 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Forgettable-Watcher Model for Video Question Answering
Paper and Code
May 03, 2017

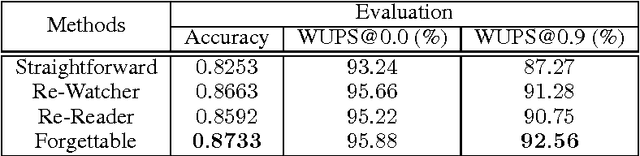
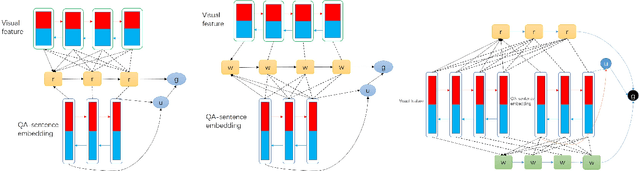
A number of visual question answering approaches have been proposed recently, aiming at understanding the visual scenes by answering the natural language questions. While the image question answering has drawn significant attention, video question answering is largely unexplored. Video-QA is different from Image-QA since the information and the events are scattered among multiple frames. In order to better utilize the temporal structure of the videos and the phrasal structures of the answers, we propose two mechanisms: the re-watching and the re-reading mechanisms and combine them into the forgettable-watcher model. Then we propose a TGIF-QA dataset for video question answering with the help of automatic question generation. Finally, we evaluate the models on our dataset. The experimental results show the effectiveness of our proposed models.