 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilhouette-Net: 3D Hand Pose Estimation from Silhouettes
Dec 28, 2019

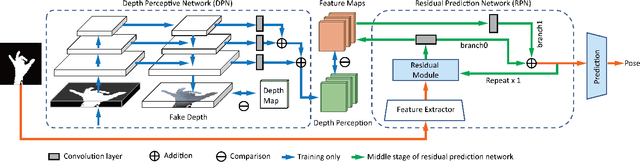
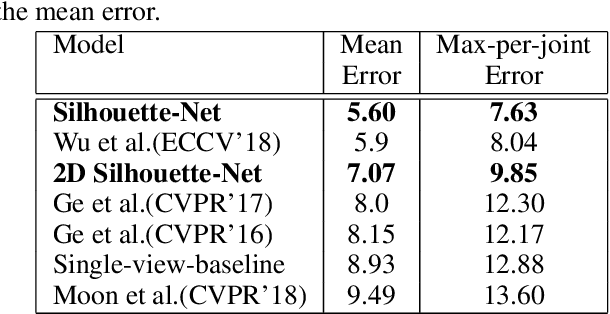
3D hand pose estimation has received a lot of attention for its wide range of applications and has made great progress owing to the development of deep learning. Existing approaches mainly consider different input modalities and settings, such as monocular RGB, multi-view RGB, depth, or point cloud, to provide sufficient cues for resolving variations caused by self occlusion and viewpoint change. In contrast, this work aims to address the less-explored idea of using minimal information to estimate 3D hand poses. We present a new architecture that automatically learns a guidance from implicit depth perception and solves the ambiguity of hand pose through end-to-end training. The experimental results show that 3D hand poses can be accurately estimated from solely {\em hand silhouettes} without using depth maps. Extensive evaluations on the {\em 2017 Hands In the Million Challenge} (HIM2017) benchmark dataset further demonstrate that our method achieves comparable or even better performance than recent depth-based approaches and serves as the state-of-the-art of its own kind on estimating 3D hand poses from silhouettes.