 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Is Not Static: Order-Aware Hypergraph RAG for Language Models
Apr 14, 2026Retrieval-augmented generation (RAG) enhances large language models by grounding outputs in retrieved knowledge. However, existing RAG methods including graph- and hypergraph-based approaches treat retrieved evidence as an unordered set, implicitly assuming permutation invariance. This assumption is misaligned with many real-world reasoning tasks, where outcomes depend not only on which interactions occur, but also on the order in which they unfold. We propose Order-Aware Knowledge Hypergraph RAG (OKH-RAG), which treats order as a first-class structural property. OKH-RAG represents knowledge as higher-order interactions within a hypergraph augmented with precedence structure, and reformulates retrieval as sequence inference over hyperedges. Instead of selecting independent facts, it recovers coherent interaction trajectories that reflect underlying reasoning processes. A learned transition model infers precedence directly from data without requiring explicit temporal supervision. We evaluate OKH-RAG on order-sensitive question answering and explanation tasks, including tropical cyclone and port operation scenarios. OKH-RAG consistently outperforms permutation-invariant baselines, and ablations show that these gains arise specifically from modeling interaction order. These results highlight a key limitation of set-based retrieval: effective reasoning requires not only retrieving relevant evidence, but organizing it into structured sequences.
Region-R1: Reinforcing Query-Side Region Cropping for Multi-Modal Re-Ranking
Apr 07, 2026Multi-modal retrieval-augmented generation (MM-RAG) relies heavily on re-rankers to surface the most relevant evidence for image-question queries. However, standard re-rankers typically process the full query image as a global embedding, making them susceptible to visual distractors (e.g., background clutter) that skew similarity scores. We propose Region-R1, a query-side region cropping framework that formulates region selection as a decision-making problem during re-ranking, allowing the system to learn to retain the full image or focus only on a question-relevant region before scoring the retrieved candidates. Region-R1 learns a policy with a novel region-aware group relative policy optimization (r-GRPO) to dynamically crop a discriminative region. Across two challenging benchmarks, E-VQA and InfoSeek, Region-R1 delivers consistent gains, achieving state-of-the-art performances by increasing conditional Recall@1 by up to 20%. These results show the great promise of query-side adaptation as a simple but effective way to strengthen MM-RAG re-ranking.
mRAG: Elucidating the Design Space of Multi-modal Retrieval-Augmented Generation
May 29, 2025Large Vision-Language Models (LVLMs) have made remarkable strides in multimodal tasks such as visual question answering, visual grounding, and complex reasoning. However, they remain limited by static training data, susceptibility to hallucinations, and inability to verify claims against up-to-date, external evidence, compromising their performance in dynamic real-world applications. Retrieval-Augmented Generation (RAG) offers a practical solution to mitigate these challenges by allowing the LVLMs to access large-scale knowledge databases via retrieval mechanisms, thereby grounding model outputs in factual, contextually relevant information. Here in this paper, we conduct the first systematic dissection of the multimodal RAG pipeline for LVLMs, explicitly investigating (1) the retrieval phase: on the modality configurations and retrieval strategies, (2) the re-ranking stage: on strategies to mitigate positional biases and improve the relevance of retrieved evidence, and (3) the generation phase: we further investigate how to best integrate retrieved candidates into the final generation process. Finally, we extend to explore a unified agentic framework that integrates re-ranking and generation through self-reflection, enabling LVLMs to select relevant evidence and suppress irrelevant context dynamically. Our full-stack exploration of RAG for LVLMs yields substantial insights, resulting in an average performance boost of 5% without any fine-tuning.
Liquid Pouring Monitoring via Rich Sensory Inputs
Aug 06, 2018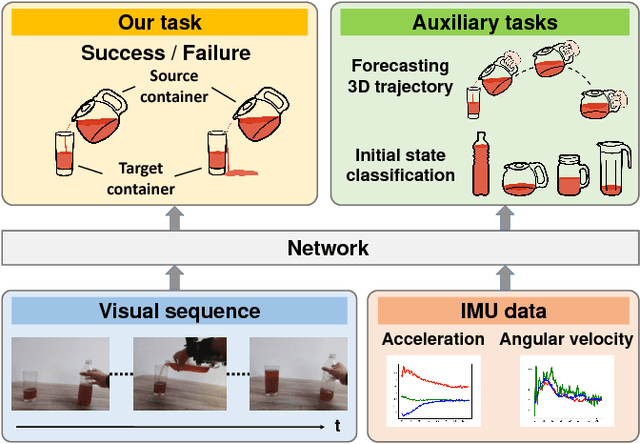
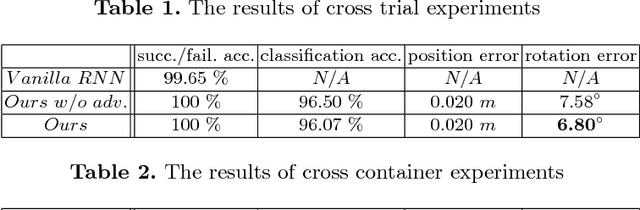
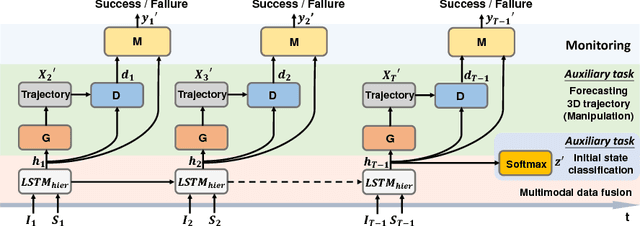
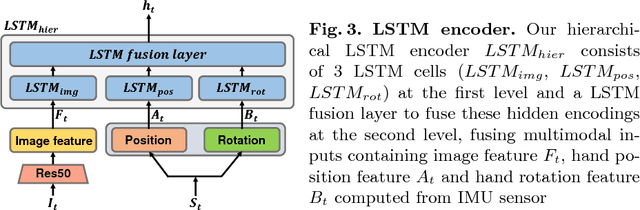
Humans have the amazing ability to perform very subtle manipulation task using a closed-loop control system with imprecise mechanics (i.e., our body parts) but rich sensory information (e.g., vision, tactile, etc.). In the closed-loop system, the ability to monitor the state of the task via rich sensory information is important but often less studied. In this work, we take liquid pouring as a concrete example and aim at learning to continuously monitor whether liquid pouring is successful (e.g., no spilling) or not via rich sensory inputs. We mimic humans' rich sensories using synchronized observation from a chest-mounted camera and a wrist-mounted IMU sensor. Given many success and failure demonstrations of liquid pouring, we train a hierarchical LSTM with late fusion for monitoring. To improve the robustness of the system, we propose two auxiliary tasks during training: inferring (1) the initial state of containers and (2) forecasting the one-step future 3D trajectory of the hand with an adversarial training procedure. These tasks encourage our method to learn representation sensitive to container states and how objects are manipulated in 3D. With these novel components, our method achieves ~8% and ~11% better monitoring accuracy than the baseline method without auxiliary tasks on unseen containers and unseen users respectively.
Omnidirectional CNN for Visual Place Recognition and Navigation
Mar 12, 2018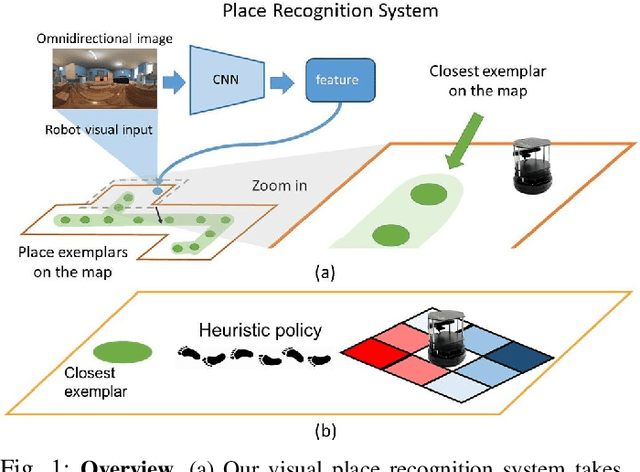
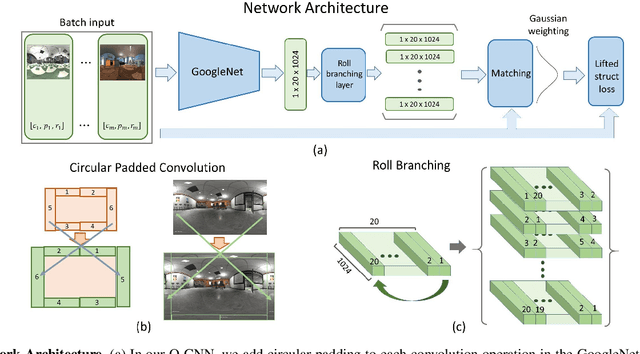
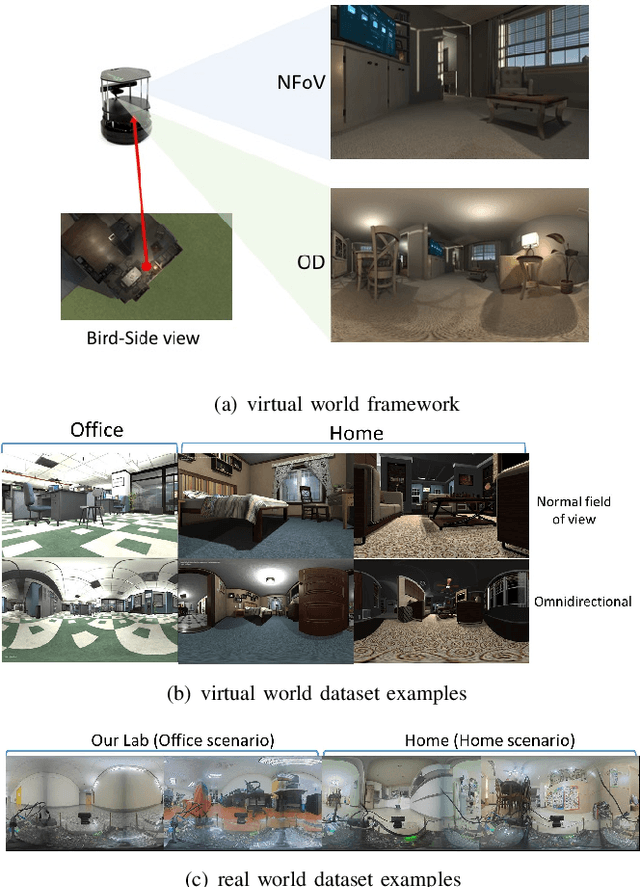
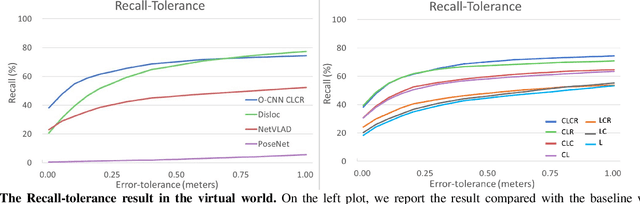
$ $Visual place recognition is challenging, especially when only a few place exemplars are given. To mitigate the challenge, we consider place recognition method using omnidirectional cameras and propose a novel Omnidirectional Convolutional Neural Network (O-CNN) to handle severe camera pose variation. Given a visual input, the task of the O-CNN is not to retrieve the matched place exemplar, but to retrieve the closest place exemplar and estimate the relative distance between the input and the closest place. With the ability to estimate relative distance, a heuristic policy is proposed to navigate a robot to the retrieved closest place. Note that the network is designed to take advantage of the omnidirectional view by incorporating circular padding and rotation invariance. To train a powerful O-CNN, we build a virtual world for training on a large scale. We also propose a continuous lifted structured feature embedding loss to learn the concept of distance efficiently. Finally, our experimental results confirm that our method achieves state-of-the-art accuracy and speed with both the virtual world and real-world datasets.
Anticipating Daily Intention using On-Wrist Motion Triggered Sensing
Oct 20, 2017
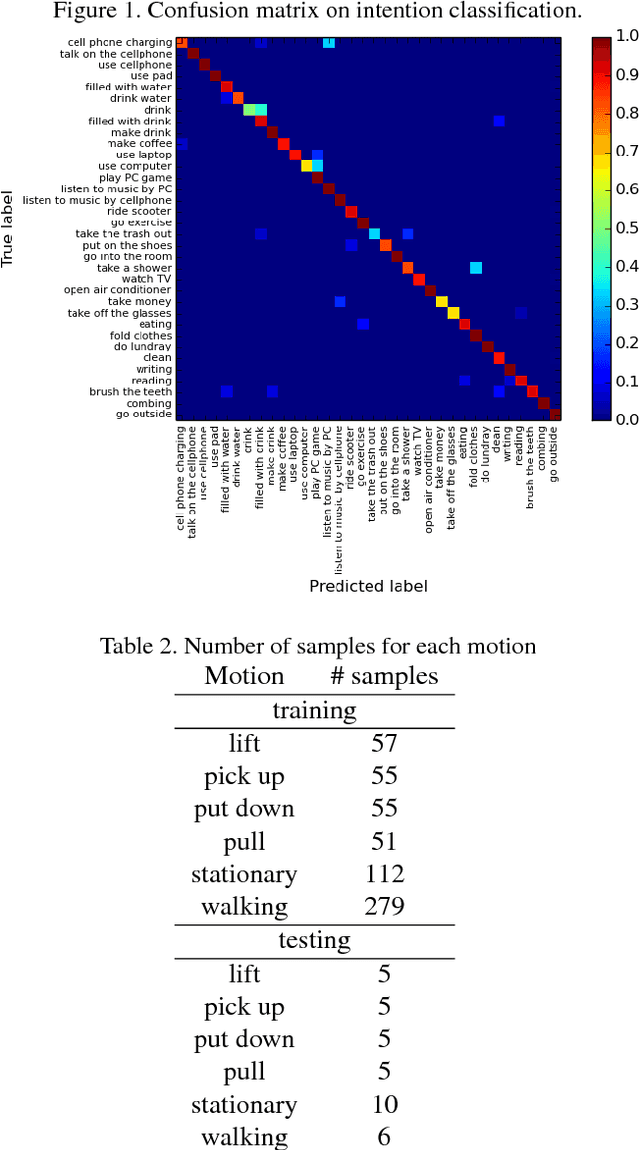
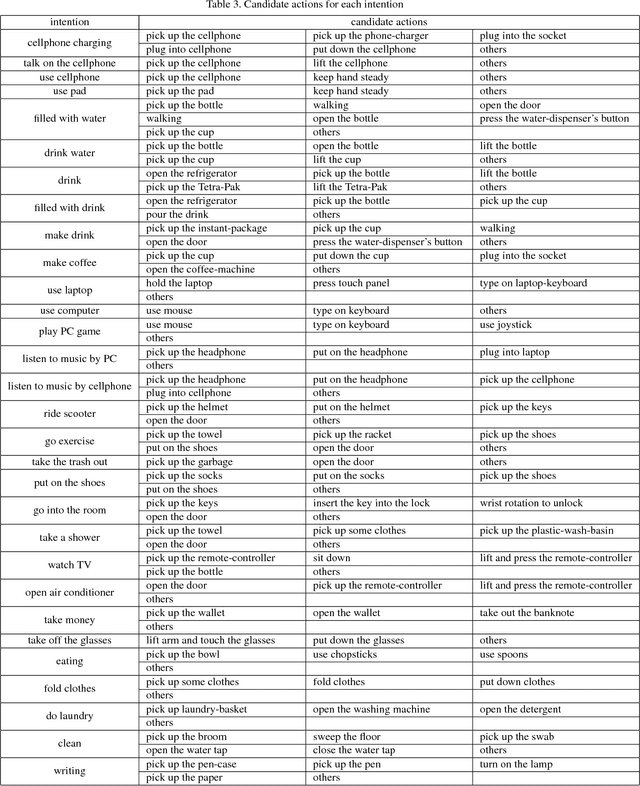
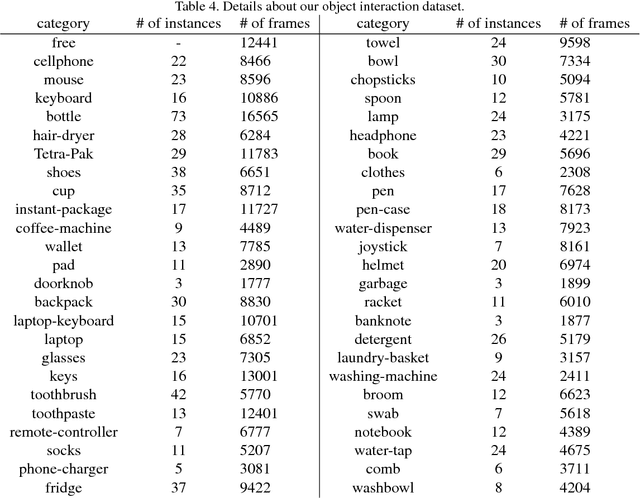
Anticipating human intention by observing one's actions has many applications. For instance, picking up a cellphone, then a charger (actions) implies that one wants to charge the cellphone (intention). By anticipating the intention, an intelligent system can guide the user to the closest power outlet. We propose an on-wrist motion triggered sensing system for anticipating daily intentions, where the on-wrist sensors help us to persistently observe one's actions. The core of the system is a novel Recurrent Neural Network (RNN) and Policy Network (PN), where the RNN encodes visual and motion observation to anticipate intention, and the PN parsimoniously triggers the process of visual observation to reduce computation requirement. We jointly trained the whole network using policy gradient and cross-entropy loss. To evaluate, we collect the first daily "intention" dataset consisting of 2379 videos with 34 intentions and 164 unique action sequences. Our method achieves 92.68%, 90.85%, 97.56% accuracy on three users while processing only 29% of the visual observation on average.