 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Better Way to Attend: Attention with Trees for Video Question Answering
Paper and Code
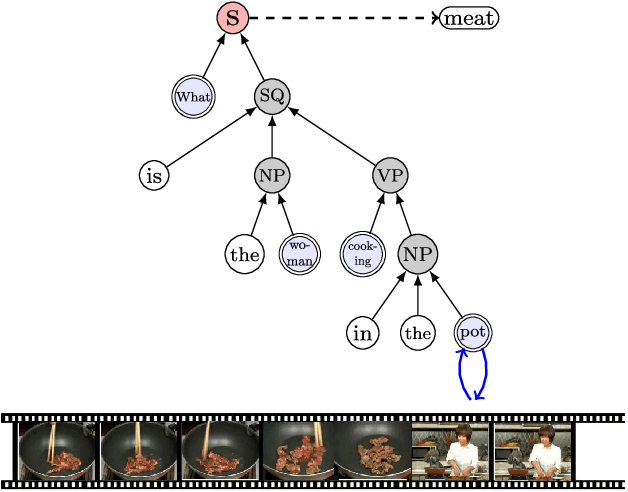


We propose a new attention model for video question answering. The main idea of the attention models is to locate on the most informative parts of the visual data. The attention mechanisms are quite popular these days. However, most existing visual attention mechanisms regard the question as a whole. They ignore the word-level semantics where each word can have different attentions and some words need no attention. Neither do they consider the semantic structure of the sentences. Although the Extended Soft Attention (E-SA) model for video question answering leverages the word-level attention, it performs poorly on long question sentences. In this paper, we propose the heterogeneous tree-structured memory network (HTreeMN) for video question answering. Our proposed approach is based upon the syntax parse trees of the question sentences. The HTreeMN treats the words differently where the \textit{visual} words are processed with an attention module and the \textit{verbal} ones not. It also utilizes the semantic structure of the sentences by combining the neighbors based on the recursive structure of the parse trees. The understandings of the words and the videos are propagated and merged from leaves to the root. Furthermore, we build a hierarchical attention mechanism to distill the attended features. We evaluate our approach on two datasets. The experimental results show the superiority of our HTreeMN model over the other attention models especially on complex questions. Our code is available on github. Our code is available at https://github.com/ZJULearning/TreeAttention