 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Gaussian Instance Segmentation in Point Clouds
Jul 20, 2020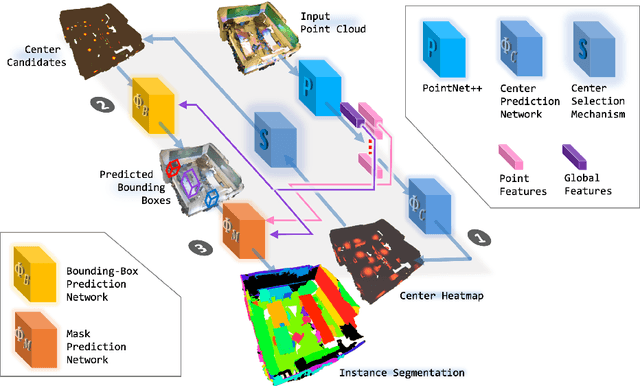
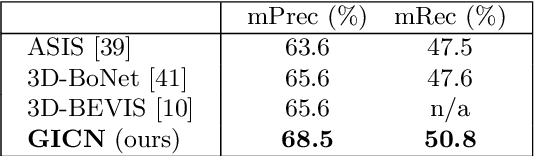
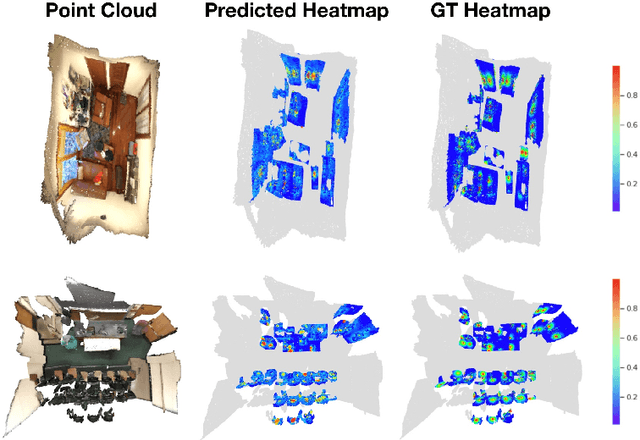
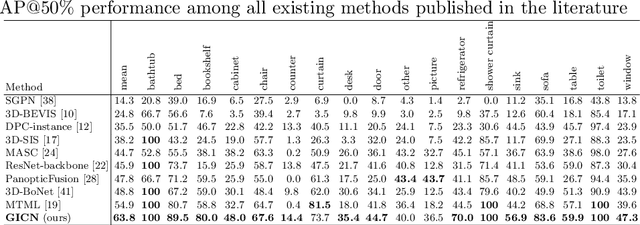
This paper presents a novel method for instance segmentation of 3D point clouds. The proposed method is called Gaussian Instance Center Network (GICN), which can approximate the distributions of instance centers scattered in the whole scene as Gaussian center heatmaps. Based on the predicted heatmaps, a small number of center candidates can be easily selected for the subsequent predictions with efficiency, including i) predicting the instance size of each center to decide a range for extracting features, ii) generating bounding boxes for centers, and iii) producing the final instance masks. GICN is a single-stage, anchor-free, and end-to-end architecture that is easy to train and efficient to perform inference. Benefited from the center-dictated mechanism with adaptive instance size selection, our method achieves state-of-the-art performance in the task of 3D instance segmentation on ScanNet and S3DIS datasets.
Silhouette-Net: 3D Hand Pose Estimation from Silhouettes
Dec 28, 2019

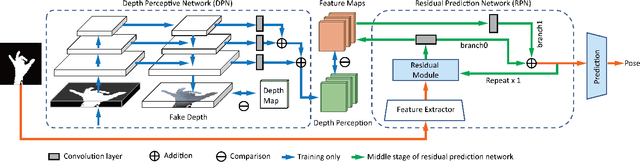
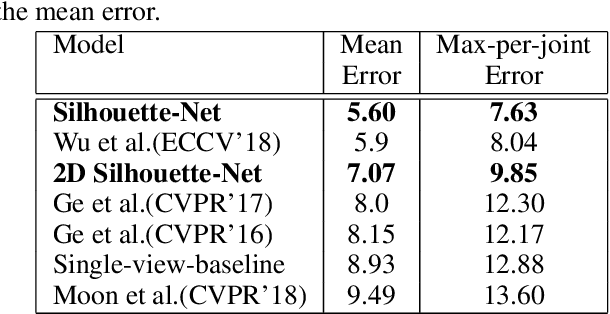
3D hand pose estimation has received a lot of attention for its wide range of applications and has made great progress owing to the development of deep learning. Existing approaches mainly consider different input modalities and settings, such as monocular RGB, multi-view RGB, depth, or point cloud, to provide sufficient cues for resolving variations caused by self occlusion and viewpoint change. In contrast, this work aims to address the less-explored idea of using minimal information to estimate 3D hand poses. We present a new architecture that automatically learns a guidance from implicit depth perception and solves the ambiguity of hand pose through end-to-end training. The experimental results show that 3D hand poses can be accurately estimated from solely {\em hand silhouettes} without using depth maps. Extensive evaluations on the {\em 2017 Hands In the Million Challenge} (HIM2017) benchmark dataset further demonstrate that our method achieves comparable or even better performance than recent depth-based approaches and serves as the state-of-the-art of its own kind on estimating 3D hand poses from silhouettes.
Learning to Distill: The Essence Vector Modeling Framework
Nov 22, 2016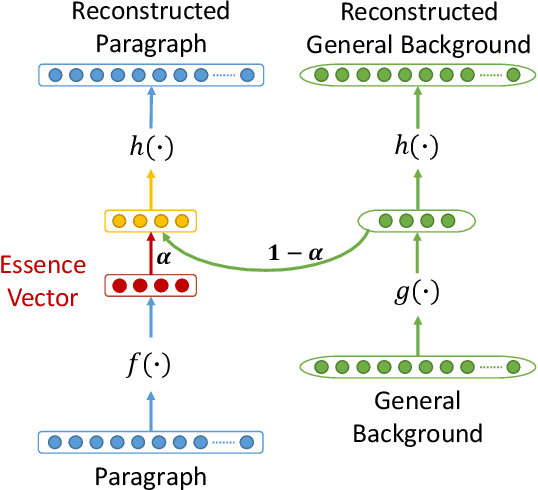
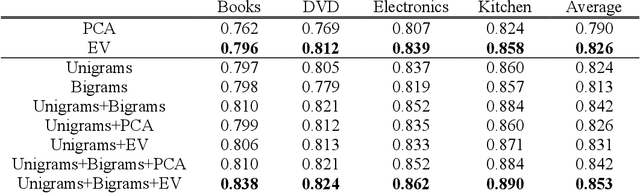
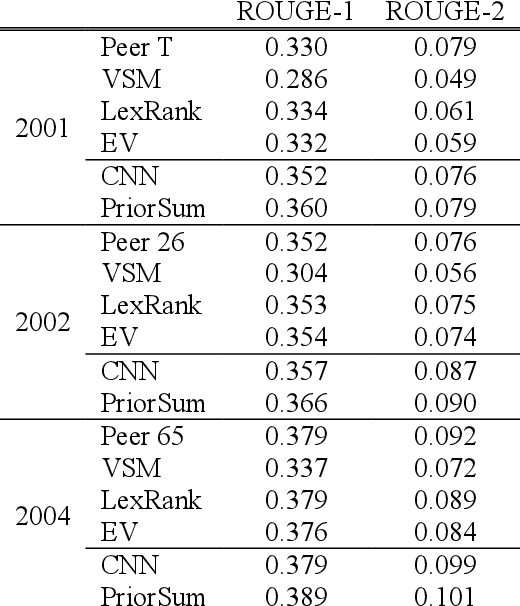
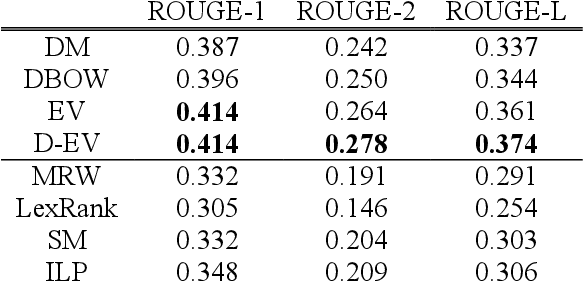
In the context of natural language processing, representation learning has emerged as a newly active research subject because of its excellent performance in many applications. Learning representations of words is a pioneering study in this school of research. However, paragraph (or sentence and document) embedding learning is more suitable/reasonable for some tasks, such as sentiment classification and document summarization. Nevertheless, as far as we are aware, there is relatively less work focusing on the development of unsupervised paragraph embedding methods. Classic paragraph embedding methods infer the representation of a given paragraph by considering all of the words occurring in the paragraph. Consequently, those stop or function words that occur frequently may mislead the embedding learning process to produce a misty paragraph representation. Motivated by these observations, our major contributions in this paper are twofold. First, we propose a novel unsupervised paragraph embedding method, named the essence vector (EV) model, which aims at not only distilling the most representative information from a paragraph but also excluding the general background information to produce a more informative low-dimensional vector representation for the paragraph. Second, in view of the increasing importance of spoken content processing, an extension of the EV model, named the denoising essence vector (D-EV) model, is proposed. The D-EV model not only inherits the advantages of the EV model but also can infer a more robust representation for a given spoken paragraph against imperfect speech recognition.
Novel Word Embedding and Translation-based Language Modeling for Extractive Speech Summarization
Jul 22, 2016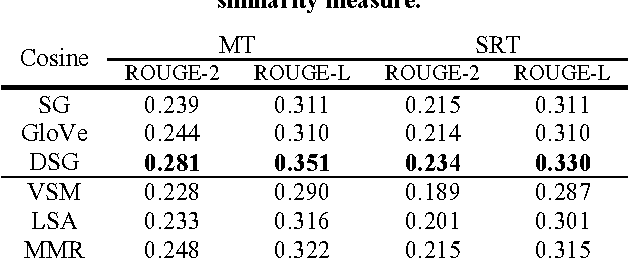
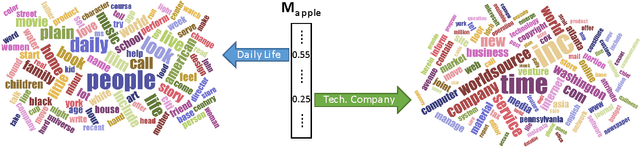


Word embedding methods revolve around learning continuous distributed vector representations of words with neural networks, which can capture semantic and/or syntactic cues, and in turn be used to induce similarity measures among words, sentences and documents in context. Celebrated methods can be categorized as prediction-based and count-based methods according to the training objectives and model architectures. Their pros and cons have been extensively analyzed and evaluated in recent studies, but there is relatively less work continuing the line of research to develop an enhanced learning method that brings together the advantages of the two model families. In addition, the interpretation of the learned word representations still remains somewhat opaque. Motivated by the observations and considering the pressing need, this paper presents a novel method for learning the word representations, which not only inherits the advantages of classic word embedding methods but also offers a clearer and more rigorous interpretation of the learned word representations. Built upon the proposed word embedding method, we further formulate a translation-based language modeling framework for the extractive speech summarization task. A series of empirical evaluations demonstrate the effectiveness of the proposed word representation learning and language modeling techniques in extractive speech summarization.
Improved Spoken Document Summarization with Coverage Modeling Techniques
Jan 20, 2016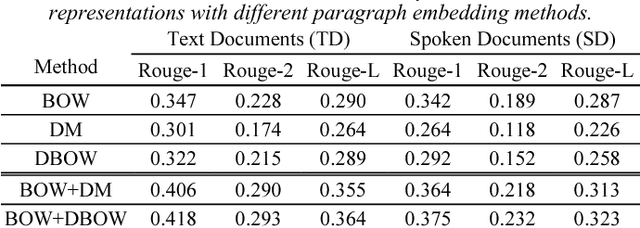
Extractive summarization aims at selecting a set of indicative sentences from a source document as a summary that can express the major theme of the document. A general consensus on extractive summarization is that both relevance and coverage are critical issues to address. The existing methods designed to model coverage can be characterized by either reducing redundancy or increasing diversity in the summary. Maximal margin relevance (MMR) is a widely-cited method since it takes both relevance and redundancy into account when generating a summary for a given document. In addition to MMR, there is only a dearth of research concentrating on reducing redundancy or increasing diversity for the spoken document summarization task, as far as we are aware. Motivated by these observations, two major contributions are presented in this paper. First, in contrast to MMR, which considers coverage by reducing redundancy, we propose two novel coverage-based methods, which directly increase diversity. With the proposed methods, a set of representative sentences, which not only are relevant to the given document but also cover most of the important sub-themes of the document, can be selected automatically. Second, we make a step forward to plug in several document/sentence representation methods into the proposed framework to further enhance the summarization performance. A series of empirical evaluations demonstrate the effectiveness of our proposed methods.
Leveraging Word Embeddings for Spoken Document Summarization
Jun 14, 2015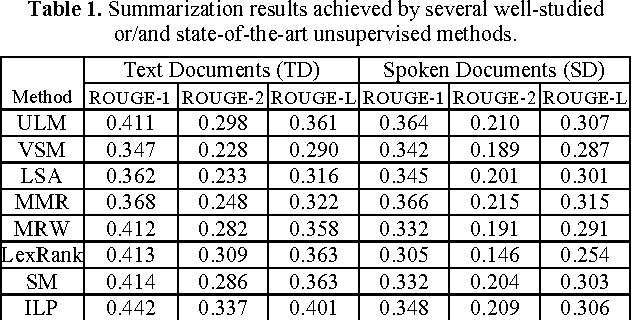
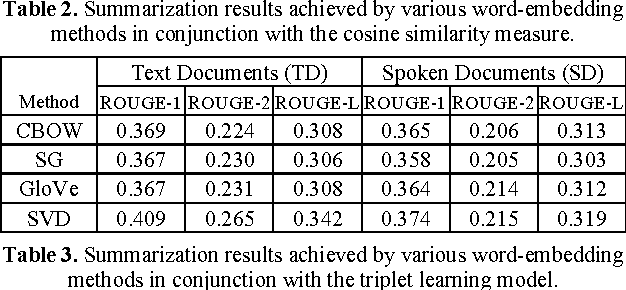
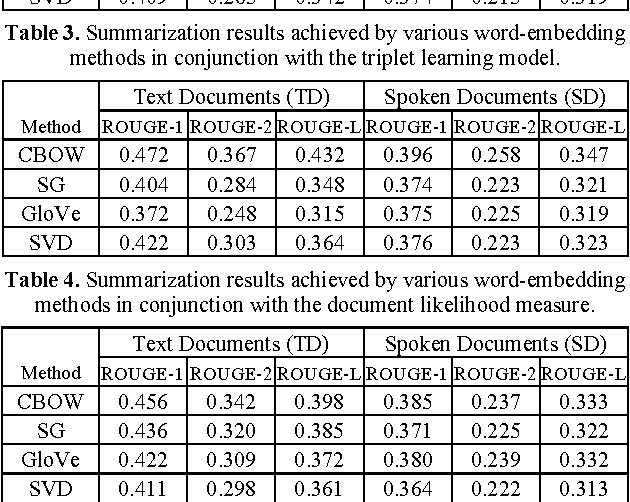
Owing to the rapidly growing multimedia content available on the Internet, extractive spoken document summarization, with the purpose of automatically selecting a set of representative sentences from a spoken document to concisely express the most important theme of the document, has been an active area of research and experimentation. On the other hand, word embedding has emerged as a newly favorite research subject because of its excellent performance in many natural language processing (NLP)-related tasks. However, as far as we are aware, there are relatively few studies investigating its use in extractive text or speech summarization. A common thread of leveraging word embeddings in the summarization process is to represent the document (or sentence) by averaging the word embeddings of the words occurring in the document (or sentence). Then, intuitively, the cosine similarity measure can be employed to determine the relevance degree between a pair of representations. Beyond the continued efforts made to improve the representation of words, this paper focuses on building novel and efficient ranking models based on the general word embedding methods for extractive speech summarization. Experimental results demonstrate the effectiveness of our proposed methods, compared to existing state-of-the-art methods.