 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Temperature for Language Modeling
Dec 25, 2020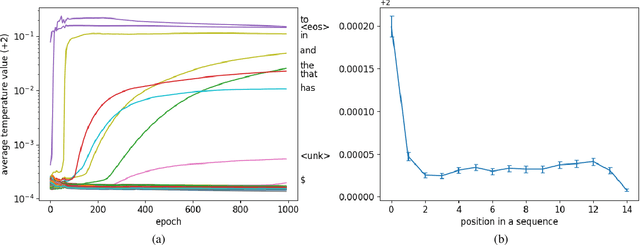
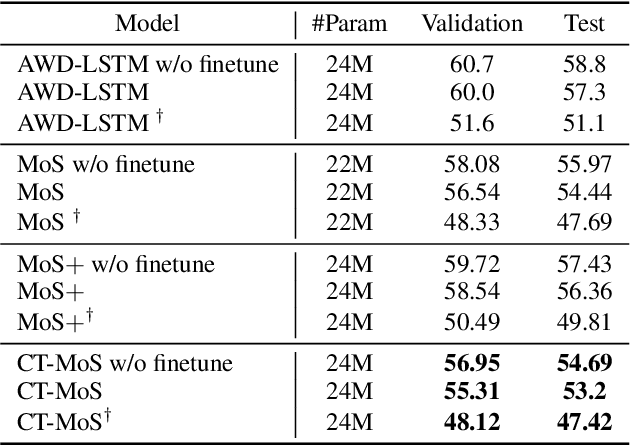
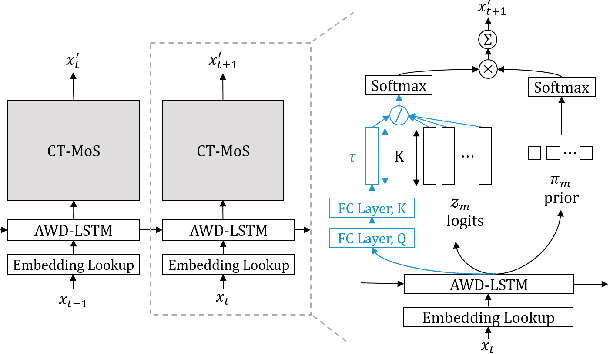
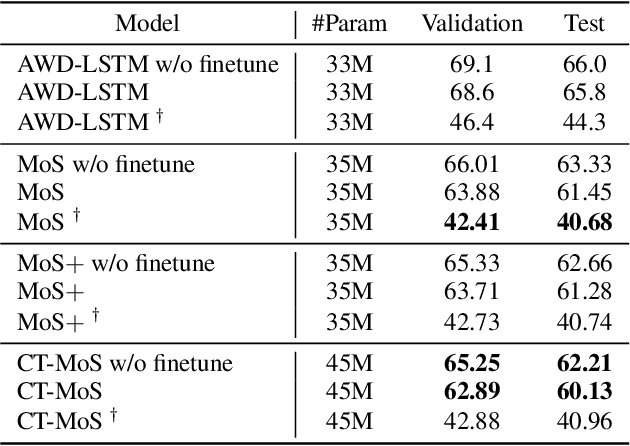
Temperature scaling has been widely used as an effective approach to control the smoothness of a distribution, which helps the model performance in various tasks. Current practices to apply temperature scaling assume either a fixed, or a manually-crafted dynamically changing schedule. However, our studies indicate that the individual optimal trajectory for each class can change with the context. To this end, we propose contextual temperature, a generalized approach that learns an optimal temperature trajectory for each vocabulary over the context. Experimental results confirm that the proposed method significantly improves state-of-the-art language models, achieving a perplexity of 55.31 and 62.89 on the test set of Penn Treebank and WikiText-2, respectively. In-depth analyses show that the behaviour of the learned temperature schedules varies dramatically by vocabulary, and that the optimal schedules help in controlling the uncertainties. These evidences further justify the need for the proposed method and its advantages over fixed temperature schedules.
Calibrated BatchNorm: Improving Robustness Against Noisy Weights in Neural Networks
Jul 07, 2020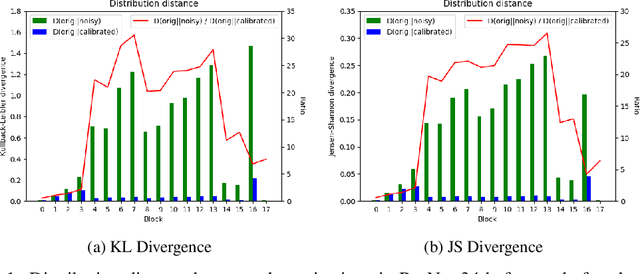
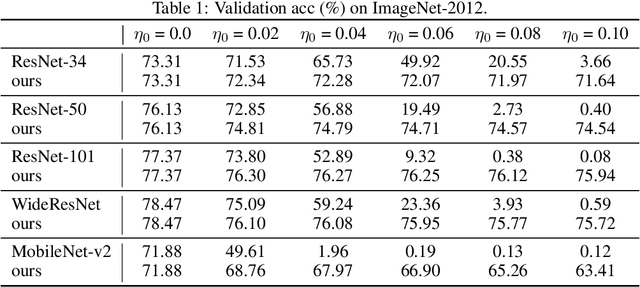


Analog computing hardware has gradually received more attention by the researchers for accelerating the neural network computations in recent years. However, the analog accelerators often suffer from the undesirable intrinsic noise caused by the physical components, making the neural networks challenging to achieve ordinary performance as on the digital ones. We suppose the performance drop of the noisy neural networks is due to the distribution shifts in the network activations. In this paper, we propose to recalculate the statistics of the batch normalization layers to calibrate the biased distributions during the inference phase. Without the need of knowing the attributes of the noise beforehand, our approach is able to align the distributions of the activations under variational noise inherent in the analog environments. In order to validate our assumptions, we conduct quantitative experiments and apply our methods on several computer vision tasks, including classification, object detection, and semantic segmentation. The results demonstrate the effectiveness of achieving noise-agnostic robust networks and progress the developments of the analog computing devices in the field of neural networks.
Learning with Hierarchical Complement Objective
Nov 17, 2019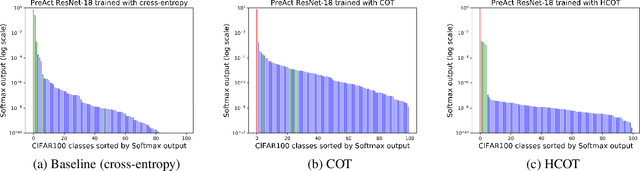
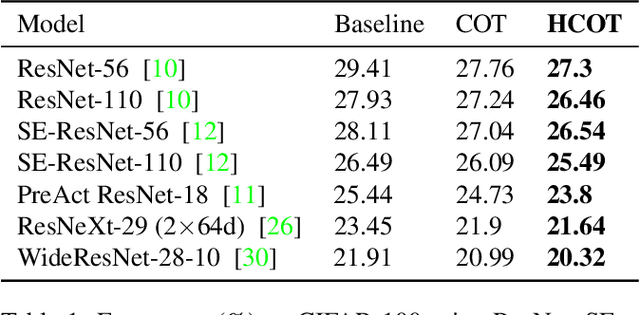
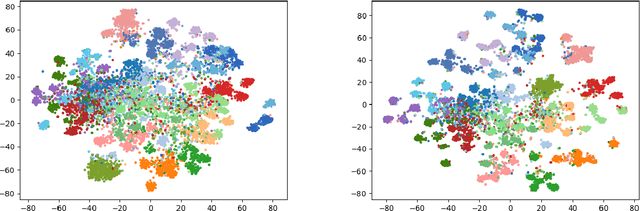
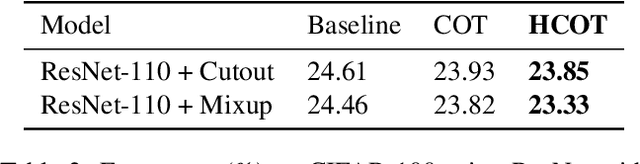
Label hierarchies widely exist in many vision-related problems, ranging from explicit label hierarchies existed in image classification to latent label hierarchies existed in semantic segmentation. Nevertheless, state-of-the-art methods often deploy cross-entropy loss that implicitly assumes class labels to be exclusive and thus independence from each other. Motivated by the fact that classes from the same parental category usually share certain similarity, we design a new training diagram called Hierarchical Complement Objective Training (HCOT) that leverages the information from label hierarchy. HCOT maximizes the probability of the ground truth class, and at the same time, neutralizes the probabilities of rest of the classes in a hierarchical fashion, making the model take advantage of the label hierarchy explicitly. The proposed HCOT is evaluated on both image classification and semantic segmentation tasks. Experimental results confirm that HCOT outperforms state-of-the-art models in CIFAR-100, ImageNet-2012, and PASCAL-Context. The study further demonstrates that HCOT can be applied on tasks with latent label hierarchies, which is a common characteristic in many machine learning tasks.
Improving Adversarial Robustness via Guided Complement Entropy
Mar 23, 2019


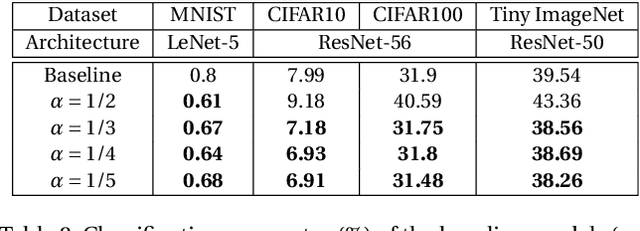
Model robustness has been an important issue, since adding small adversarial perturbations to images is sufficient to drive the model accuracy down to nearly zero. In this paper, we propose a new training objective "Guided Complement Entropy" (GCE) that has dual desirable effects: (a) neutralizing the predicted probabilities of incorrect classes, and (b) maximizing the predicted probability of the ground-truth class, particularly when (a) is achieved. Training with GCE encourages models to learn latent representations where samples of different classes form distinct clusters, which we argue, improves the model robustness against adversarial perturbations. Furthermore, compared with the state-of-the-arts trained with cross-entropy, same models trained with GCE achieve significant improvements on the robustness against white-box adversarial attacks, both with and without adversarial training. When no attack is present, training with GCE also outperforms cross-entropy in terms of model accuracy.
Complement Objective Training
Mar 21, 2019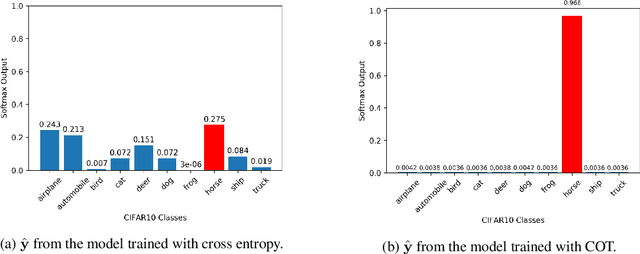
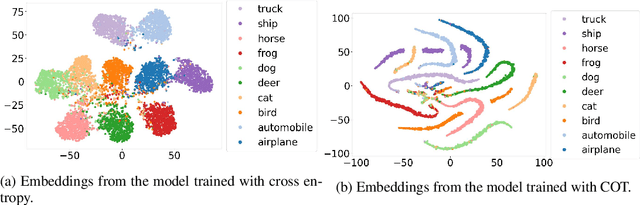
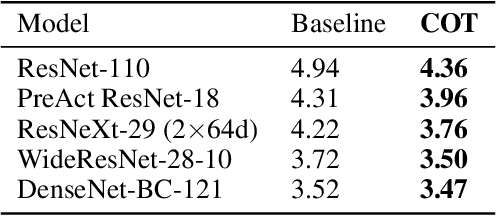

Learning with a primary objective, such as softmax cross entropy for classification and sequence generation, has been the norm for training deep neural networks for years. Although being a widely-adopted approach, using cross entropy as the primary objective exploits mostly the information from the ground-truth class for maximizing data likelihood, and largely ignores information from the complement (incorrect) classes. We argue that, in addition to the primary objective, training also using a complement objective that leverages information from the complement classes can be effective in improving model performance. This motivates us to study a new training paradigm that maximizes the likelihood of the groundtruth class while neutralizing the probabilities of the complement classes. We conduct extensive experiments on multiple tasks ranging from computer vision to natural language understanding. The experimental results confirm that, compared to the conventional training with just one primary objective, training also with the complement objective further improves the performance of the state-of-the-art models across all tasks. In addition to the accuracy improvement, we also show that models trained with both primary and complement objectives are more robust to single-step adversarial attacks.
Searching Toward Pareto-Optimal Device-Aware Neural Architectures
Aug 30, 2018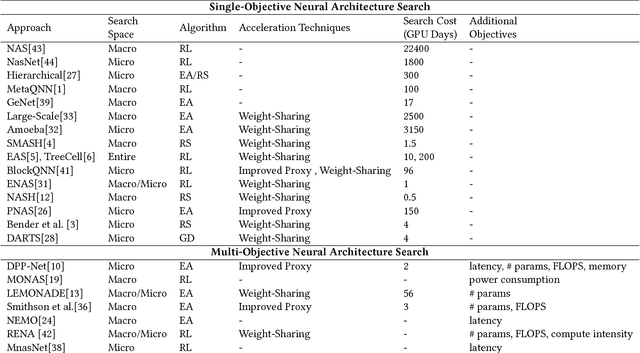
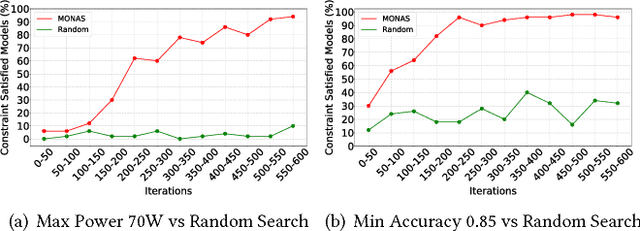
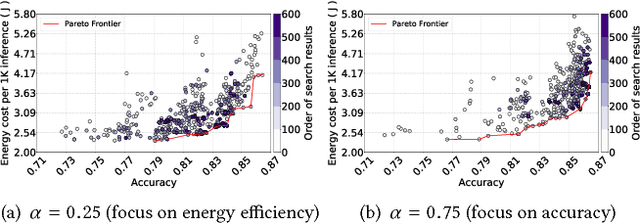
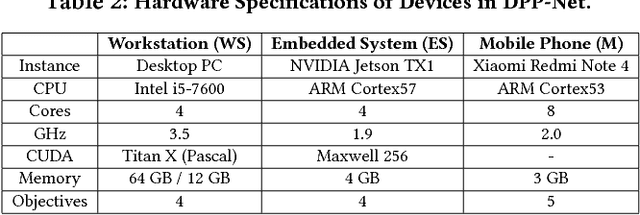
Recent breakthroughs in Neural Architectural Search (NAS) have achieved state-of-the-art performance in many tasks such as image classification and language understanding. However, most existing works only optimize for model accuracy and largely ignore other important factors imposed by the underlying hardware and devices, such as latency and energy, when making inference. In this paper, we first introduce the problem of NAS and provide a survey on recent works. Then we deep dive into two recent advancements on extending NAS into multiple-objective frameworks: MONAS and DPP-Net. Both MONAS and DPP-Net are capable of optimizing accuracy and other objectives imposed by devices, searching for neural architectures that can be best deployed on a wide spectrum of devices: from embedded systems and mobile devices to workstations. Experimental results are poised to show that architectures found by MONAS and DPP-Net achieves Pareto optimality w.r.t the given objectives for various devices.
Leveraging Motion Priors in Videos for Improving Human Segmentation
Jul 30, 2018


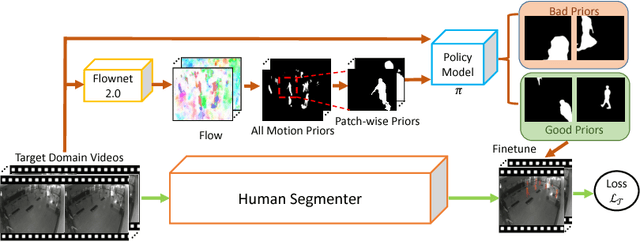
Despite many advances in deep-learning based semantic segmentation, performance drop due to distribution mismatch is often encountered in the real world. Recently, a few domain adaptation and active learning approaches have been proposed to mitigate the performance drop. However, very little attention has been made toward leveraging information in videos which are naturally captured in most camera systems. In this work, we propose to leverage "motion prior" in videos for improving human segmentation in a weakly-supervised active learning setting. By extracting motion information using optical flow in videos, we can extract candidate foreground motion segments (referred to as motion prior) potentially corresponding to human segments. We propose to learn a memory-network-based policy model to select strong candidate segments (referred to as strong motion prior) through reinforcement learning. The selected segments have high precision and are directly used to finetune the model. In a newly collected surveillance camera dataset and a publicly available UrbanStreet dataset, our proposed method improves the performance of human segmentation across multiple scenes and modalities (i.e., RGB to Infrared (IR)). Last but not least, our method is empirically complementary to existing domain adaptation approaches such that additional performance gain is achieved by combining our weakly-supervised active learning approach with domain adaptation approaches.
MONAS: Multi-Objective Neural Architecture Search using Reinforcement Learning
Jun 27, 2018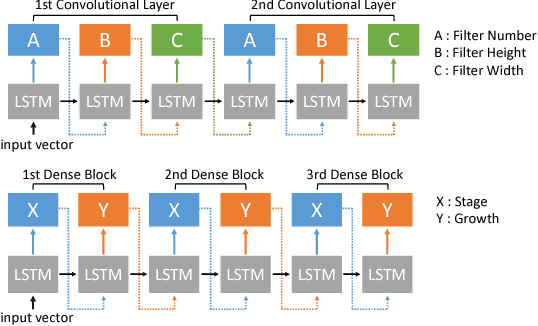
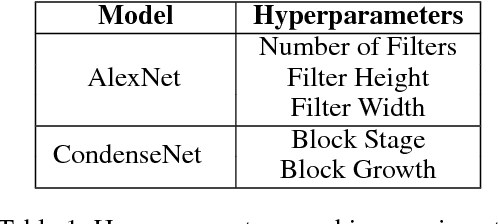
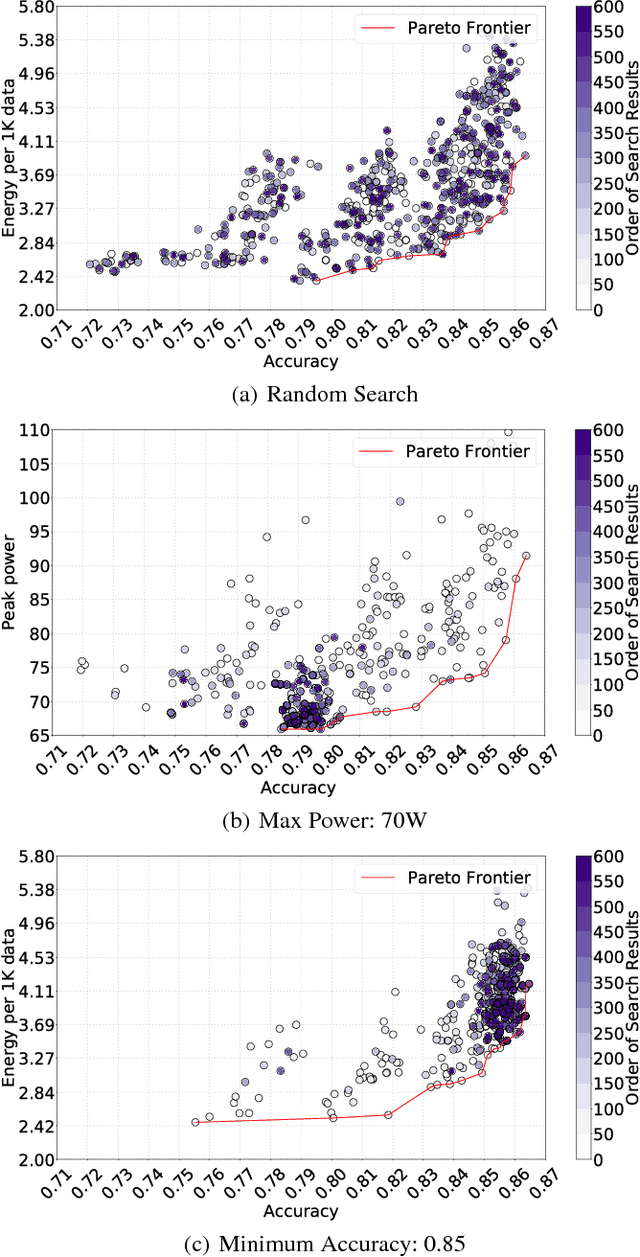
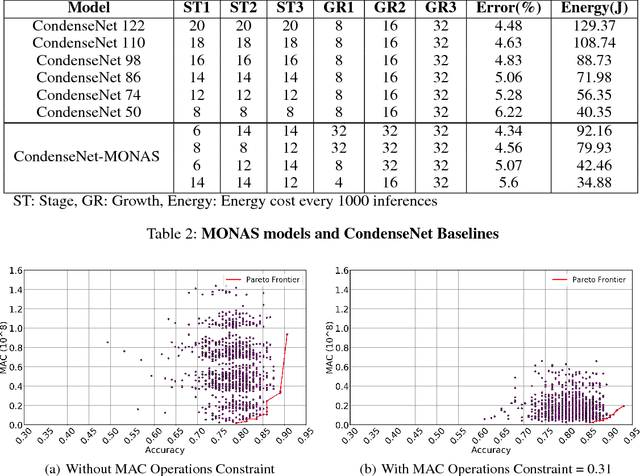
Recent studies on neural architecture search have shown that automatically designed neural networks perform as good as human-designed architectures. While most existing works on neural architecture search aim at finding architectures that optimize for prediction accuracy. These methods may generate complex architectures consuming excessively high energy consumption, which is not suitable for computing environment with limited power budgets. We propose MONAS, a Multi-Objective Neural Architecture Search with novel reward functions that consider both prediction accuracy and power consumption when exploring neural architectures. MONAS effectively explores the design space and searches for architectures satisfying the given requirements. The experimental results demonstrate that the architectures found by MONAS achieve accuracy comparable to or better than the state-of-the-art models, while having better energy efficiency.
DC-Prophet: Predicting Catastrophic Machine Failures in DataCenters
Aug 14, 2017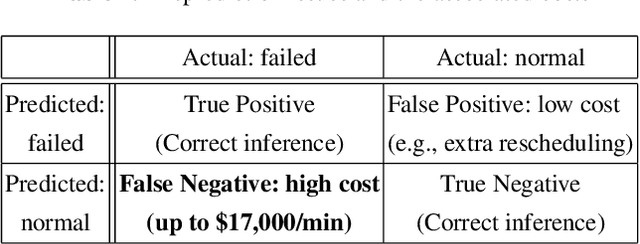

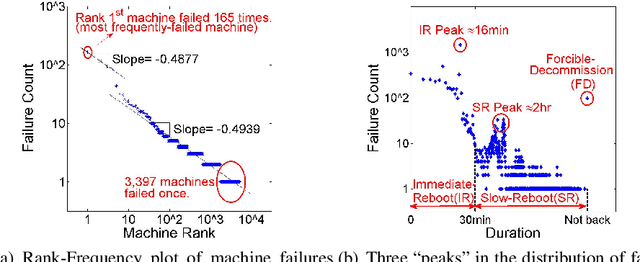

When will a server fail catastrophically in an industrial datacenter? Is it possible to forecast these failures so preventive actions can be taken to increase the reliability of a datacenter? To answer these questions, we have studied what are probably the largest, publicly available datacenter traces, containing more than 104 million events from 12,500 machines. Among these samples, we observe and categorize three types of machine failures, all of which are catastrophic and may lead to information loss, or even worse, reliability degradation of a datacenter. We further propose a two-stage framework-DC-Prophet-based on One-Class Support Vector Machine and Random Forest. DC-Prophet extracts surprising patterns and accurately predicts the next failure of a machine. Experimental results show that DC-Prophet achieves an AUC of 0.93 in predicting the next machine failure, and a F3-score of 0.88 (out of 1). On average, DC-Prophet outperforms other classical machine learning methods by 39.45% in F3-score.
No More Discrimination: Cross City Adaptation of Road Scene Segmenters
Apr 27, 2017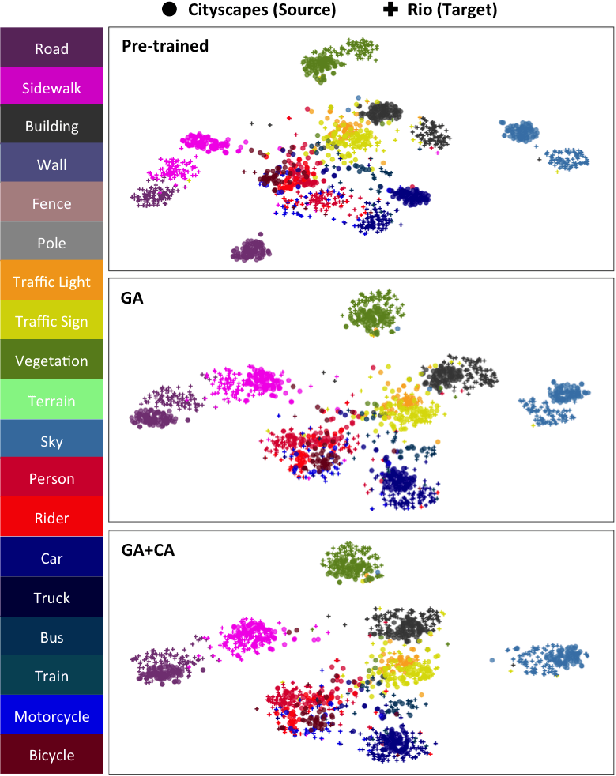
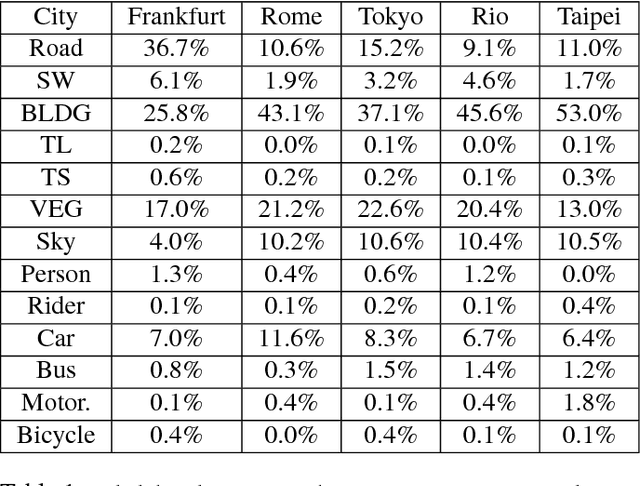

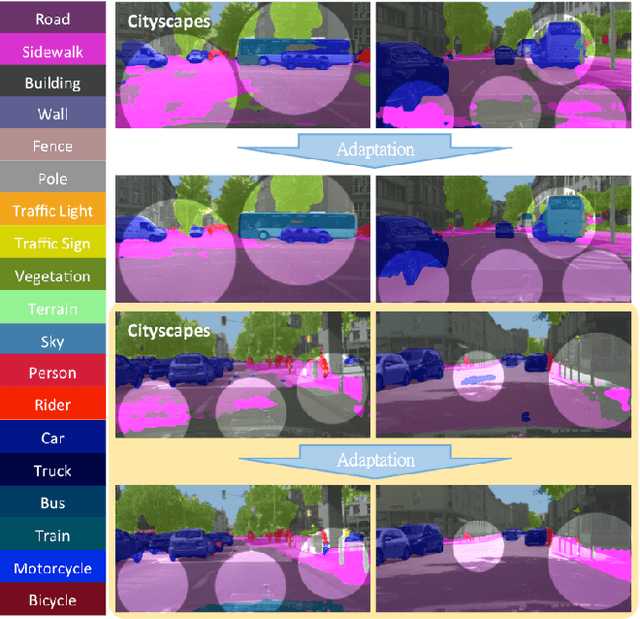
Despite the recent success of deep-learning based semantic segmentation, deploying a pre-trained road scene segmenter to a city whose images are not presented in the training set would not achieve satisfactory performance due to dataset biases. Instead of collecting a large number of annotated images of each city of interest to train or refine the segmenter, we propose an unsupervised learning approach to adapt road scene segmenters across different cities. By utilizing Google Street View and its time-machine feature, we can collect unannotated images for each road scene at different times, so that the associated static-object priors can be extracted accordingly. By advancing a joint global and class-specific domain adversarial learning framework, adaptation of pre-trained segmenters to that city can be achieved without the need of any user annotation or interaction. We show that our method improves the performance of semantic segmentation in multiple cities across continents, while it performs favorably against state-of-the-art approaches requiring annotated training data.