 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Active Learning with Dynamic Marginal Gain Thresholding
Jan 25, 2022
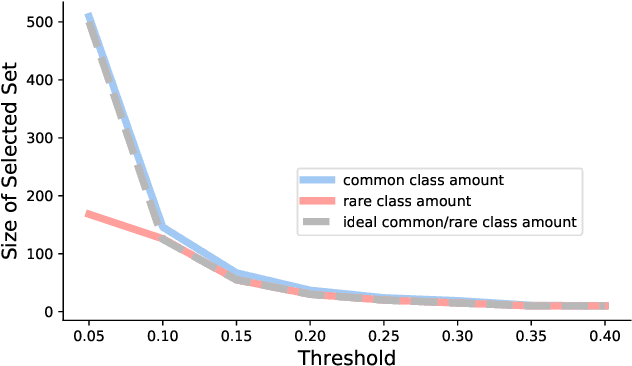
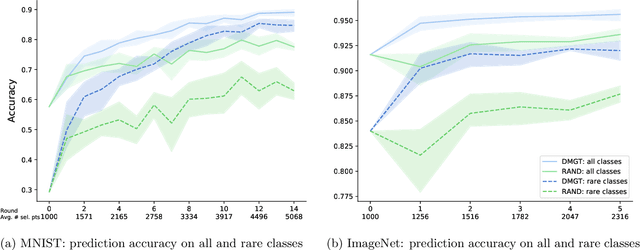
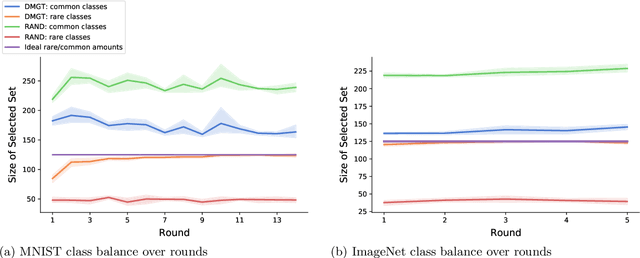
The blessing of ubiquitous data also comes with a curse: the communication, storage, and labeling of massive, mostly redundant datasets. In our work, we seek to solve the problem at its source, collecting only valuable data and throwing out the rest, via active learning. We propose an online algorithm which, given any stream of data, any assessment of its value, and any formulation of its selection cost, extracts the most valuable subset of the stream up to a constant factor while using minimal memory. Notably, our analysis also holds for the federated setting, in which multiple agents select online from individual data streams without coordination and with potentially very different appraisals of cost. One particularly important use case is selecting and labeling training sets from unlabeled collections of data that maximize the test-time performance of a given classifier. In prediction tasks on ImageNet and MNIST, we show that our selection method outperforms random selection by up to 5-20%.