 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGen-Swarms: Adapting Deep Generative Models to Swarms of Drones
Aug 28, 2024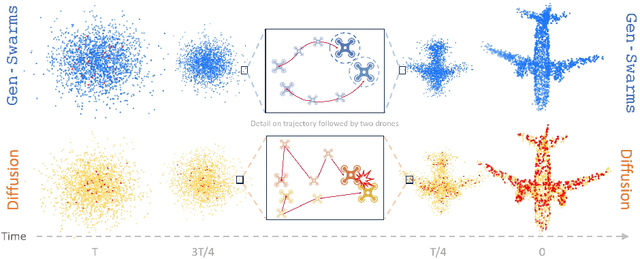
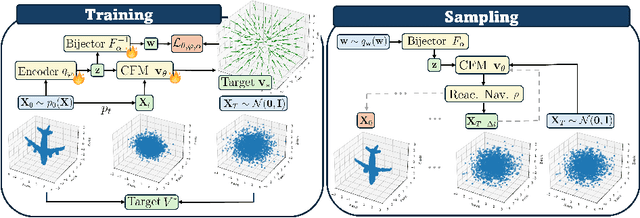
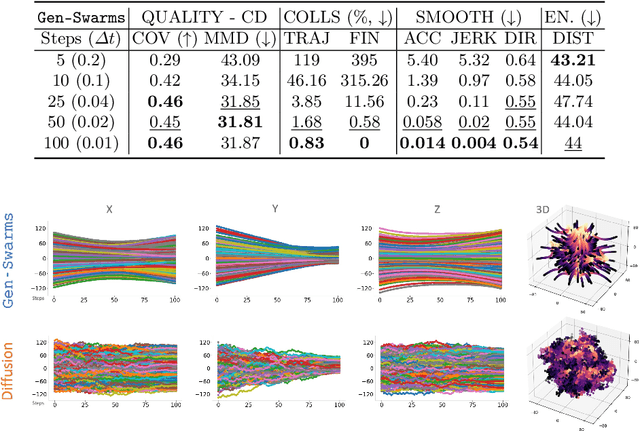
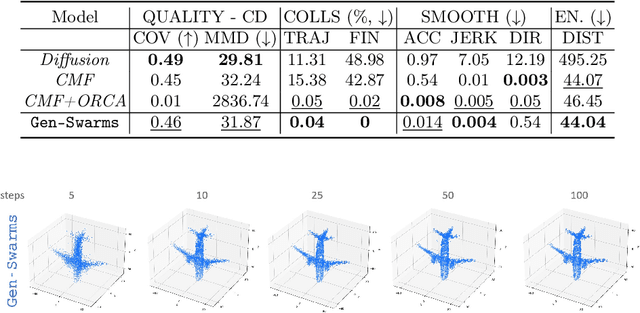
Gen-Swarms is an innovative method that leverages and combines the capabilities of deep generative models with reactive navigation algorithms to automate the creation of drone shows. Advancements in deep generative models, particularly diffusion models, have demonstrated remarkable effectiveness in generating high-quality 2D images. Building on this success, various works have extended diffusion models to 3D point cloud generation. In contrast, alternative generative models such as flow matching have been proposed, offering a simple and intuitive transition from noise to meaningful outputs. However, the application of flow matching models to 3D point cloud generation remains largely unexplored. Gen-Swarms adapts these models to automatically generate drone shows. Existing 3D point cloud generative models create point trajectories which are impractical for drone swarms. In contrast, our method not only generates accurate 3D shapes but also guides the swarm motion, producing smooth trajectories and accounting for potential collisions through a reactive navigation algorithm incorporated into the sampling process. For example, when given a text category like Airplane, Gen-Swarms can rapidly and continuously generate numerous variations of 3D airplane shapes. Our experiments demonstrate that this approach is particularly well-suited for drone shows, providing feasible trajectories, creating representative final shapes, and significantly enhancing the overall performance of drone show generation.
CLIPSwarm: Generating Drone Shows from Text Prompts with Vision-Language Models
Mar 20, 2024
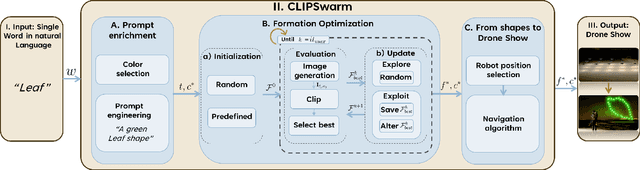
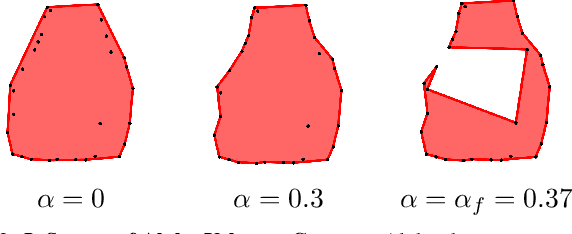

This paper introduces CLIPSwarm, a new algorithm designed to automate the modeling of swarm drone formations based on natural language. The algorithm begins by enriching a provided word, to compose a text prompt that serves as input to an iterative approach to find the formation that best matches the provided word. The algorithm iteratively refines formations of robots to align with the textual description, employing different steps for "exploration" and "exploitation". Our framework is currently evaluated on simple formation targets, limited to contour shapes. A formation is visually represented through alpha-shape contours and the most representative color is automatically found for the input word. To measure the similarity between the description and the visual representation of the formation, we use CLIP [1], encoding text and images into vectors and assessing their similarity. Subsequently, the algorithm rearranges the formation to visually represent the word more effectively, within the given constraints of available drones. Control actions are then assigned to the drones, ensuring robotic behavior and collision-free movement. Experimental results demonstrate the system's efficacy in accurately modeling robot formations from natural language descriptions. The algorithm's versatility is showcased through the execution of drone shows in photorealistic simulation with varying shapes. We refer the reader to the supplementary video for a visual reference of the results.
CineMPC: A Fully Autonomous Drone Cinematography System Incorporating Zoom, Focus, Pose, and Scene Composition
Jan 10, 2024We present CineMPC, a complete cinematographic system that autonomously controls a drone to film multiple targets recording user-specified aesthetic objectives. Existing solutions in autonomous cinematography control only the camera extrinsics, namely its position, and orientation. In contrast, CineMPC is the first solution that includes the camera intrinsic parameters in the control loop, which are essential tools for controlling cinematographic effects like focus, depth-of-field, and zoom. The system estimates the relative poses between the targets and the camera from an RGB-D image and optimizes a trajectory for the extrinsic and intrinsic camera parameters to film the artistic and technical requirements specified by the user. The drone and the camera are controlled in a nonlinear Model Predicted Control (MPC) loop by re-optimizing the trajectory at each time step in response to current conditions in the scene. The perception system of CineMPC can track the targets' position and orientation despite the camera effects. Experiments in a photorealistic simulation and with a real platform demonstrate the capabilities of the system to achieve a full array of cinematographic effects that are not possible without the control of the intrinsics of the camera. Code for CineMPC is implemented following a modular architecture in ROS and released to the community.
CLIPSwarm: Converting text into formations of robots
Nov 18, 2023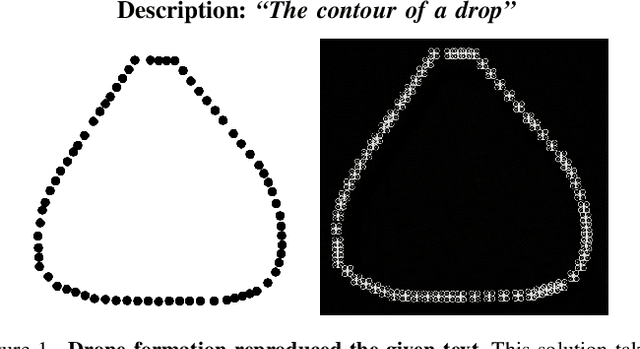
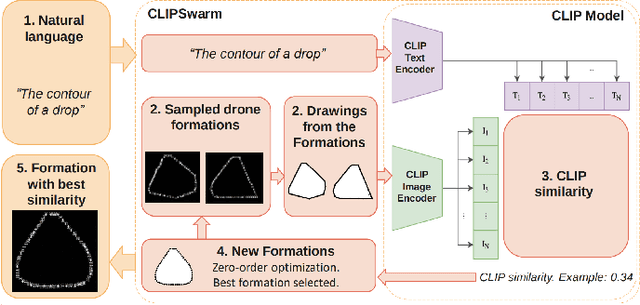
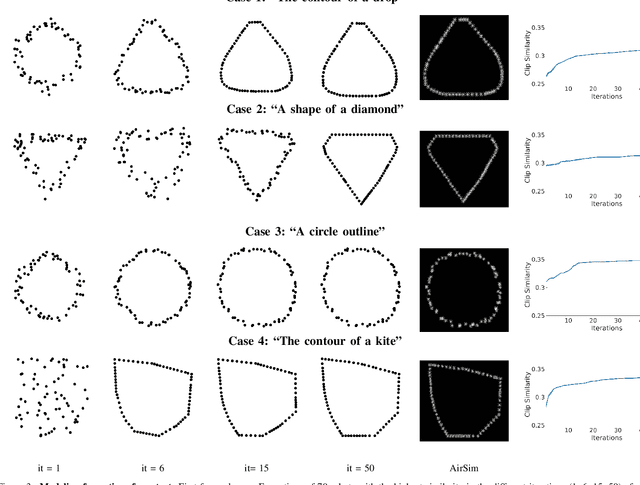
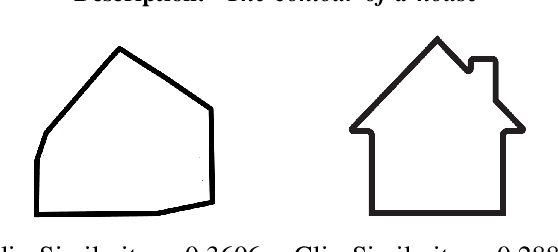
We present CLIPSwarm, an algorithm to generate robot swarm formations from natural language descriptions. CLIPSwarm receives an input text and finds the position of the robots to form a shape that corresponds to the given text. To do so, we implement a variation of the Montecarlo particle filter to obtain a matching formation iteratively. In every iteration, we generate a set of new formations and evaluate their Clip Similarity with the given text, selecting the best formations according to this metric. This metric is obtained using Clip, [1], an existing foundation model trained to encode images and texts into vectors within a common latent space. The comparison between these vectors determines how likely the given text describes the shapes. Our initial proof of concept shows the potential of this solution to generate robot swarm formations just from natural language descriptions and demonstrates a novel application of foundation models, such as CLIP, in the field of multi-robot systems. In this first approach, we create formations using a Convex-Hull approach. Next steps include more robust and generic representation and optimization steps in the process of obtaining a suitable swarm formation.
* Please cite this article as "P. Pueyo, E. Montijano, A. C. Murillo, and M. Schwager, CLIPSwarm: Converting text into formations of robots. ICRA 2023 Workshop on Multi-Robot Learning"
CineTransfer: Controlling a Robot to Imitate Cinematographic Style from a Single Example
Oct 06, 2023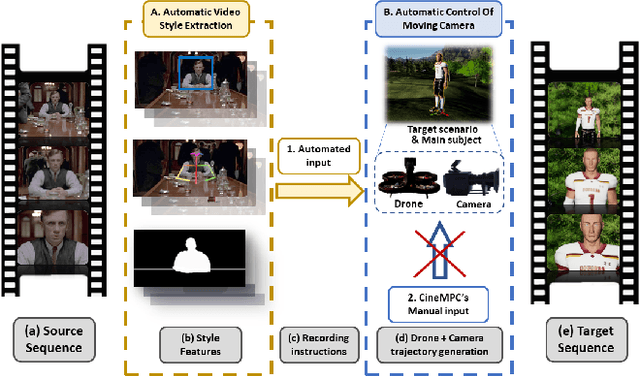

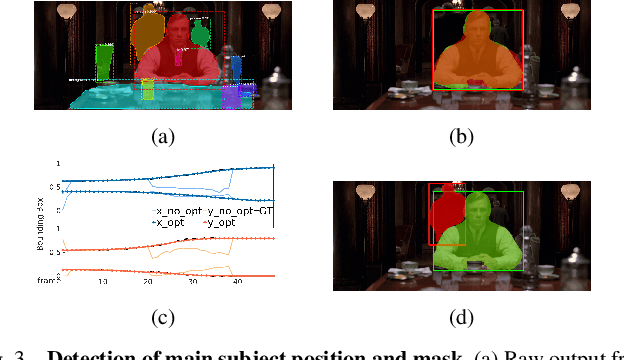
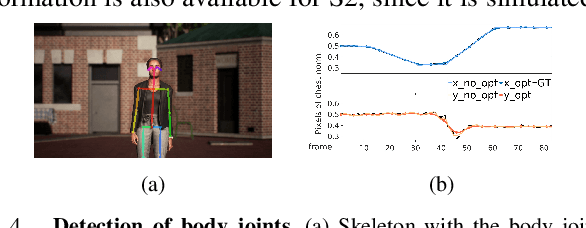
This work presents CineTransfer, an algorithmic framework that drives a robot to record a video sequence that mimics the cinematographic style of an input video. We propose features that abstract the aesthetic style of the input video, so the robot can transfer this style to a scene with visual details that are significantly different from the input video. The framework builds upon CineMPC, a tool that allows users to control cinematographic features, like subjects' position on the image and the depth of field, by manipulating the intrinsics and extrinsics of a cinematographic camera. However, CineMPC requires a human expert to specify the desired style of the shot (composition, camera motion, zoom, focus, etc). CineTransfer bridges this gap, aiming a fully autonomous cinematographic platform. The user chooses a single input video as a style guide. CineTransfer extracts and optimizes two important style features, the composition of the subject in the image and the scene depth of field, and provides instructions for CineMPC to control the robot to record an output sequence that matches these features as closely as possible. In contrast with other style transfer methods, our approach is a lightweight and portable framework which does not require deep network training or extensive datasets. Experiments with real and simulated videos demonstrate the system's ability to analyze and transfer style between recordings, and are available in the supplementary video.
CineMPC: Controlling Camera Intrinsics and Extrinsics for Autonomous Cinematography
Apr 08, 2021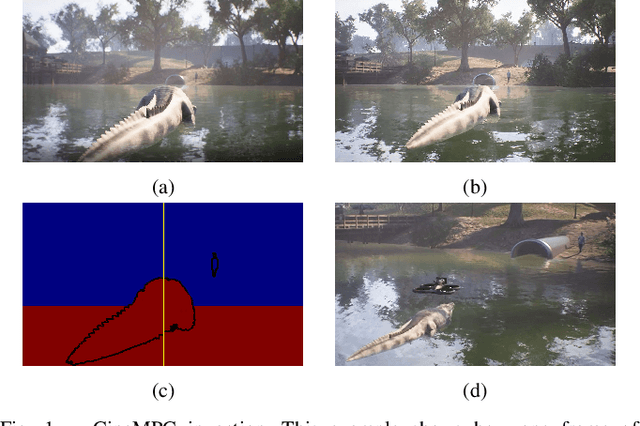


We present CineMPC, an algorithm to autonomously control a UAV-borne video camera in a nonlinear MPC loop. CineMPC controls both the position and orientation of the camera-the camera extrinsics-as well as the lens focal length, focal distance, and aperture-the camera intrinsics. While some existing solutions autonomously control the position and orientation of the camera, no existing solutions also control the intrinsic parameters, which are essential tools for rich cinematographic expression. The intrinsic parameters control the parts of the scene that are focused or blurred, and the viewers' perception of depth in the scene. Cinematographers commonly use the camera intrinsics to direct the viewers' attention through the use of focus, to convey suspense through telephoto views, inspire awe through wide-angle views, and generally to convey an emotionally rich viewing experience. Our algorithm can use any existing approach to detect the subjects in the scene, and tracks those subjects throughout a user-specified desired camera trajectory that includes camera intrinsics. CineMPC closes the loop from camera images to UAV trajectory in order to follow the desired relative trajectory as the subjects move through the scene. The cinematographer can use CineMPC to autonomously record scenes using the full array of cinematographic tools for artistic expression.
CinemAirSim: A Camera-Realistic Robotics Simulator for Cinematographic Purposes
Mar 17, 2020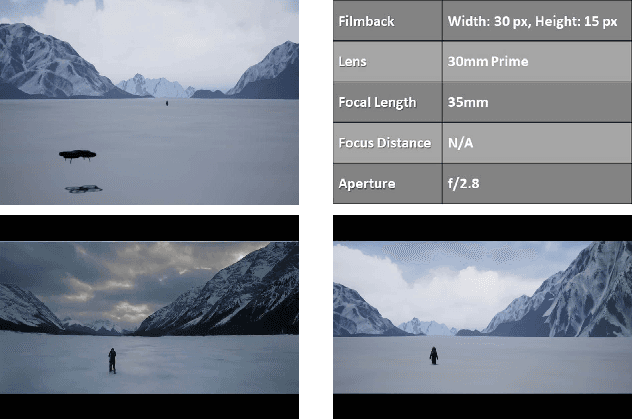
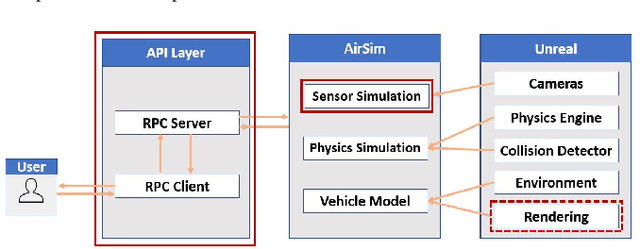


Drones and Unmanned Aerial Vehicles (UAV's) are becoming increasingly popular in the film and entertainment industries in part because of their maneuverability and the dynamic shots and perspectives they enable. While there exists methods for controlling the position and orientation of the drones for visibility, other artistic elements of the filming process, such as focal blur and light control, remain unexplored in the robotics community. The lack of cinemetographic robotics solutions is partly due to the cost associated with the cameras and devices used in the filming industry, but also because state-of-the-art photo-realistic robotics simulators only utilize a full in-focus pinhole camera model which does incorporate these desired artistic attributes. To overcome this, the main contribution of this work is to endow the well-known drone simulator, AirSim, with a cinematic camera as well as extended its API to control all of its parameters in real time, including various filming lenses and common cinematographic properties. In this paper, we detail the implementation of our AirSim modification, CinemAirSim, present examples that illustrate the potential of the new tool, and highlight the new research opportunities that the use of cinematic cameras can bring to research in robotics and control. https://github.com/ppueyor/CinematicAirSim