 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Model Fusion for Privacy-Aware Multi-Camera Surveillance via Synthetic Domain Adaptation
May 04, 2026We propose HeroCrystal, a novel privacy-preserving framework for multi-camera domain-adaptive object detection, addressing challenges such as data privacy, class imbalance, and heterogeneous architectures. Our framework consists of three key stages. In the Generated Stage, we introduce a one-shot, target-aware diffusion-based generation module that learns visual style from a single target-domain image while leveraging prompt-based control to synthesize specific object instances. Unlike conventional style transfer-based methods that require large target datasets and ignore semantic-level discrepancies, our approach enables privacy-preserving augmentation to reduce ethical concerns, and introduces controllable rare object generation to mitigate long-tailed category degradation. In the Federated Stage, we employ probabilistic Faster R-CNN on the client side to improve localization accuracy, and a dynamic model contrastive strategy to suppress domain-specific bias. The server side performs model fusion across heterogeneous architectures without accessing raw data. Finally, in the Distilled Stage, we propose an inconsistent categories integration algorithm to resolve label inconsistency and architecture heterogeneity across clients. Extensive experiments on multiple cross-domain detection benchmarks demonstrate that our method outperforms existing multi-source domain adaptation and federated learning baselines under multi-class, privacy-preserving settings. Our method improves mAP by +2.1% over prior privacy-preserving approaches and achieves a new state-of-the-art mAP of 33.4%, highlighting the effectiveness of HeroCrystal in enabling practical multi-camera AI surveillance systems.
* 42 pages, 13 figures. Published in Information Fusion (Elsevier). DOI: 10.1016/j.inffus.2026.104413
CodaRAG: Connecting the Dots with Associativity Inspired by Complementary Learning
Apr 12, 2026Large Language Models (LLMs) struggle with knowledge-intensive tasks due to hallucinations and fragmented reasoning over dispersed information. While Retrieval-Augmented Generation (RAG) grounds generation in external sources, existing methods often treat evidence as isolated units, failing to reconstruct the logical chains that connect these dots. Inspired by Complementary Learning Systems (CLS), we propose CodaRAG, a framework that evolves retrieval from passive lookup into active associative discovery. CodaRAG operates via a three-stage pipeline: (1) Knowledge Consolidation to unify fragmented extractions into a stable memory substrate; (2) Associative Navigation to traverse the graph via multi-dimensional pathways-semantic, contextualized, and functional-explicitly recovering dispersed evidence chains; and (3) Interference Elimination to prune hyper-associative noise, ensuring a coherent, high-precision reasoning context. On GraphRAG-Bench, CodaRAG achieves absolute gains of 7-10% in retrieval recall and 3-11% in generation accuracy. These results demonstrate CodaRAG's superior ability to systematically robustify associative evidence retrieval for factual, reasoning, and creative tasks.
Regret-Guided Search Control for Efficient Learning in AlphaZero
Feb 24, 2026Reinforcement learning (RL) agents achieve remarkable performance but remain far less learning-efficient than humans. While RL agents require extensive self-play games to extract useful signals, humans often need only a few games, improving rapidly by repeatedly revisiting states where mistakes occurred. This idea, known as search control, aims to restart from valuable states rather than always from the initial state. In AlphaZero, prior work Go-Exploit applies this idea by sampling past states from self-play or search trees, but it treats all states equally, regardless of their learning potential. We propose Regret-Guided Search Control (RGSC), which extends AlphaZero with a regret network that learns to identify high-regret states, where the agent's evaluation diverges most from the actual outcome. These states are collected from both self-play trajectories and MCTS nodes, stored in a prioritized regret buffer, and reused as new starting positions. Across 9x9 Go, 10x10 Othello, and 11x11 Hex, RGSC outperforms AlphaZero and Go-Exploit by an average of 77 and 89 Elo, respectively. When training on a well-trained 9x9 Go model, RGSC further improves the win rate against KataGo from 69.3% to 78.2%, while both baselines show no improvement. These results demonstrate that RGSC provides an effective mechanism for search control, improving both efficiency and robustness of AlphaZero training. Our code is available at https://rlg.iis.sinica.edu.tw/papers/rgsc.
Interpreting the Learned Model in MuZero Planning
Nov 07, 2024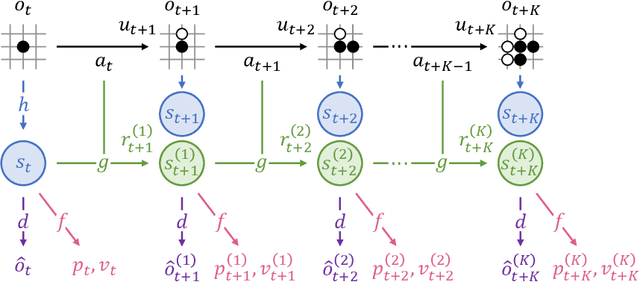
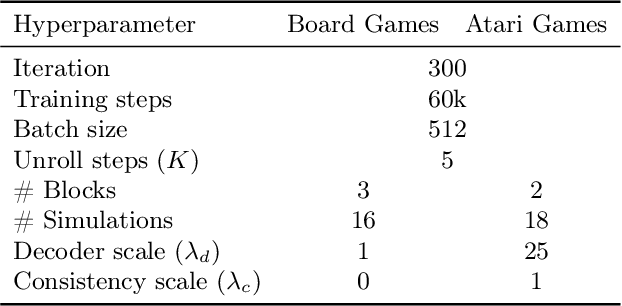
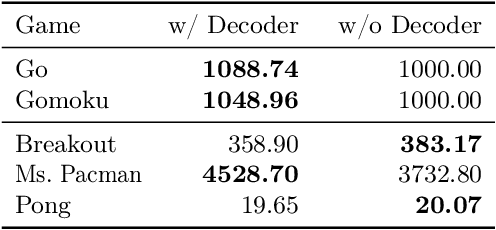
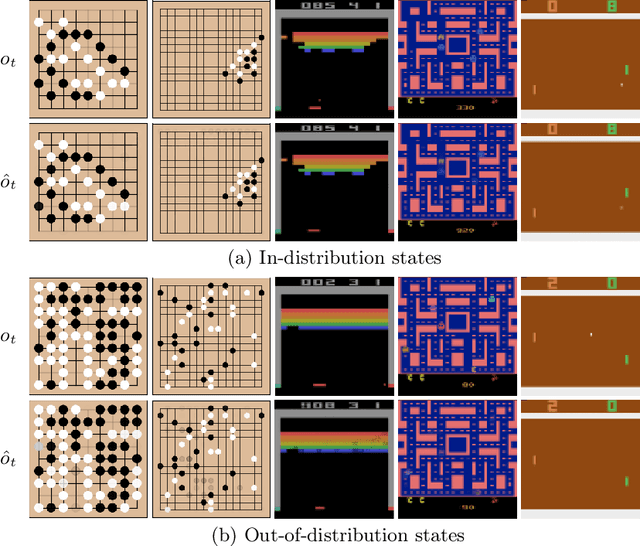
MuZero has achieved superhuman performance in various games by using a dynamics network to predict environment dynamics for planning, without relying on simulators. However, the latent states learned by the dynamics network make its planning process opaque. This paper aims to demystify MuZero's model by interpreting the learned latent states. We incorporate observation reconstruction and state consistency into MuZero training and conduct an in-depth analysis to evaluate latent states across two board games: 9x9 Go and Outer-Open Gomoku, and three Atari games: Breakout, Ms. Pacman, and Pong. Our findings reveal that while the dynamics network becomes less accurate over longer simulations, MuZero still performs effectively by using planning to correct errors. Our experiments also show that the dynamics network learns better latent states in board games than in Atari games. These insights contribute to a better understanding of MuZero and offer directions for future research to improve the playing performance, robustness, and interpretability of the MuZero algorithm.
Intelligent Tutor: Leveraging ChatGPT and Microsoft Copilot Studio to Deliver a Generative AI Student Support and Feedback System within Teams
May 15, 2024This study explores the integration of the ChatGPT API with GPT-4 model and Microsoft Copilot Studio on the Microsoft Teams platform to develop an intelligent tutoring system. Designed to provide instant support to students, the system dynamically adjusts educational content in response to the learners' progress and feedback. Utilizing advancements in natural language processing and machine learning, it interprets student inquiries, offers tailored feedback, and facilitates the educational journey. Initial implementation highlights the system's potential in boosting students' motivation and engagement, while equipping educators with critical insights into the learning process, thus promoting tailored educational experiences and enhancing instructional effectiveness.
Pointersect: Neural Rendering with Cloud-Ray Intersection
Apr 24, 2023

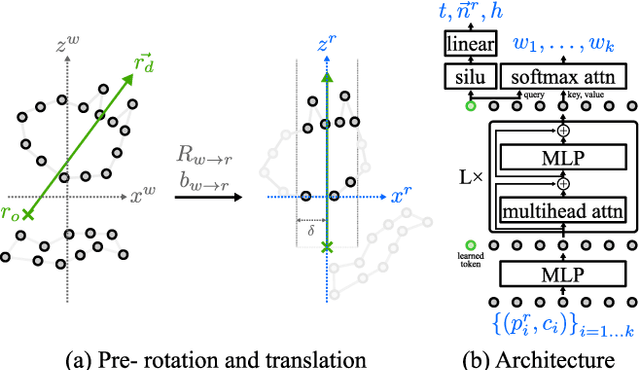

We propose a novel method that renders point clouds as if they are surfaces. The proposed method is differentiable and requires no scene-specific optimization. This unique capability enables, out-of-the-box, surface normal estimation, rendering room-scale point clouds, inverse rendering, and ray tracing with global illumination. Unlike existing work that focuses on converting point clouds to other representations--e.g., surfaces or implicit functions--our key idea is to directly infer the intersection of a light ray with the underlying surface represented by the given point cloud. Specifically, we train a set transformer that, given a small number of local neighbor points along a light ray, provides the intersection point, the surface normal, and the material blending weights, which are used to render the outcome of this light ray. Localizing the problem into small neighborhoods enables us to train a model with only 48 meshes and apply it to unseen point clouds. Our model achieves higher estimation accuracy than state-of-the-art surface reconstruction and point-cloud rendering methods on three test sets. When applied to room-scale point clouds, without any scene-specific optimization, the model achieves competitive quality with the state-of-the-art novel-view rendering methods. Moreover, we demonstrate ability to render and manipulate Lidar-scanned point clouds such as lighting control and object insertion.
Fisheye traffic data set of point center markers
Jan 31, 2023This study presents an open data-market platform and a dataset containing 160,000 markers and 18,000 images. We hope that this dataset will bring more new data value and applications In this paper, we introduce the format and usage of the dataset, and we show a demonstration of deep learning vehicle detection trained by this dataset.
Enhancing Speckle Statistics for Imaging inside Scattering Media
Mar 27, 2022

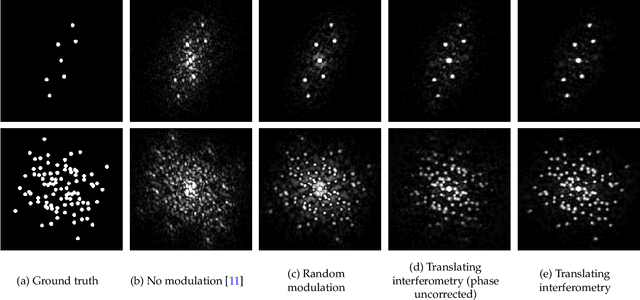
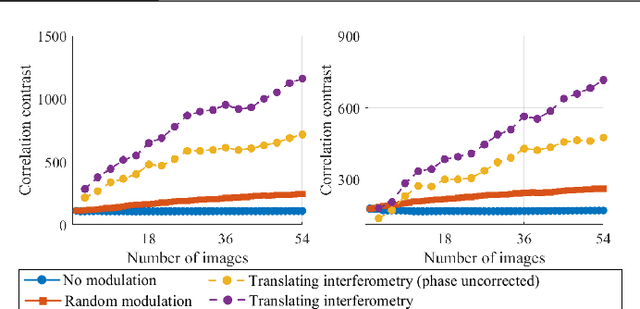
We exploit memory effect speckle correlations for the imaging of incoherent linear (single-photon) fluorescent sources behind scattering tissue. While memory effect-based imaging techniques have been heavily studied in the past, for thick scattering layers and complex illumination patterns these correlations are weak, limiting the practice applicability of the idea. In this work, we introduce a Spatial Light Modulator (SLM) between the tissue sample and the imaging sensor and capture multiple modulations of the speckle pattern. We show that by correctly designing the modulation pattern and the reconstruction algorithm we can greatly enhance statistical correlations in the data. We exploit this to demonstrate the reconstruction of mega-pixel wide fluorescent patterns behind scattering tissue.
A Closer Look at Few-shot Classification
Apr 08, 2019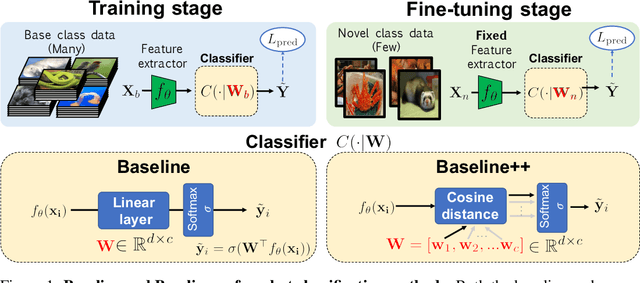
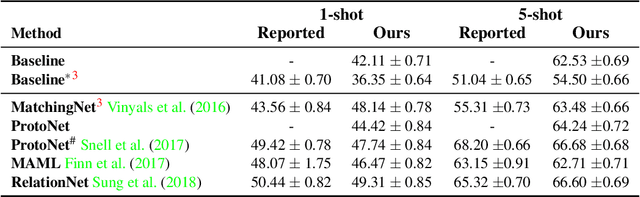
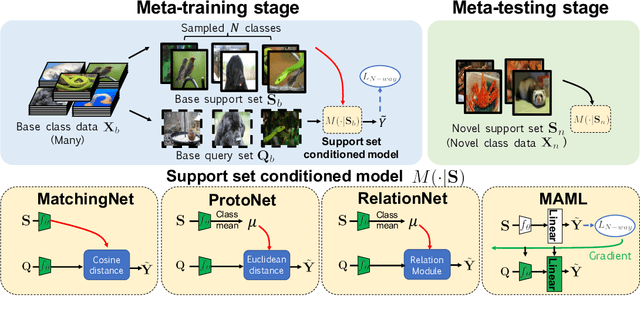
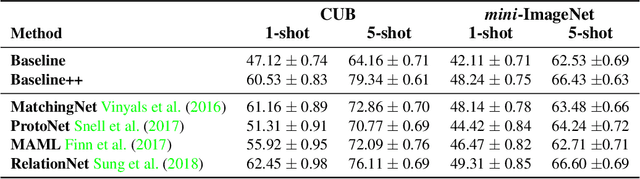
Few-shot classification aims to learn a classifier to recognize unseen classes during training with limited labeled examples. While significant progress has been made, the growing complexity of network designs, meta-learning algorithms, and differences in implementation details make a fair comparison difficult. In this paper, we present 1) a consistent comparative analysis of several representative few-shot classification algorithms, with results showing that deeper backbones significantly reduce the performance differences among methods on datasets with limited domain differences, 2) a modified baseline method that surprisingly achieves competitive performance when compared with the state-of-the-art on both the \miniI and the CUB datasets, and 3) a new experimental setting for evaluating the cross-domain generalization ability for few-shot classification algorithms. Our results reveal that reducing intra-class variation is an important factor when the feature backbone is shallow, but not as critical when using deeper backbones. In a realistic cross-domain evaluation setting, we show that a baseline method with a standard fine-tuning practice compares favorably against other state-of-the-art few-shot learning algorithms.
No More Discrimination: Cross City Adaptation of Road Scene Segmenters
Apr 27, 2017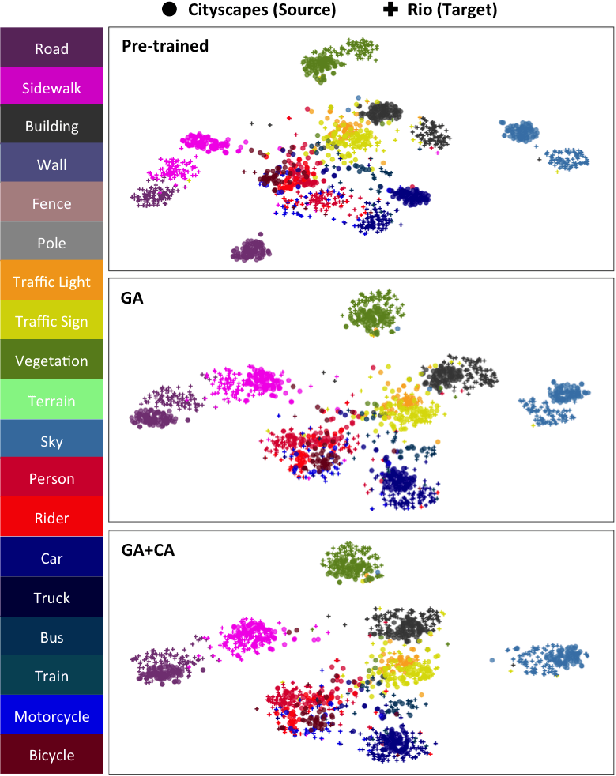
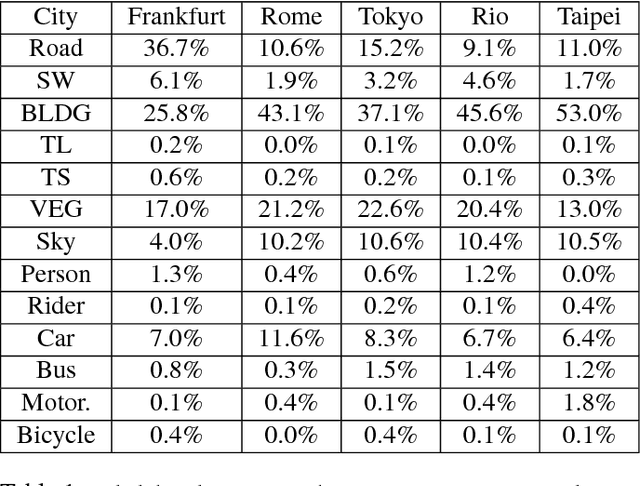

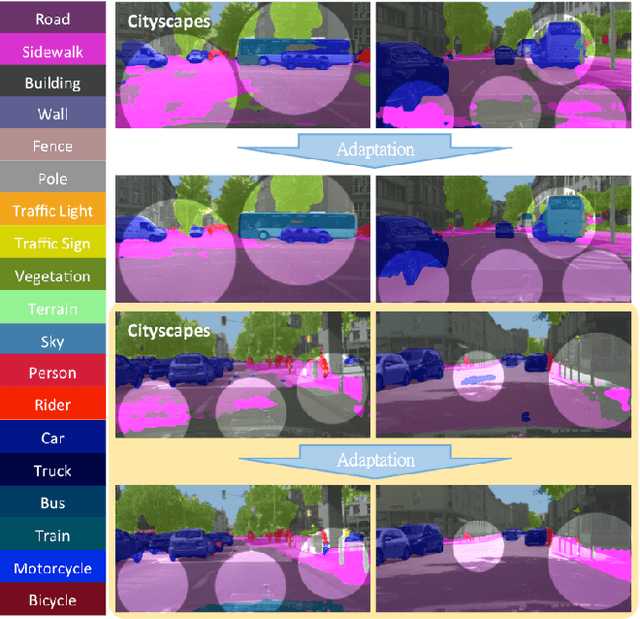
Despite the recent success of deep-learning based semantic segmentation, deploying a pre-trained road scene segmenter to a city whose images are not presented in the training set would not achieve satisfactory performance due to dataset biases. Instead of collecting a large number of annotated images of each city of interest to train or refine the segmenter, we propose an unsupervised learning approach to adapt road scene segmenters across different cities. By utilizing Google Street View and its time-machine feature, we can collect unannotated images for each road scene at different times, so that the associated static-object priors can be extracted accordingly. By advancing a joint global and class-specific domain adversarial learning framework, adaptation of pre-trained segmenters to that city can be achieved without the need of any user annotation or interaction. We show that our method improves the performance of semantic segmentation in multiple cities across continents, while it performs favorably against state-of-the-art approaches requiring annotated training data.