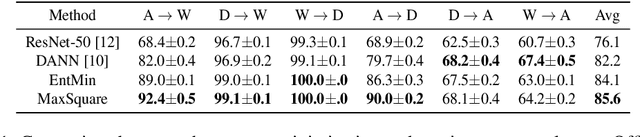
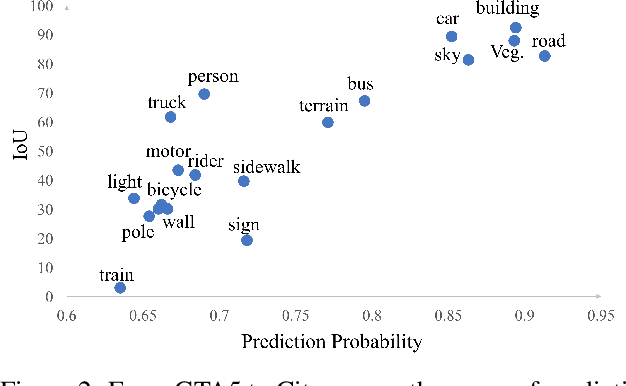
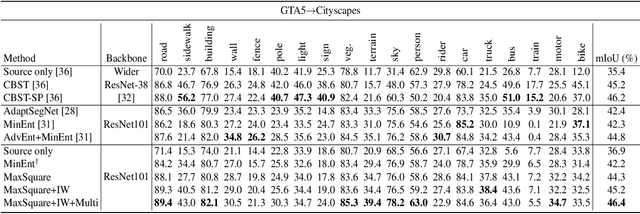
Deep neural networks for semantic segmentation always require a large number of samples with pixel-level labels, which becomes the major difficulty in their real-world applications. To reduce the labeling cost, unsupervised domain adaptation (UDA) approaches are proposed to transfer knowledge from labeled synthesized datasets to unlabeled real-world datasets. Recently, some semi-supervised learning methods have been applied to UDA and achieved state-of-the-art performance. One of the most popular approaches in semi-supervised learning is the entropy minimization method. However, when applying the entropy minimization to UDA for semantic segmentation, the gradient of the entropy is biased towards samples that are easy to transfer. To balance the gradient of well-classified target samples, we propose the maximum squares loss. Our maximum squares loss prevents the training process being dominated by easy-to-transfer samples in the target domain. Besides, we introduce the image-wise weighting ratio to alleviate the class imbalance in the unlabeled target domain. Both synthetic-to-real and cross-city adaptation experiments demonstrate the effectiveness of our proposed approach. The code is released at https://github. com/ZJULearning/MaxSquareLoss.
A Better Way to Attend: Attention with Trees for Video Question Answering
Sep 05, 2019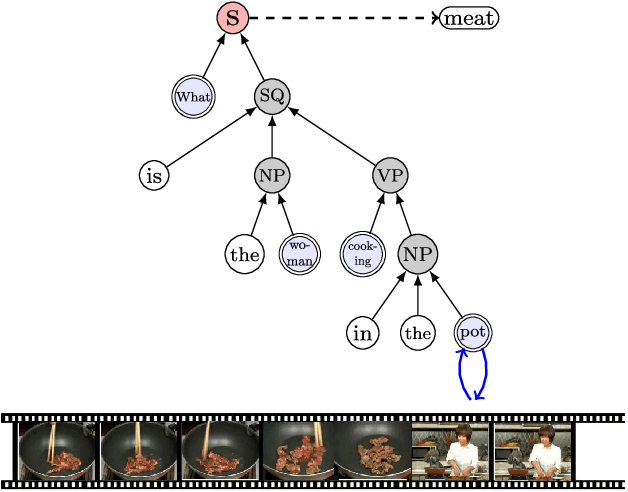


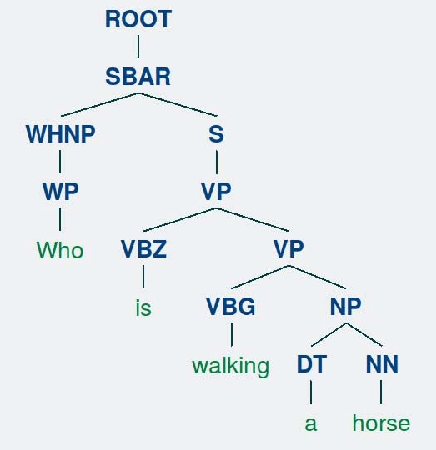
We propose a new attention model for video question answering. The main idea of the attention models is to locate on the most informative parts of the visual data. The attention mechanisms are quite popular these days. However, most existing visual attention mechanisms regard the question as a whole. They ignore the word-level semantics where each word can have different attentions and some words need no attention. Neither do they consider the semantic structure of the sentences. Although the Extended Soft Attention (E-SA) model for video question answering leverages the word-level attention, it performs poorly on long question sentences. In this paper, we propose the heterogeneous tree-structured memory network (HTreeMN) for video question answering. Our proposed approach is based upon the syntax parse trees of the question sentences. The HTreeMN treats the words differently where the \textit{visual} words are processed with an attention module and the \textit{verbal} ones not. It also utilizes the semantic structure of the sentences by combining the neighbors based on the recursive structure of the parse trees. The understandings of the words and the videos are propagated and merged from leaves to the root. Furthermore, we build a hierarchical attention mechanism to distill the attended features. We evaluate our approach on two datasets. The experimental results show the superiority of our HTreeMN model over the other attention models especially on complex questions. Our code is available on github. Our code is available at https://github.com/ZJULearning/TreeAttention
* 12 pages
The Forgettable-Watcher Model for Video Question Answering
May 03, 2017

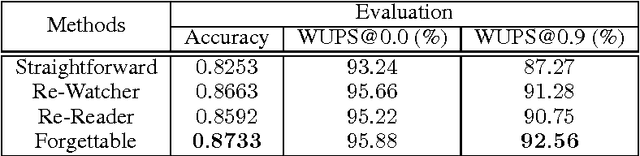
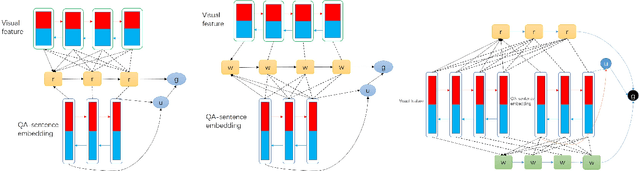
A number of visual question answering approaches have been proposed recently, aiming at understanding the visual scenes by answering the natural language questions. While the image question answering has drawn significant attention, video question answering is largely unexplored. Video-QA is different from Image-QA since the information and the events are scattered among multiple frames. In order to better utilize the temporal structure of the videos and the phrasal structures of the answers, we propose two mechanisms: the re-watching and the re-reading mechanisms and combine them into the forgettable-watcher model. Then we propose a TGIF-QA dataset for video question answering with the help of automatic question generation. Finally, we evaluate the models on our dataset. The experimental results show the effectiveness of our proposed models.
Depth Image Inpainting: Improving Low Rank Matrix Completion with Low Gradient Regularization
Apr 20, 2016


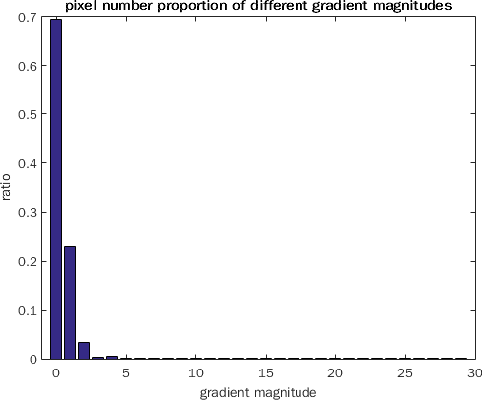
We consider the case of inpainting single depth images. Without corresponding color images, previous or next frames, depth image inpainting is quite challenging. One natural solution is to regard the image as a matrix and adopt the low rank regularization just as inpainting color images. However, the low rank assumption does not make full use of the properties of depth images. A shallow observation may inspire us to penalize the non-zero gradients by sparse gradient regularization. However, statistics show that though most pixels have zero gradients, there is still a non-ignorable part of pixels whose gradients are equal to 1. Based on this specific property of depth images , we propose a low gradient regularization method in which we reduce the penalty for gradient 1 while penalizing the non-zero gradients to allow for gradual depth changes. The proposed low gradient regularization is integrated with the low rank regularization into the low rank low gradient approach for depth image inpainting. We compare our proposed low gradient regularization with sparse gradient regularization. The experimental results show the effectiveness of our proposed approach.
Stereo Matching by Joint Energy Minimization
Feb 12, 2016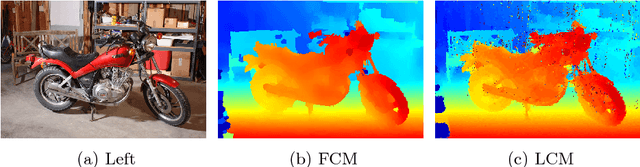
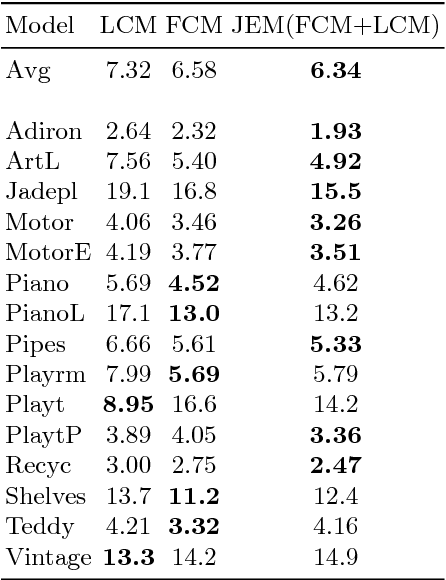
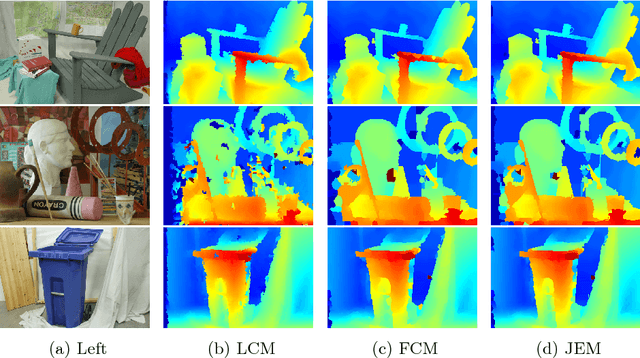
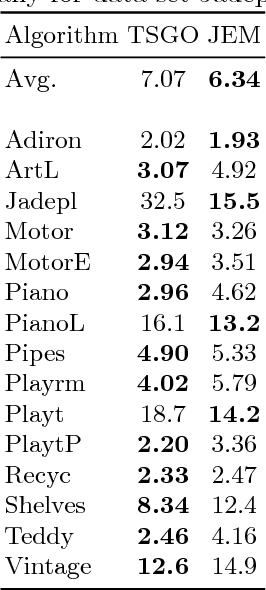
In [18], Mozerov et al. propose to perform stereo matching as a two-step energy minimization problem. For the first step they solve a fully connected MRF model. And in the next step the marginal output is employed as the unary cost for a locally connected MRF model. In this paper we intend to combine the two steps of energy minimization in order to improve stereo matching results. We observe that the fully connected MRF leads to smoother disparity maps, while the locally connected MRF achieves superior results in fine-structured regions. Thus we propose to jointly solve the fully connected and locally connected models, taking both their advantages into account. The joint model is solved by mean field approximations. While remaining efficient, our joint model outperforms the two-step energy minimization approach in both time and estimation error on the Middlebury stereo benchmark v3.