 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt is not always greener on the other side: Greenery perception across demographics and personalities in multiple cities
Dec 19, 2025Quantifying and assessing urban greenery is consequential for planning and development, reflecting the everlasting importance of green spaces for multiple climate and well-being dimensions of cities. Evaluation can be broadly grouped into objective (e.g., measuring the amount of greenery) and subjective (e.g., polling the perception of people) approaches, which may differ -- what people see and feel about how green a place is might not match the measurements of the actual amount of vegetation. In this work, we advance the state of the art by measuring such differences and explaining them through human, geographic, and spatial dimensions. The experiments rely on contextual information extracted from street view imagery and a comprehensive urban visual perception survey collected from 1,000 people across five countries with their extensive demographic and personality information. We analyze the discrepancies between objective measures (e.g., Green View Index (GVI)) and subjective scores (e.g., pairwise ratings), examining whether they can be explained by a variety of human and visual factors such as age group and spatial variation of greenery in the scene. The findings reveal that such discrepancies are comparable around the world and that demographics and personality do not play a significant role in perception. Further, while perceived and measured greenery correlate consistently across geographies (both where people and where imagery are from), where people live plays a significant role in explaining perceptual differences, with these two, as the top among seven, features that influences perceived greenery the most. This location influence suggests that cultural, environmental, and experiential factors substantially shape how individuals observe greenery in cities.
Leveraging Intermediate Features of Vision Transformer for Face Anti-Spoofing
May 30, 2025Face recognition systems are designed to be robust against changes in head pose, illumination, and blurring during image capture. If a malicious person presents a face photo of the registered user, they may bypass the authentication process illegally. Such spoofing attacks need to be detected before face recognition. In this paper, we propose a spoofing attack detection method based on Vision Transformer (ViT) to detect minute differences between live and spoofed face images. The proposed method utilizes the intermediate features of ViT, which have a good balance between local and global features that are important for spoofing attack detection, for calculating loss in training and score in inference. The proposed method also introduces two data augmentation methods: face anti-spoofing data augmentation and patch-wise data augmentation, to improve the accuracy of spoofing attack detection. We demonstrate the effectiveness of the proposed method through experiments using the OULU-NPU and SiW datasets.
Stereo Radargrammetry Using Deep Learning from Airborne SAR Images
May 29, 2025In this paper, we propose a stereo radargrammetry method using deep learning from airborne Synthetic Aperture Radar (SAR) images. Deep learning-based methods are considered to suffer less from geometric image modulation, while there is no public SAR image dataset used to train such methods. We create a SAR image dataset and perform fine-tuning of a deep learning-based image correspondence method. The proposed method suppresses the degradation of image quality by pixel interpolation without ground projection of the SAR image and divides the SAR image into patches for processing, which makes it possible to apply deep learning. Through a set of experiments, we demonstrate that the proposed method exhibits a wider range and more accurate elevation measurements compared to conventional methods. The project web page is available at: https://gsisaoki.github.io/IGARSS2025_sasayama/
ErpGS: Equirectangular Image Rendering enhanced with 3D Gaussian Regularization
May 26, 2025



The use of multi-view images acquired by a 360-degree camera can reconstruct a 3D space with a wide area. There are 3D reconstruction methods from equirectangular images based on NeRF and 3DGS, as well as Novel View Synthesis (NVS) methods. On the other hand, it is necessary to overcome the large distortion caused by the projection model of a 360-degree camera when equirectangular images are used. In 3DGS-based methods, the large distortion of the 360-degree camera model generates extremely large 3D Gaussians, resulting in poor rendering accuracy. We propose ErpGS, which is Omnidirectional GS based on 3DGS to realize NVS addressing the problems. ErpGS introduce some rendering accuracy improvement techniques: geometric regularization, scale regularization, and distortion-aware weights and a mask to suppress the effects of obstacles in equirectangular images. Through experiments on public datasets, we demonstrate that ErpGS can render novel view images more accurately than conventional methods.
Sparse2DGS: Sparse-View Surface Reconstruction using 2D Gaussian Splatting with Dense Point Cloud
May 26, 2025Gaussian Splatting (GS) has gained attention as a fast and effective method for novel view synthesis. It has also been applied to 3D reconstruction using multi-view images and can achieve fast and accurate 3D reconstruction. However, GS assumes that the input contains a large number of multi-view images, and therefore, the reconstruction accuracy significantly decreases when only a limited number of input images are available. One of the main reasons is the insufficient number of 3D points in the sparse point cloud obtained through Structure from Motion (SfM), which results in a poor initialization for optimizing the Gaussian primitives. We propose a new 3D reconstruction method, called Sparse2DGS, to enhance 2DGS in reconstructing objects using only three images. Sparse2DGS employs DUSt3R, a fundamental model for stereo images, along with COLMAP MVS to generate highly accurate and dense 3D point clouds, which are then used to initialize 2D Gaussians. Through experiments on the DTU dataset, we show that Sparse2DGS can accurately reconstruct the 3D shapes of objects using just three images.
OB3D: A New Dataset for Benchmarking Omnidirectional 3D Reconstruction Using Blender
May 26, 2025


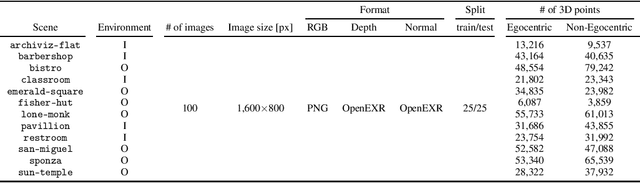
Recent advancements in radiance field rendering, exemplified by Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have significantly progressed 3D modeling and reconstruction. The use of multiple 360-degree omnidirectional images for these tasks is increasingly favored due to advantages in data acquisition and comprehensive scene capture. However, the inherent geometric distortions in common omnidirectional representations, such as equirectangular projection (particularly severe in polar regions and varying with latitude), pose substantial challenges to achieving high-fidelity 3D reconstructions. Current datasets, while valuable, often lack the specific focus, scene composition, and ground truth granularity required to systematically benchmark and drive progress in overcoming these omnidirectional-specific challenges. To address this critical gap, we introduce Omnidirectional Blender 3D (OB3D), a new synthetic dataset curated for advancing 3D reconstruction from multiple omnidirectional images. OB3D features diverse and complex 3D scenes generated from Blender 3D projects, with a deliberate emphasis on challenging scenarios. The dataset provides comprehensive ground truth, including omnidirectional RGB images, precise omnidirectional camera parameters, and pixel-aligned equirectangular maps for depth and normals, alongside evaluation metrics. By offering a controlled yet challenging environment, OB3Daims to facilitate the rigorous evaluation of existing methods and prompt the development of new techniques to enhance the accuracy and reliability of 3D reconstruction from omnidirectional images.
Zero-Shot Pseudo Labels Generation Using SAM and CLIP for Semi-Supervised Semantic Segmentation
May 26, 2025Semantic segmentation is a fundamental task in medical image analysis and autonomous driving and has a problem with the high cost of annotating the labels required in training. To address this problem, semantic segmentation methods based on semi-supervised learning with a small number of labeled data have been proposed. For example, one approach is to train a semantic segmentation model using images with annotated labels and pseudo labels. In this approach, the accuracy of the semantic segmentation model depends on the quality of the pseudo labels, and the quality of the pseudo labels depends on the performance of the model to be trained and the amount of data with annotated labels. In this paper, we generate pseudo labels using zero-shot annotation with the Segment Anything Model (SAM) and Contrastive Language-Image Pretraining (CLIP), improve the accuracy of the pseudo labels using the Unified Dual-Stream Perturbations Approach (UniMatch), and use them as enhanced labels to train a semantic segmentation model. The effectiveness of the proposed method is demonstrated through the experiments using the public datasets: PASCAL and MS COCO.
It's not you, it's me -- Global urban visual perception varies across demographics and personalities
May 19, 2025Understanding people's preferences and needs is crucial for urban planning decisions, yet current approaches often combine them from multi-cultural and multi-city populations, obscuring important demographic differences and risking amplifying biases. We conducted a large-scale urban visual perception survey of streetscapes worldwide using street view imagery, examining how demographics -- including gender, age, income, education, race and ethnicity, and, for the first time, personality traits -- shape perceptions among 1,000 participants, with balanced demographics, from five countries and 45 nationalities. This dataset, introduced as Street Perception Evaluation Considering Socioeconomics (SPECS), exhibits statistically significant differences in perception scores in six traditionally used indicators (safe, lively, wealthy, beautiful, boring, and depressing) and four new ones we propose (live nearby, walk, cycle, green) among demographics and personalities. We revealed that location-based sentiments are carried over in people's preferences when comparing urban streetscapes with other cities. Further, we compared the perception scores based on where participants and streetscapes are from. We found that an off-the-shelf machine learning model trained on an existing global perception dataset tends to overestimate positive indicators and underestimate negative ones compared to human responses, suggesting that targeted intervention should consider locals' perception. Our study aspires to rectify the myopic treatment of street perception, which rarely considers demographics or personality traits.
ZenSVI: An Open-Source Software for the Integrated Acquisition, Processing and Analysis of Street View Imagery Towards Scalable Urban Science
Dec 24, 2024Street view imagery (SVI) has been instrumental in many studies in the past decade to understand and characterize street features and the built environment. Researchers across a variety of domains, such as transportation, health, architecture, human perception, and infrastructure have employed different methods to analyze SVI. However, these applications and image-processing procedures have not been standardized, and solutions have been implemented in isolation, often making it difficult for others to reproduce existing work and carry out new research. Using SVI for research requires multiple technical steps: accessing APIs for scalable data collection, preprocessing images to standardize formats, implementing computer vision models for feature extraction, and conducting spatial analysis. These technical requirements create barriers for researchers in urban studies, particularly those without extensive programming experience. We develop ZenSVI, a free and open-source Python package that integrates and implements the entire process of SVI analysis, supporting a wide range of use cases. Its end-to-end pipeline includes downloading SVI from multiple platforms (e.g., Mapillary and KartaView) efficiently, analyzing metadata of SVI, applying computer vision models to extract target features, transforming SVI into different projections (e.g., fish-eye and perspective) and different formats (e.g., depth map and point cloud), visualizing analyses with maps and plots, and exporting outputs to other software tools. We demonstrate its use in Singapore through a case study of data quality assessment and clustering analysis in a streamlined manner. Our software improves the transparency, reproducibility, and scalability of research relying on SVI and supports researchers in conducting urban analyses efficiently. Its modular design facilitates extensions and unlocking new use cases.
Enhancing Remote Adversarial Patch Attacks on Face Detectors with Tiling and Scaling
Dec 11, 2024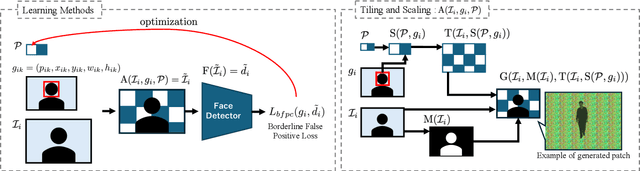
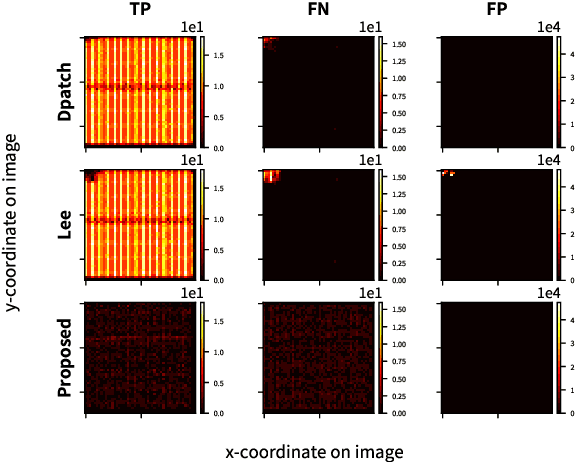
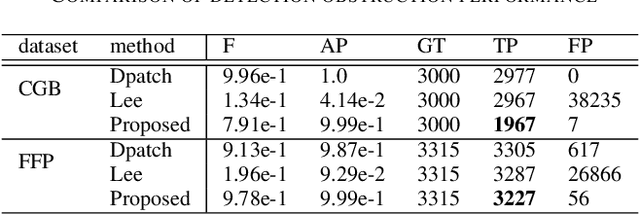
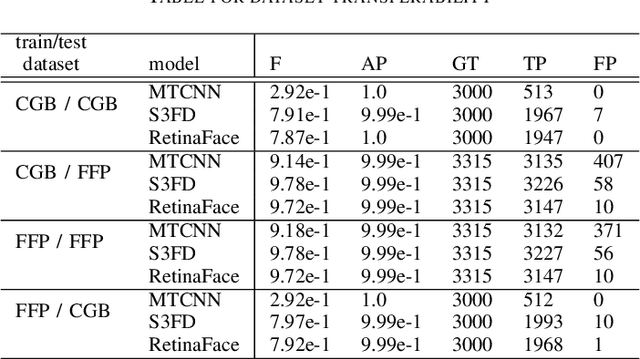
This paper discusses the attack feasibility of Remote Adversarial Patch (RAP) targeting face detectors. The RAP that targets face detectors is similar to the RAP that targets general object detectors, but the former has multiple issues in the attack process the latter does not. (1) It is possible to detect objects of various scales. In particular, the area of small objects that are convolved during feature extraction by CNN is small,so the area that affects the inference results is also small. (2) It is a two-class classification, so there is a large gap in characteristics between the classes. This makes it difficult to attack the inference results by directing them to a different class. In this paper, we propose a new patch placement method and loss function for each problem. The patches targeting the proposed face detector showed superior detection obstruct effects compared to the patches targeting the general object detector.