 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Semantic Segmentation with Pixel-Level Contrastive Learning from a Class-wise Memory Bank
Paper and Code
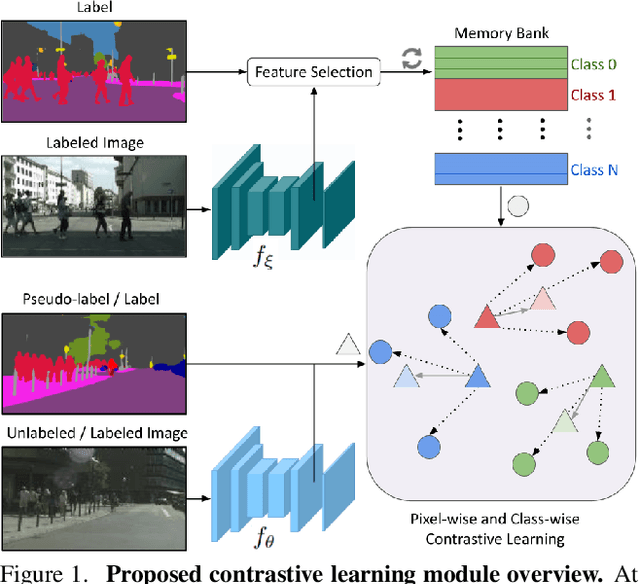
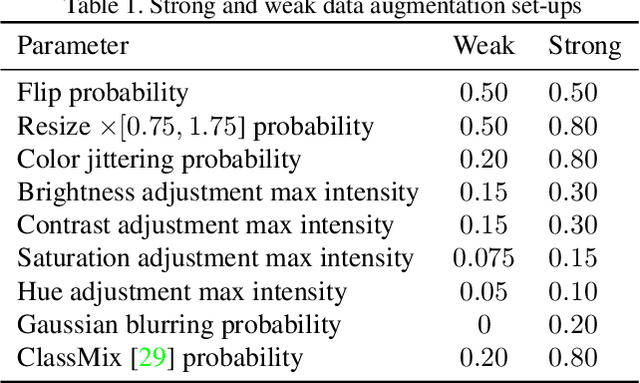
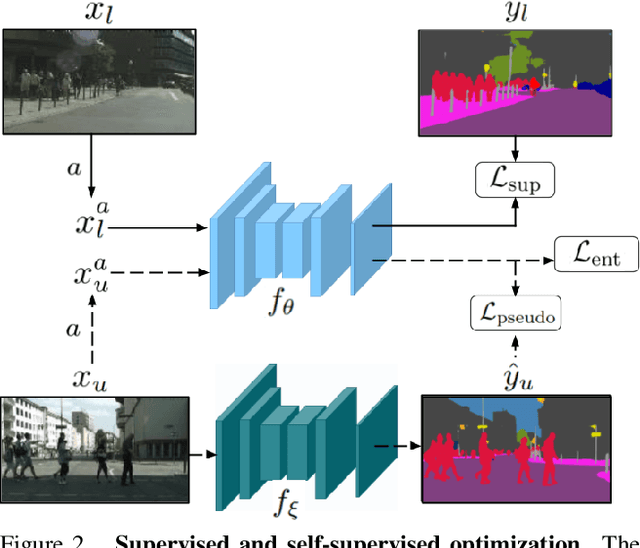
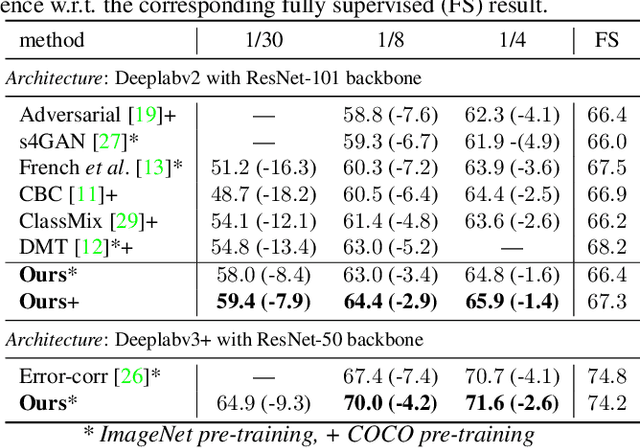
This work presents a novel approach for semi-supervised semantic segmentation, i.e., per-pixel classification problem assuming that only a small set of the available data is labeled. We propose a novel representation learning module based on contrastive learning. This module enforces the segmentation network to yield similar pixel-level feature representations for same-class samples across the whole dataset. To achieve this, we maintain a memory bank continuously updated with feature vectors from labeled data. These features are selected based on their quality and relevance for the contrastive learning. In an end-to-end training, the features from both labeled and unlabeled data are optimized to be similar to same-class samples from the memory bank. Our approach outperforms the current state-of-the-art for semi-supervised semantic segmentation and semi-supervised domain adaptation on well-known public benchmarks, with larger improvements on the most challenging scenarios, i.e., less available labeled data.