 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Intermediate Features of Vision Transformer for Face Anti-Spoofing
May 30, 2025Face recognition systems are designed to be robust against changes in head pose, illumination, and blurring during image capture. If a malicious person presents a face photo of the registered user, they may bypass the authentication process illegally. Such spoofing attacks need to be detected before face recognition. In this paper, we propose a spoofing attack detection method based on Vision Transformer (ViT) to detect minute differences between live and spoofed face images. The proposed method utilizes the intermediate features of ViT, which have a good balance between local and global features that are important for spoofing attack detection, for calculating loss in training and score in inference. The proposed method also introduces two data augmentation methods: face anti-spoofing data augmentation and patch-wise data augmentation, to improve the accuracy of spoofing attack detection. We demonstrate the effectiveness of the proposed method through experiments using the OULU-NPU and SiW datasets.
Enhancing Remote Adversarial Patch Attacks on Face Detectors with Tiling and Scaling
Dec 11, 2024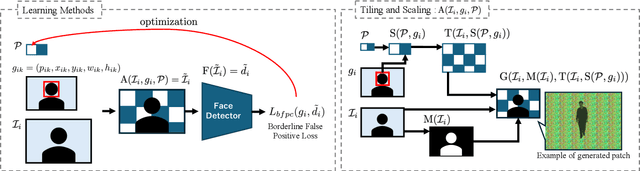
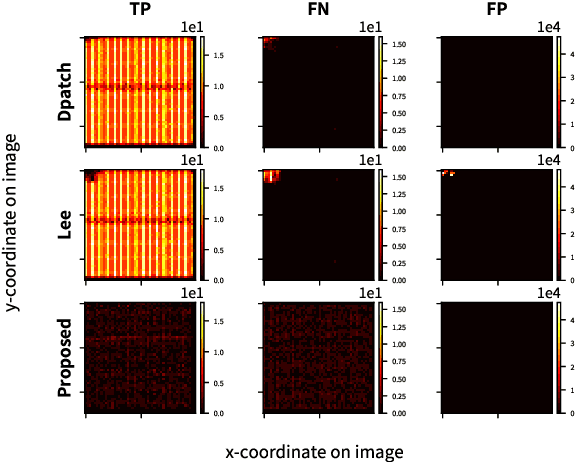
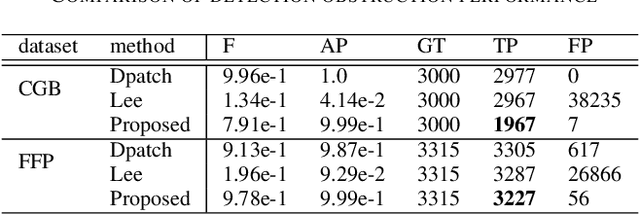
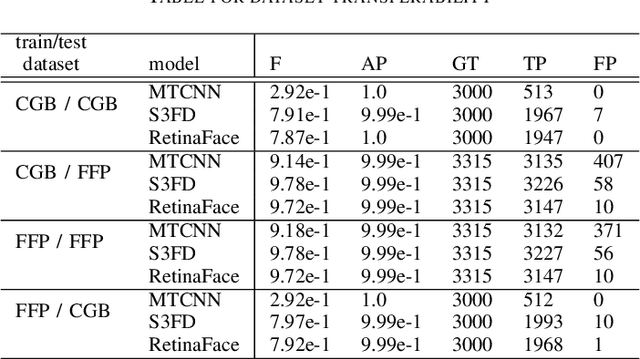
This paper discusses the attack feasibility of Remote Adversarial Patch (RAP) targeting face detectors. The RAP that targets face detectors is similar to the RAP that targets general object detectors, but the former has multiple issues in the attack process the latter does not. (1) It is possible to detect objects of various scales. In particular, the area of small objects that are convolved during feature extraction by CNN is small,so the area that affects the inference results is also small. (2) It is a two-class classification, so there is a large gap in characteristics between the classes. This makes it difficult to attack the inference results by directing them to a different class. In this paper, we propose a new patch placement method and loss function for each problem. The patches targeting the proposed face detector showed superior detection obstruct effects compared to the patches targeting the general object detector.
Multibiometrics Using a Single Face Image
Sep 30, 2024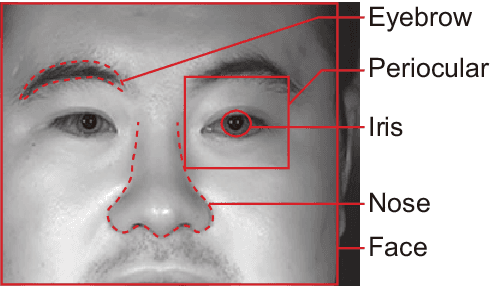
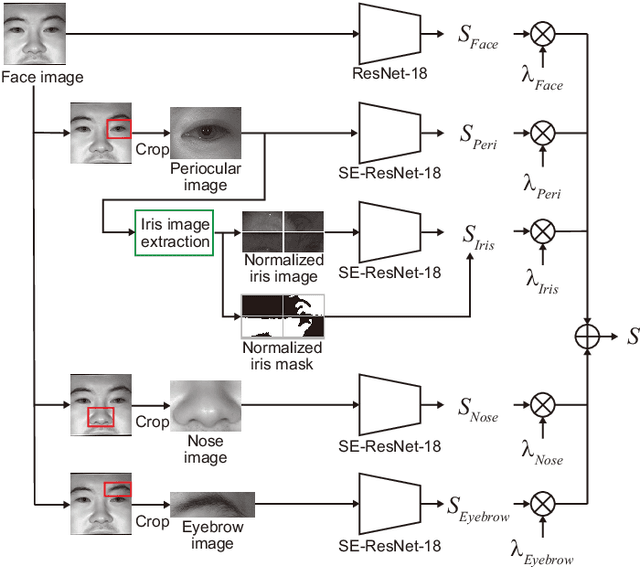

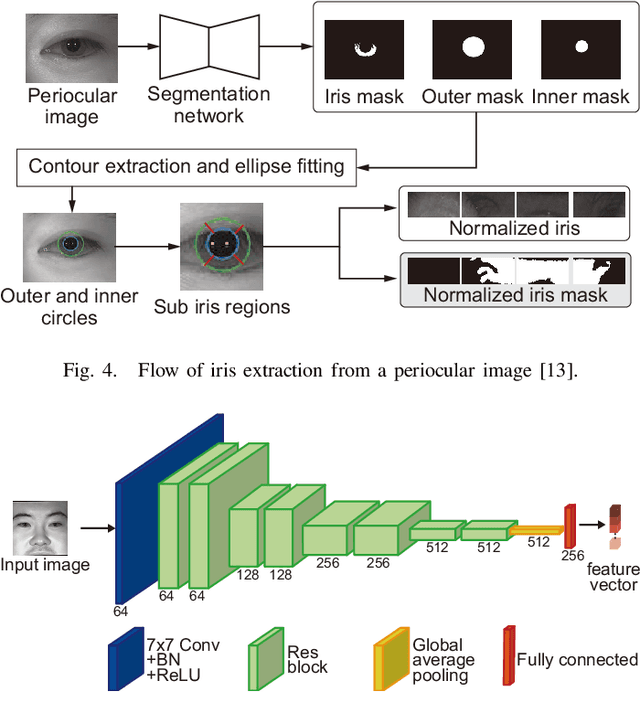
Multibiometrics, which uses multiple biometric traits to improve recognition performance instead of using only one biometric trait to authenticate individuals, has been investigated. Previous studies have combined individually acquired biometric traits or have not fully considered the convenience of the system.Focusing on a single face image, we propose a novel multibiometric method that combines five biometric traits, i.e., face, iris, periocular, nose, eyebrow, that can be extracted from a single face image. The proposed method does not sacrifice the convenience of biometrics since only a single face image is used as input.Through a variety of experiments using the CASIA Iris Distance database, we demonstrate the effectiveness of the proposed multibiometrics method.
LabellessFace: Fair Metric Learning for Face Recognition without Attribute Labels
Sep 14, 2024



Demographic bias is one of the major challenges for face recognition systems. The majority of existing studies on demographic biases are heavily dependent on specific demographic groups or demographic classifier, making it difficult to address performance for unrecognised groups. This paper introduces ``LabellessFace'', a novel framework that improves demographic bias in face recognition without requiring demographic group labeling typically required for fairness considerations. We propose a novel fairness enhancement metric called the class favoritism level, which assesses the extent of favoritism towards specific classes across the dataset. Leveraging this metric, we introduce the fair class margin penalty, an extension of existing margin-based metric learning. This method dynamically adjusts learning parameters based on class favoritism levels, promoting fairness across all attributes. By treating each class as an individual in facial recognition systems, we facilitate learning that minimizes biases in authentication accuracy among individuals. Comprehensive experiments have demonstrated that our proposed method is effective for enhancing fairness while maintaining authentication accuracy.
PDH : Probabilistic deep hashing based on MAP estimation of Hamming distance
May 21, 2019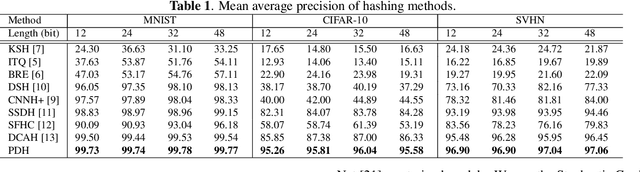
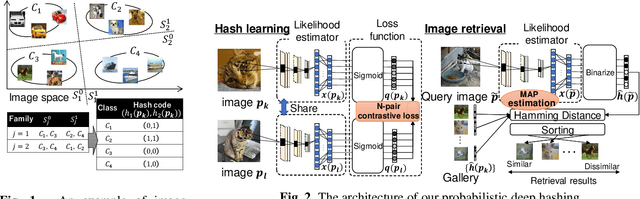
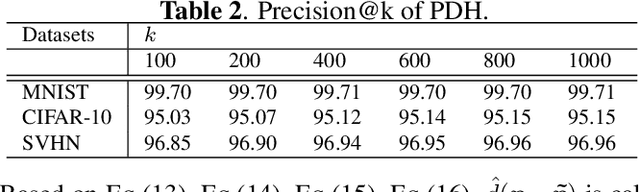
With the growth of image on the web, research on hashing which enables high-speed image retrieval has been actively studied. In recent years, various hashing methods based on deep neural networks have been proposed and achieved higher precision than the other hashing methods. In these methods, multiple losses for hash codes and the parameters of neural networks are defined. They generate hash codes that minimize the weighted sum of the losses. Therefore, an expert has to tune the weights for the losses heuristically, and the probabilistic optimality of the loss function cannot be explained. In order to generate explainable hash codes without weight tuning, we theoretically derive a single loss function with no hyperparameters for the hash code from the probability distribution of the images. By generating hash codes that minimize this loss function, highly accurate image retrieval with probabilistic optimality is performed. We evaluate the performance of hashing using MNIST, CIFAR-10, SVHN and show that the proposed method outperforms the state-of-the-art hashing methods.