 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias-Aware Heapified Policy for Active Learning
Nov 18, 2019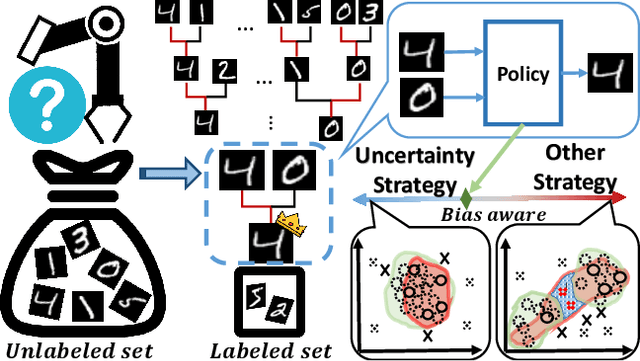
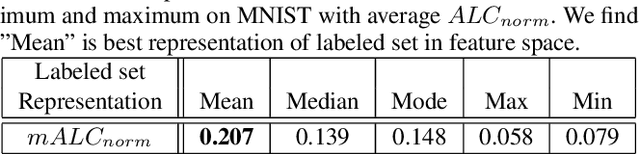
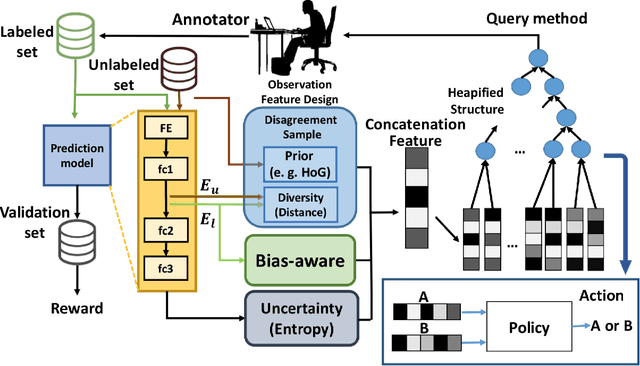
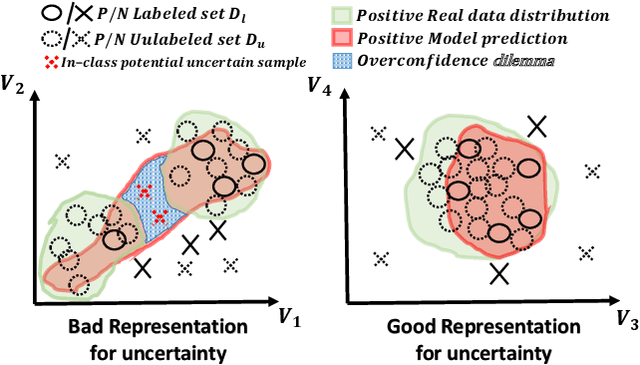
The data efficiency of learning-based algorithms is more and more important since high-quality and clean data is expensive as well as hard to collect. In order to achieve high model performance with the least number of samples, active learning is a technique that queries the most important subset of data from the original dataset. In active learning domain, one of the mainstream research is the heuristic uncertainty-based method which is useful for the learning-based system. Recently, a few works propose to apply policy reinforcement learning (PRL) for querying important data. It seems more general than heuristic uncertainty-based method owing that PRL method depends on data feature which is reliable than human prior. However, there have two problems - sample inefficiency of policy learning and overconfidence, when applying PRL on active learning. To be more precise, sample inefficiency of policy learning occurs when sampling within a large action space, in the meanwhile, class imbalance can lead to the overconfidence. In this paper, we propose a bias-aware policy network called Heapified Active Learning (HAL), which prevents overconfidence, and improves sample efficiency of policy learning by heapified structure without ignoring global inforamtion(overview of the whole unlabeled set). In our experiment, HAL outperforms other baseline methods on MNIST dataset and duplicated MNIST. Last but not least, we investigate the generalization of the HAL policy learned on MNIST dataset by directly applying it on MNIST-M. We show that the agent can generalize and outperform directly-learned policy under constrained labeled sets.
360-Indoor: Towards Learning Real-World Objects in 360° Indoor Equirectangular Images
Oct 03, 2019


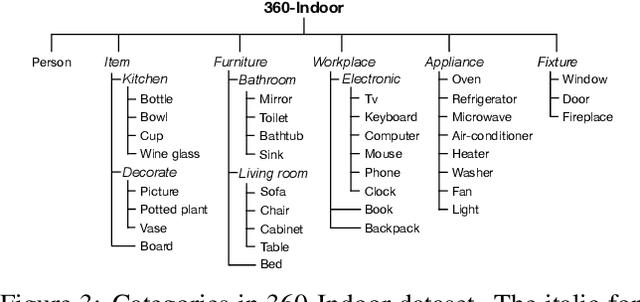
While there are several widely used object detection datasets, current computer vision algorithms are still limited in conventional images. Such images narrow our vision in a restricted region. On the other hand, 360{\deg} images provide a thorough sight. In this paper, our goal is to provide a standard dataset to facilitate the vision and machine learning communities in 360{\deg} domain. To facilitate the research, we present a real-world 360{\deg} panoramic object detection dataset, 360-Indoor, which is a new benchmark for visual object detection and class recognition in 360{\deg} indoor images. It is achieved by gathering images of complex indoor scenes containing common objects and the intensive annotated bounding field-of-view. In addition, 360-Indoor has several distinct properties: (1) the largest category number (37 labels in total). (2) the most complete annotations on average (27 bounding boxes per image). The selected 37 objects are all common in indoor scene. With around 3k images and 90k labels in total, 360-Indoor achieves the largest dataset for detection in 360{\deg} images. In the end, extensive experiments on the state-of-the-art methods for both classification and detection are provided. We will release this dataset in the near future.
Leveraging Motion Priors in Videos for Improving Human Segmentation
Jul 30, 2018


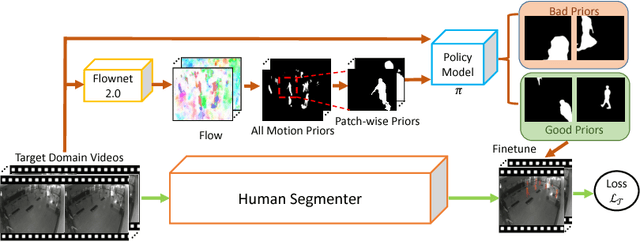
Despite many advances in deep-learning based semantic segmentation, performance drop due to distribution mismatch is often encountered in the real world. Recently, a few domain adaptation and active learning approaches have been proposed to mitigate the performance drop. However, very little attention has been made toward leveraging information in videos which are naturally captured in most camera systems. In this work, we propose to leverage "motion prior" in videos for improving human segmentation in a weakly-supervised active learning setting. By extracting motion information using optical flow in videos, we can extract candidate foreground motion segments (referred to as motion prior) potentially corresponding to human segments. We propose to learn a memory-network-based policy model to select strong candidate segments (referred to as strong motion prior) through reinforcement learning. The selected segments have high precision and are directly used to finetune the model. In a newly collected surveillance camera dataset and a publicly available UrbanStreet dataset, our proposed method improves the performance of human segmentation across multiple scenes and modalities (i.e., RGB to Infrared (IR)). Last but not least, our method is empirically complementary to existing domain adaptation approaches such that additional performance gain is achieved by combining our weakly-supervised active learning approach with domain adaptation approaches.