 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPSwarm: Converting text into formations of robots
Paper and Code
Nov 18, 2023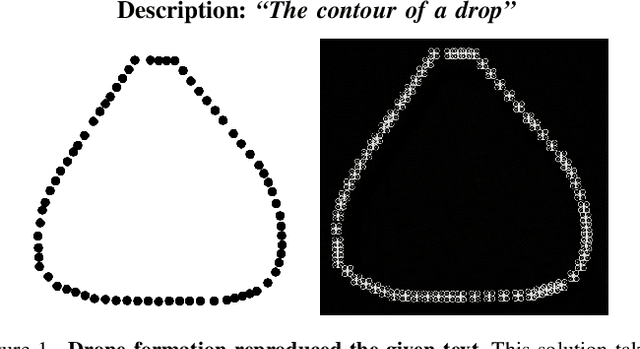
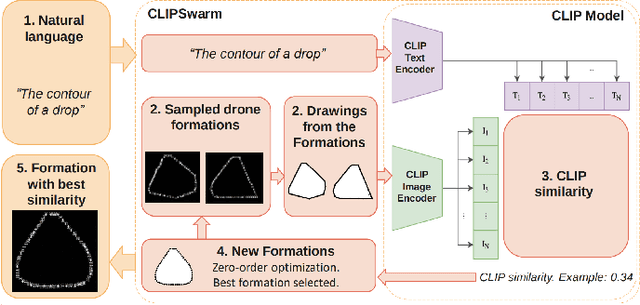
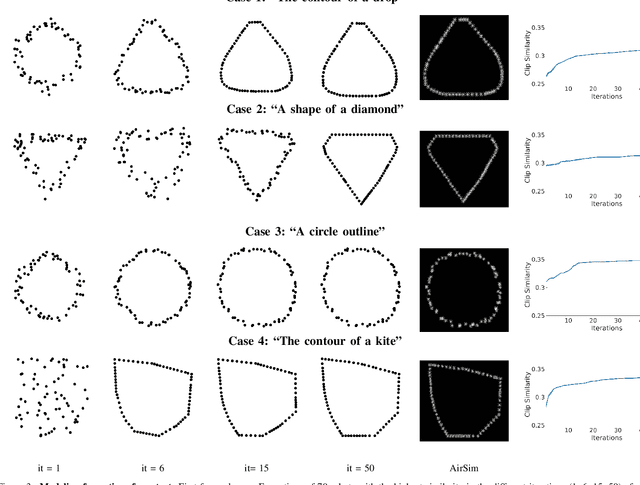
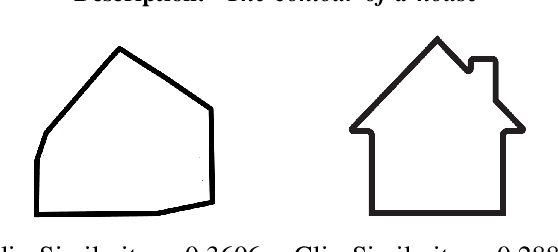
We present CLIPSwarm, an algorithm to generate robot swarm formations from natural language descriptions. CLIPSwarm receives an input text and finds the position of the robots to form a shape that corresponds to the given text. To do so, we implement a variation of the Montecarlo particle filter to obtain a matching formation iteratively. In every iteration, we generate a set of new formations and evaluate their Clip Similarity with the given text, selecting the best formations according to this metric. This metric is obtained using Clip, [1], an existing foundation model trained to encode images and texts into vectors within a common latent space. The comparison between these vectors determines how likely the given text describes the shapes. Our initial proof of concept shows the potential of this solution to generate robot swarm formations just from natural language descriptions and demonstrates a novel application of foundation models, such as CLIP, in the field of multi-robot systems. In this first approach, we create formations using a Convex-Hull approach. Next steps include more robust and generic representation and optimization steps in the process of obtaining a suitable swarm formation.