 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipating Daily Intention using On-Wrist Motion Triggered Sensing
Oct 20, 2017
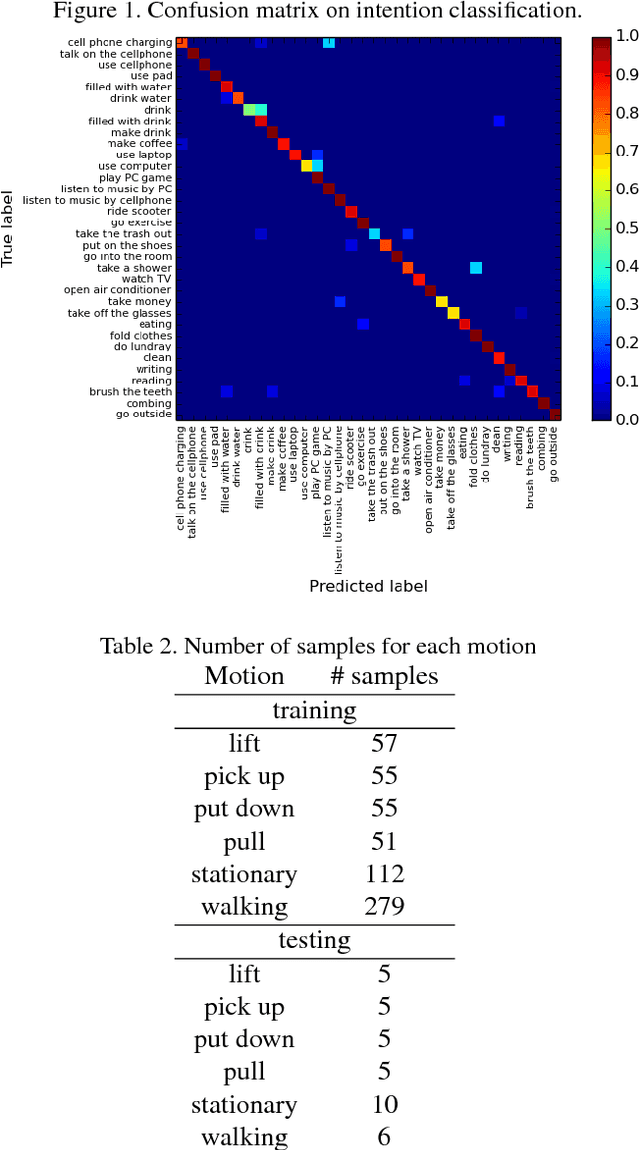
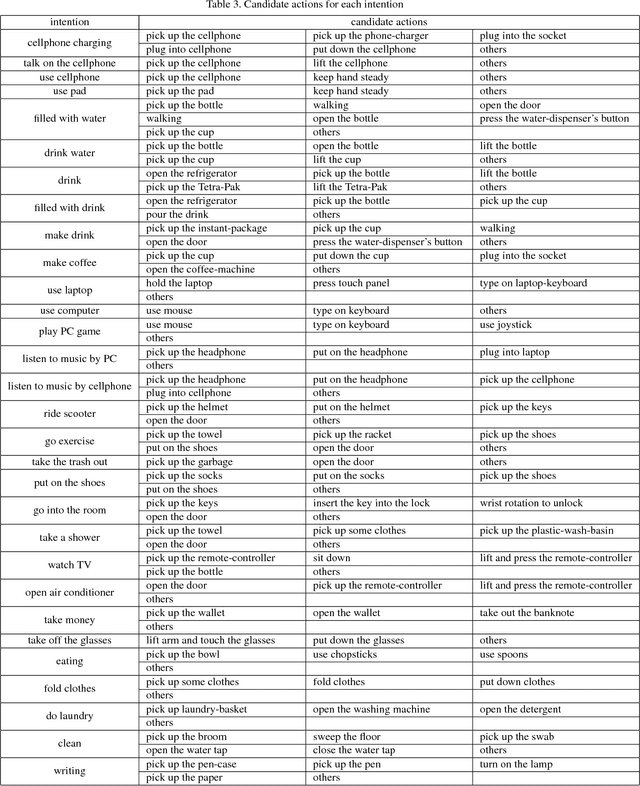
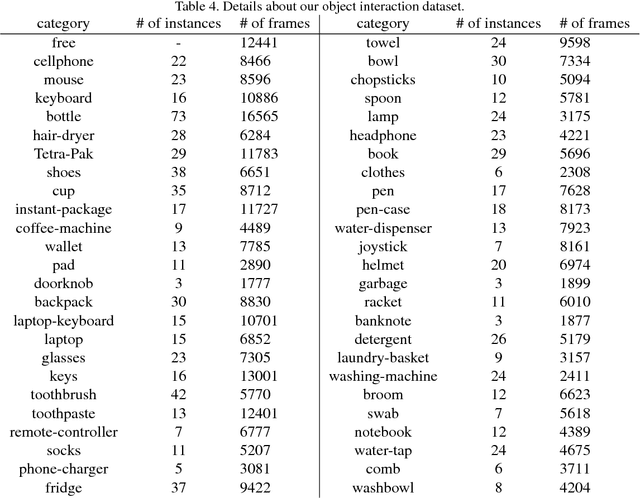
Anticipating human intention by observing one's actions has many applications. For instance, picking up a cellphone, then a charger (actions) implies that one wants to charge the cellphone (intention). By anticipating the intention, an intelligent system can guide the user to the closest power outlet. We propose an on-wrist motion triggered sensing system for anticipating daily intentions, where the on-wrist sensors help us to persistently observe one's actions. The core of the system is a novel Recurrent Neural Network (RNN) and Policy Network (PN), where the RNN encodes visual and motion observation to anticipate intention, and the PN parsimoniously triggers the process of visual observation to reduce computation requirement. We jointly trained the whole network using policy gradient and cross-entropy loss. To evaluate, we collect the first daily "intention" dataset consisting of 2379 videos with 34 intentions and 164 unique action sequences. Our method achieves 92.68%, 90.85%, 97.56% accuracy on three users while processing only 29% of the visual observation on average.
Recognition from Hand Cameras
Mar 22, 2016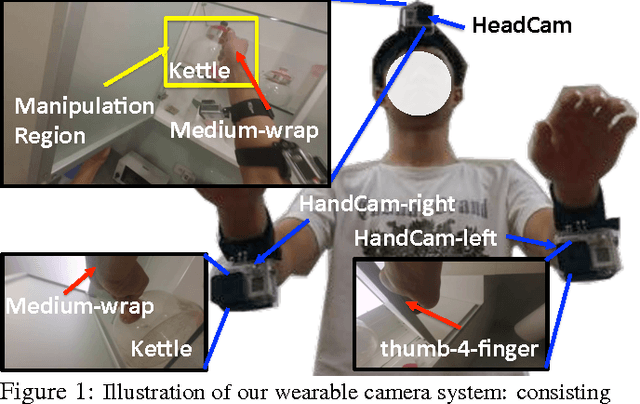



We revisit the study of a wrist-mounted camera system (referred to as HandCam) for recognizing activities of hands. HandCam has two unique properties as compared to egocentric systems (referred to as HeadCam): (1) it avoids the need to detect hands; (2) it more consistently observes the activities of hands. By taking advantage of these properties, we propose a deep-learning-based method to recognize hand states (free v.s. active hands, hand gestures, object categories), and discover object categories. Moreover, we propose a novel two-streams deep network to further take advantage of both HandCam and HeadCam. We have collected a new synchronized HandCam and HeadCam dataset with 20 videos captured in three scenes for hand states recognition. Experiments show that our HandCam system consistently outperforms a deep-learning-based HeadCam method (with estimated manipulation regions) and a dense-trajectory-based HeadCam method in all tasks. We also show that HandCam videos captured by different users can be easily aligned to improve free v.s. active recognition accuracy (3.3% improvement) in across-scenes use case. Moreover, we observe that finetuning Convolutional Neural Network consistently improves accuracy. Finally, our novel two-streams deep network combining HandCam and HeadCam features achieves the best performance in four out of five tasks. With more data, we believe a joint HandCam and HeadCam system can robustly log hand states in daily life.