 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperPoint-E: local features for 3D reconstruction via tracking adaptation in endoscopy
Feb 04, 2026In this work, we focus on boosting the feature extraction to improve the performance of Structure-from-Motion (SfM) in endoscopy videos. We present SuperPoint-E, a new local feature extraction method that, using our proposed Tracking Adaptation supervision strategy, significantly improves the quality of feature detection and description in endoscopy. Extensive experimentation on real endoscopy recordings studies our approach's most suitable configuration and evaluates SuperPoint-E feature quality. The comparison with other baselines also shows that our 3D reconstructions are denser and cover more and longer video segments because our detector fires more densely and our features are more likely to survive (i.e. higher detection precision). In addition, our descriptor is more discriminative, making the guided matching step almost redundant. The presented approach brings significant improvements in the 3D reconstructions obtained, via SfM on endoscopy videos, compared to the original SuperPoint and the gold standard SfM COLMAP pipeline.
Sim2Real in endoscopy segmentation with a novel structure aware image translation
May 05, 2025Automatic segmentation of anatomical landmarks in endoscopic images can provide assistance to doctors and surgeons for diagnosis, treatments or medical training. However, obtaining the annotations required to train commonly used supervised learning methods is a tedious and difficult task, in particular for real images. While ground truth annotations are easier to obtain for synthetic data, models trained on such data often do not generalize well to real data. Generative approaches can add realistic texture to it, but face difficulties to maintain the structure of the original scene. The main contribution in this work is a novel image translation model that adds realistic texture to simulated endoscopic images while keeping the key scene layout information. Our approach produces realistic images in different endoscopy scenarios. We demonstrate these images can effectively be used to successfully train a model for a challenging end task without any real labeled data. In particular, we demonstrate our approach for the task of fold segmentation in colonoscopy images. Folds are key anatomical landmarks that can occlude parts of the colon mucosa and possible polyps. Our approach generates realistic images maintaining the shape and location of the original folds, after the image-style-translation, better than existing methods. We run experiments both on a novel simulated dataset for fold segmentation, and real data from the EndoMapper (EM) dataset. All our new generated data and new EM metadata is being released to facilitate further research, as no public benchmark is currently available for the task of fold segmentation.
FALCONEye: Finding Answers and Localizing Content in ONE-hour-long videos with multi-modal LLMs
Mar 25, 2025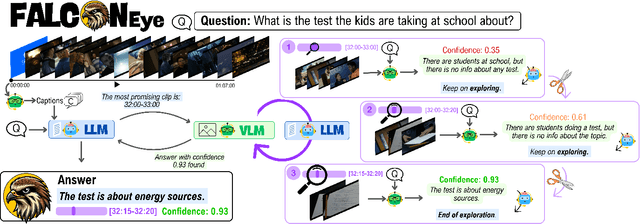
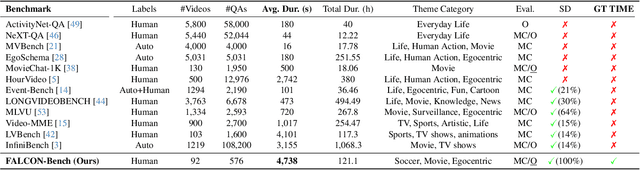
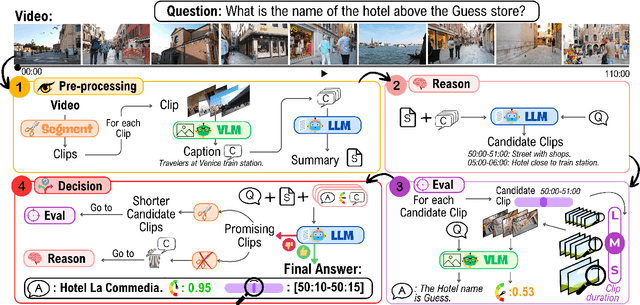
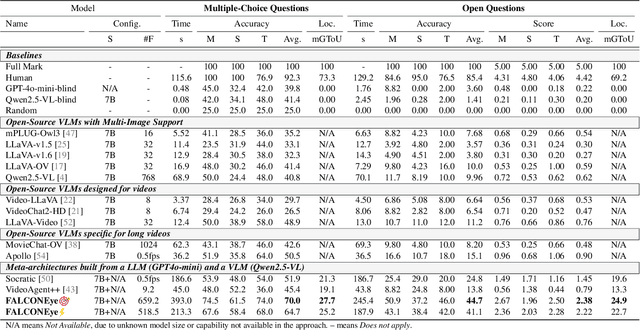
Information retrieval in hour-long videos presents a significant challenge, even for state-of-the-art Vision-Language Models (VLMs), particularly when the desired information is localized within a small subset of frames. Long video data presents challenges for VLMs due to context window limitations and the difficulty of pinpointing frames containing the answer. Our novel video agent, FALCONEye, combines a VLM and a Large Language Model (LLM) to search relevant information along the video, and locate the frames with the answer. FALCONEye novelty relies on 1) the proposed meta-architecture, which is better suited to tackle hour-long videos compared to short video approaches in the state-of-the-art; 2) a new efficient exploration algorithm to locate the information using short clips, captions and answer confidence; and 3) our state-of-the-art VLMs calibration analysis for the answer confidence. Our agent is built over a small-size VLM and a medium-size LLM being accessible to run on standard computational resources. We also release FALCON-Bench, a benchmark to evaluate long (average > 1 hour) Video Answer Search challenges, highlighting the need for open-ended question evaluation. Our experiments show FALCONEye's superior performance than the state-of-the-art in FALCON-Bench, and similar or better performance in related benchmarks.
Gen-Swarms: Adapting Deep Generative Models to Swarms of Drones
Aug 28, 2024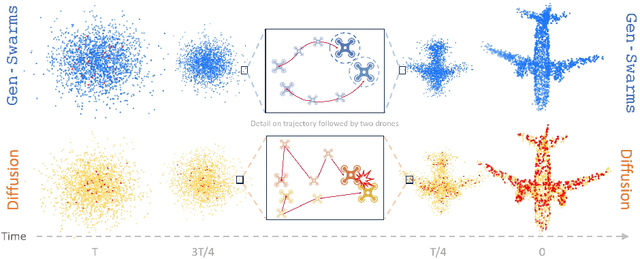
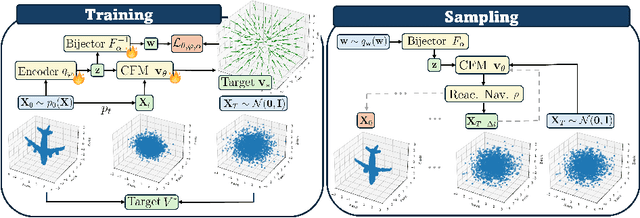
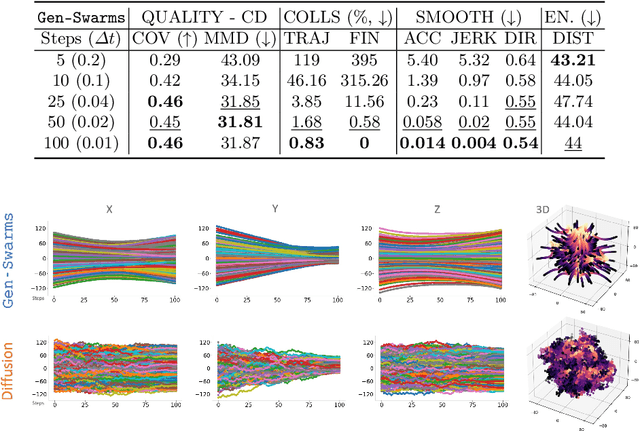
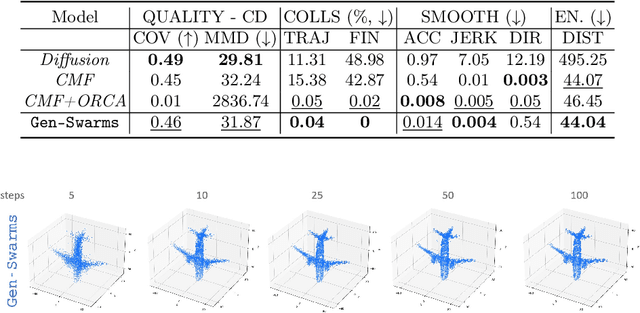
Gen-Swarms is an innovative method that leverages and combines the capabilities of deep generative models with reactive navigation algorithms to automate the creation of drone shows. Advancements in deep generative models, particularly diffusion models, have demonstrated remarkable effectiveness in generating high-quality 2D images. Building on this success, various works have extended diffusion models to 3D point cloud generation. In contrast, alternative generative models such as flow matching have been proposed, offering a simple and intuitive transition from noise to meaningful outputs. However, the application of flow matching models to 3D point cloud generation remains largely unexplored. Gen-Swarms adapts these models to automatically generate drone shows. Existing 3D point cloud generative models create point trajectories which are impractical for drone swarms. In contrast, our method not only generates accurate 3D shapes but also guides the swarm motion, producing smooth trajectories and accounting for potential collisions through a reactive navigation algorithm incorporated into the sampling process. For example, when given a text category like Airplane, Gen-Swarms can rapidly and continuously generate numerous variations of 3D airplane shapes. Our experiments demonstrate that this approach is particularly well-suited for drone shows, providing feasible trajectories, creating representative final shapes, and significantly enhancing the overall performance of drone show generation.
CARLOR @ Ego4D Step Grounding Challenge: Bayesian temporal-order priors for test time refinement
Jun 13, 2024
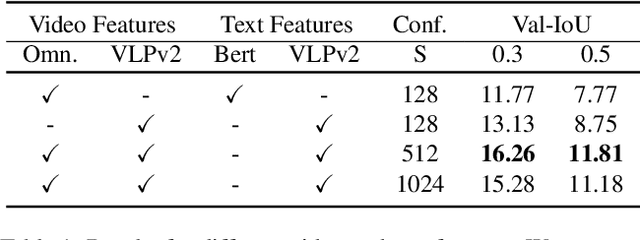


The goal of the Step Grounding task is to locate temporal boundaries of activities based on natural language descriptions. This technical report introduces a Bayesian-VSLNet to address the challenge of identifying such temporal segments in lengthy, untrimmed egocentric videos. Our model significantly improves upon traditional models by incorporating a novel Bayesian temporal-order prior during inference, enhancing the accuracy of moment predictions. This prior adjusts for cyclic and repetitive actions within videos. Our evaluations demonstrate superior performance over existing methods, achieving state-of-the-art results on the Ego4D Goal-Step dataset with a 35.18 Recall Top-1 at 0.3 IoU and 20.48 Recall Top-1 at 0.5 IoU on the test set.
EventSleep: Sleep Activity Recognition with Event Cameras
Apr 02, 2024Event cameras are a promising technology for activity recognition in dark environments due to their unique properties. However, real event camera datasets under low-lighting conditions are still scarce, which also limits the number of approaches to solve these kind of problems, hindering the potential of this technology in many applications. We present EventSleep, a new dataset and methodology to address this gap and study the suitability of event cameras for a very relevant medical application: sleep monitoring for sleep disorders analysis. The dataset contains synchronized event and infrared recordings emulating common movements that happen during the sleep, resulting in a new challenging and unique dataset for activity recognition in dark environments. Our novel pipeline is able to achieve high accuracy under these challenging conditions and incorporates a Bayesian approach (Laplace ensembles) to increase the robustness in the predictions, which is fundamental for medical applications. Our work is the first application of Bayesian neural networks for event cameras, the first use of Laplace ensembles in a realistic problem, and also demonstrates for the first time the potential of event cameras in a new application domain: to enhance current sleep evaluation procedures. Our activity recognition results highlight the potential of event cameras under dark conditions, and its capacity and robustness for sleep activity recognition, and open problems as the adaptation of event data pre-processing techniques to dark environments.
Active Exploration in Bayesian Model-based Reinforcement Learning for Robot Manipulation
Apr 02, 2024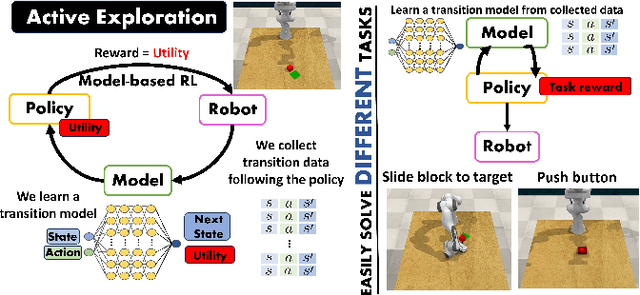
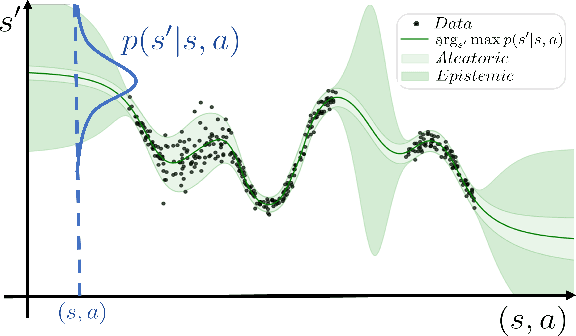
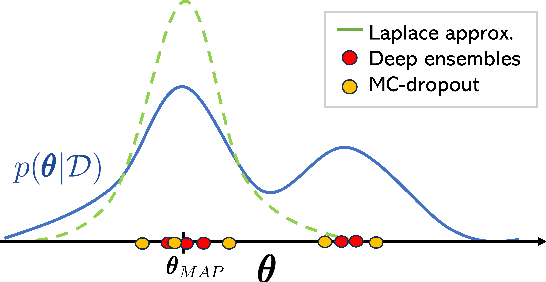
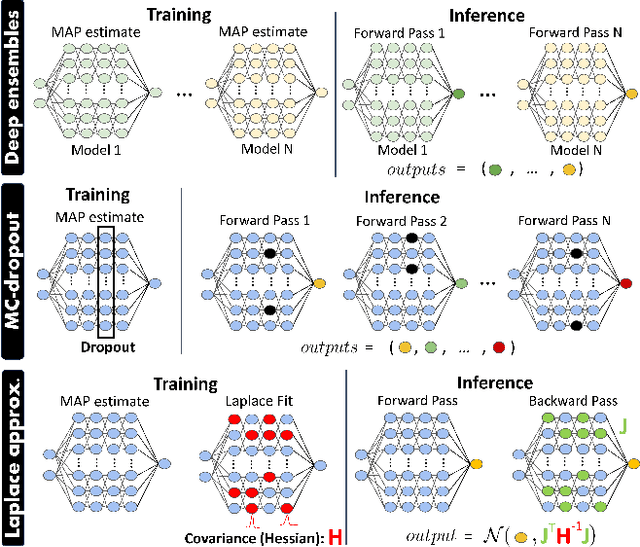
Efficiently tackling multiple tasks within complex environment, such as those found in robot manipulation, remains an ongoing challenge in robotics and an opportunity for data-driven solutions, such as reinforcement learning (RL). Model-based RL, by building a dynamic model of the robot, enables data reuse and transfer learning between tasks with the same robot and similar environment. Furthermore, data gathering in robotics is expensive and we must rely on data efficient approaches such as model-based RL, where policy learning is mostly conducted on cheaper simulations based on the learned model. Therefore, the quality of the model is fundamental for the performance of the posterior tasks. In this work, we focus on improving the quality of the model and maintaining the data efficiency by performing active learning of the dynamic model during a preliminary exploration phase based on maximize information gathering. We employ Bayesian neural network models to represent, in a probabilistic way, both the belief and information encoded in the dynamic model during exploration. With our presented strategies we manage to actively estimate the novelty of each transition, using this as the exploration reward. In this work, we compare several Bayesian inference methods for neural networks, some of which have never been used in a robotics context, and evaluate them in a realistic robot manipulation setup. Our experiments show the advantages of our Bayesian model-based RL approach, with similar quality in the results than relevant alternatives with much lower requirements regarding robot execution steps. Unlike related previous studies that focused the validation solely on toy problems, our research takes a step towards more realistic setups, tackling robotic arm end-tasks.
SpectralWaste Dataset: Multimodal Data for Waste Sorting Automation
Mar 26, 2024The increase in non-biodegradable waste is a worldwide concern. Recycling facilities play a crucial role, but their automation is hindered by the complex characteristics of waste recycling lines like clutter or object deformation. In addition, the lack of publicly available labeled data for these environments makes developing robust perception systems challenging. Our work explores the benefits of multimodal perception for object segmentation in real waste management scenarios. First, we present SpectralWaste, the first dataset collected from an operational plastic waste sorting facility that provides synchronized hyperspectral and conventional RGB images. This dataset contains labels for several categories of objects that commonly appear in sorting plants and need to be detected and separated from the main trash flow for several reasons, such as security in the management line or reuse. Additionally, we propose a pipeline employing different object segmentation architectures and evaluate the alternatives on our dataset, conducting an extensive analysis for both multimodal and unimodal alternatives. Our evaluation pays special attention to efficiency and suitability for real-time processing and demonstrates how HSI can bring a boost to RGB-only perception in these realistic industrial settings without much computational overhead.
CLIPSwarm: Generating Drone Shows from Text Prompts with Vision-Language Models
Mar 20, 2024
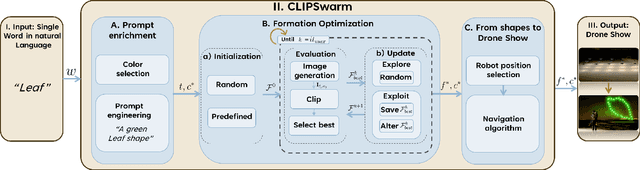
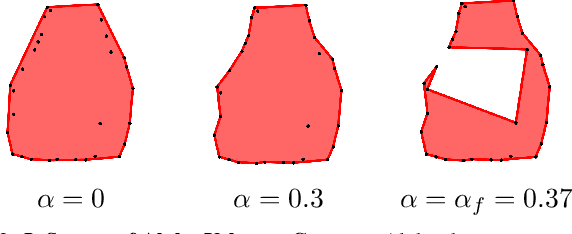

This paper introduces CLIPSwarm, a new algorithm designed to automate the modeling of swarm drone formations based on natural language. The algorithm begins by enriching a provided word, to compose a text prompt that serves as input to an iterative approach to find the formation that best matches the provided word. The algorithm iteratively refines formations of robots to align with the textual description, employing different steps for "exploration" and "exploitation". Our framework is currently evaluated on simple formation targets, limited to contour shapes. A formation is visually represented through alpha-shape contours and the most representative color is automatically found for the input word. To measure the similarity between the description and the visual representation of the formation, we use CLIP [1], encoding text and images into vectors and assessing their similarity. Subsequently, the algorithm rearranges the formation to visually represent the word more effectively, within the given constraints of available drones. Control actions are then assigned to the drones, ensuring robotic behavior and collision-free movement. Experimental results demonstrate the system's efficacy in accurately modeling robot formations from natural language descriptions. The algorithm's versatility is showcased through the execution of drone shows in photorealistic simulation with varying shapes. We refer the reader to the supplementary video for a visual reference of the results.
CineMPC: A Fully Autonomous Drone Cinematography System Incorporating Zoom, Focus, Pose, and Scene Composition
Jan 10, 2024We present CineMPC, a complete cinematographic system that autonomously controls a drone to film multiple targets recording user-specified aesthetic objectives. Existing solutions in autonomous cinematography control only the camera extrinsics, namely its position, and orientation. In contrast, CineMPC is the first solution that includes the camera intrinsic parameters in the control loop, which are essential tools for controlling cinematographic effects like focus, depth-of-field, and zoom. The system estimates the relative poses between the targets and the camera from an RGB-D image and optimizes a trajectory for the extrinsic and intrinsic camera parameters to film the artistic and technical requirements specified by the user. The drone and the camera are controlled in a nonlinear Model Predicted Control (MPC) loop by re-optimizing the trajectory at each time step in response to current conditions in the scene. The perception system of CineMPC can track the targets' position and orientation despite the camera effects. Experiments in a photorealistic simulation and with a real platform demonstrate the capabilities of the system to achieve a full array of cinematographic effects that are not possible without the control of the intrinsics of the camera. Code for CineMPC is implemented following a modular architecture in ROS and released to the community.