 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Open-Vocabulary, Task-Relevant Robot Exploration with Online Semantic Gaussian Splatting
Jul 01, 2025We present VISTA (Viewpoint-based Image selection with Semantic Task Awareness), an active exploration method for robots to plan informative trajectories that improve 3D map quality in areas most relevant for task completion. Given an open-vocabulary search instruction (e.g., "find a person"), VISTA enables a robot to explore its environment to search for the object of interest, while simultaneously building a real-time semantic 3D Gaussian Splatting reconstruction of the scene. The robot navigates its environment by planning receding-horizon trajectories that prioritize semantic similarity to the query and exploration of unseen regions of the environment. To evaluate trajectories, VISTA introduces a novel, efficient viewpoint-semantic coverage metric that quantifies both the geometric view diversity and task relevance in the 3D scene. On static datasets, our coverage metric outperforms state-of-the-art baselines, FisherRF and Bayes' Rays, in computation speed and reconstruction quality. In quadrotor hardware experiments, VISTA achieves 6x higher success rates in challenging maps, compared to baseline methods, while matching baseline performance in less challenging maps. Lastly, we show that VISTA is platform-agnostic by deploying it on a quadrotor drone and a Spot quadruped robot. Open-source code will be released upon acceptance of the paper.
Clio: Real-time Task-Driven Open-Set 3D Scene Graphs
Apr 29, 2024



Modern tools for class-agnostic image segmentation (e.g., SegmentAnything) and open-set semantic understanding (e.g., CLIP) provide unprecedented opportunities for robot perception and mapping. While traditional closed-set metric-semantic maps were restricted to tens or hundreds of semantic classes, we can now build maps with a plethora of objects and countless semantic variations. This leaves us with a fundamental question: what is the right granularity for the objects (and, more generally, for the semantic concepts) the robot has to include in its map representation? While related work implicitly chooses a level of granularity by tuning thresholds for object detection, we argue that such a choice is intrinsically task-dependent. The first contribution of this paper is to propose a task-driven 3D scene understanding problem, where the robot is given a list of tasks in natural language and has to select the granularity and the subset of objects and scene structure to retain in its map that is sufficient to complete the tasks. We show that this problem can be naturally formulated using the Information Bottleneck (IB), an established information-theoretic framework. The second contribution is an algorithm for task-driven 3D scene understanding based on an Agglomerative IB approach, that is able to cluster 3D primitives in the environment into task-relevant objects and regions and executes incrementally. The third contribution is to integrate our task-driven clustering algorithm into a real-time pipeline, named Clio, that constructs a hierarchical 3D scene graph of the environment online using only onboard compute, as the robot explores it. Our final contribution is an extensive experimental campaign showing that Clio not only allows real-time construction of compact open-set 3D scene graphs, but also improves the accuracy of task execution by limiting the map to relevant semantic concepts.
GeoD: Consensus-based Geodesic Distributed Pose Graph Optimization
Oct 01, 2020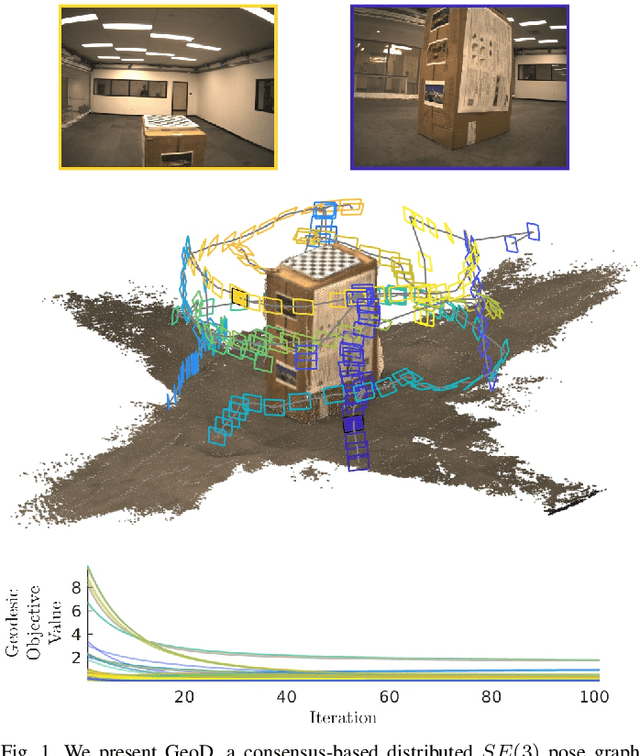
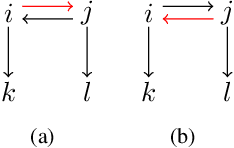
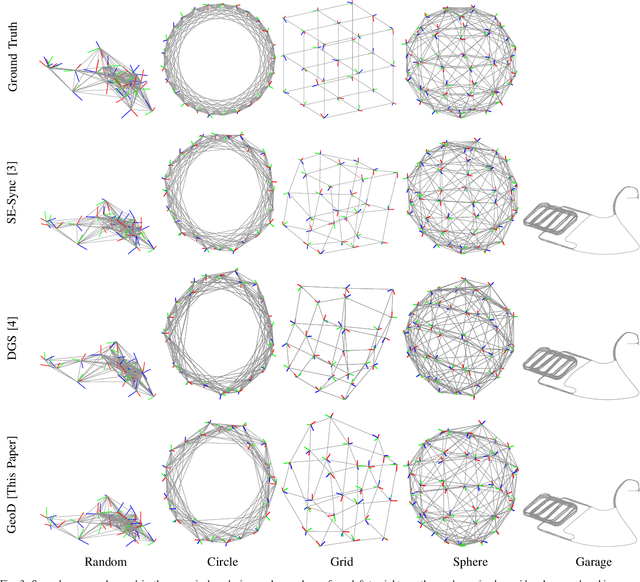
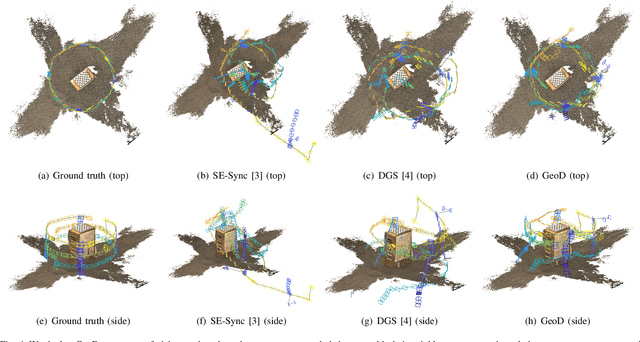
We present a consensus-based distributed pose graph optimization algorithm for obtaining an estimate of the 3D translation and rotation of each pose in a pose graph, given noisy relative measurements between poses. The algorithm, called GeoD, implements a continuous time distributed consensus protocol to minimize the geodesic pose graph error. GeoD is distributed over the pose graph itself, with a separate computation thread for each node in the graph, and messages are passed only between neighboring nodes in the graph. We leverage tools from Lyapunov theory and multi-agent consensus to prove the convergence of the algorithm. We identify two new consistency conditions sufficient for convergence: pairwise consistency of relative rotation measurements, and minimal consistency of relative translation measurements. GeoD incorporates a simple one step distributed initialization to satisfy both conditions. We demonstrate GeoD on simulated and real world SLAM datasets. We compare to a centralized pose graph optimizer with an optimality certificate (SE-Sync) and a Distributed Gauss-Seidel (DGS) method. On average, GeoD converges 20 times more quickly than DGS to a value with 3.4 times less error when compared to the global minimum provided by SE-Sync. GeoD scales more favorably with graph size than DGS, converging over 100 times faster on graphs larger than 1000 poses. Lastly, we test GeoD on a multi-UAV vision-based SLAM scenario, where the UAVs estimate their pose trajectories in a distributed manner using the relative poses extracted from their on board camera images. We show qualitative performance that is better than either the centralized SE-Sync or the distributed DGS methods.
CinemAirSim: A Camera-Realistic Robotics Simulator for Cinematographic Purposes
Mar 17, 2020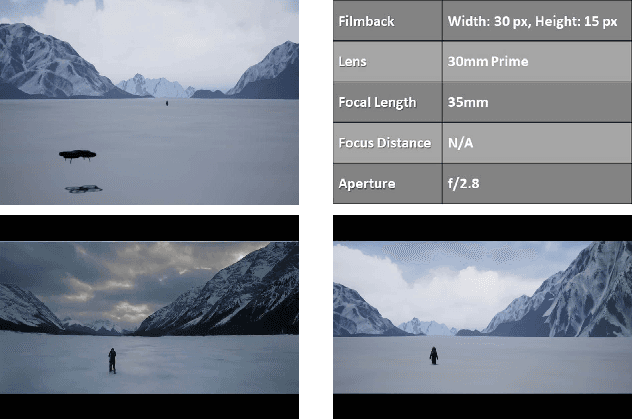
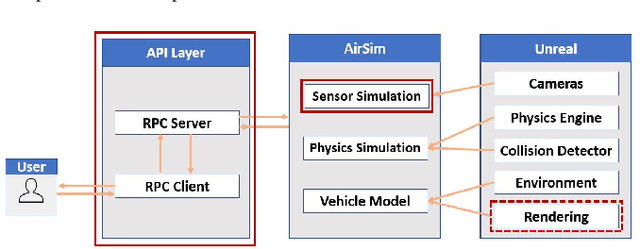


Drones and Unmanned Aerial Vehicles (UAV's) are becoming increasingly popular in the film and entertainment industries in part because of their maneuverability and the dynamic shots and perspectives they enable. While there exists methods for controlling the position and orientation of the drones for visibility, other artistic elements of the filming process, such as focal blur and light control, remain unexplored in the robotics community. The lack of cinemetographic robotics solutions is partly due to the cost associated with the cameras and devices used in the filming industry, but also because state-of-the-art photo-realistic robotics simulators only utilize a full in-focus pinhole camera model which does incorporate these desired artistic attributes. To overcome this, the main contribution of this work is to endow the well-known drone simulator, AirSim, with a cinematic camera as well as extended its API to control all of its parameters in real time, including various filming lenses and common cinematographic properties. In this paper, we detail the implementation of our AirSim modification, CinemAirSim, present examples that illustrate the potential of the new tool, and highlight the new research opportunities that the use of cinematic cameras can bring to research in robotics and control. https://github.com/ppueyor/CinematicAirSim
AirSim Drone Racing Lab
Mar 12, 2020



Autonomous drone racing is a challenging research problem at the intersection of computer vision, planning, state estimation, and control. We introduce AirSim Drone Racing Lab, a simulation framework for enabling fast prototyping of algorithms for autonomy and enabling machine learning research in this domain, with the goal of reducing the time, money, and risks associated with field robotics. Our framework enables generation of racing tracks in multiple photo-realistic environments, orchestration of drone races, comes with a suite of gate assets, allows for multiple sensor modalities (monocular, depth, neuromorphic events, optical flow), different camera models, and benchmarking of planning, control, computer vision, and learning-based algorithms. We used our framework to host a simulation based drone racing competition at NeurIPS 2019. The competition binaries are available at our github repository.
A Real-Time Game Theoretic Planner for Autonomous Two-Player Drone Racing
Jan 26, 2018
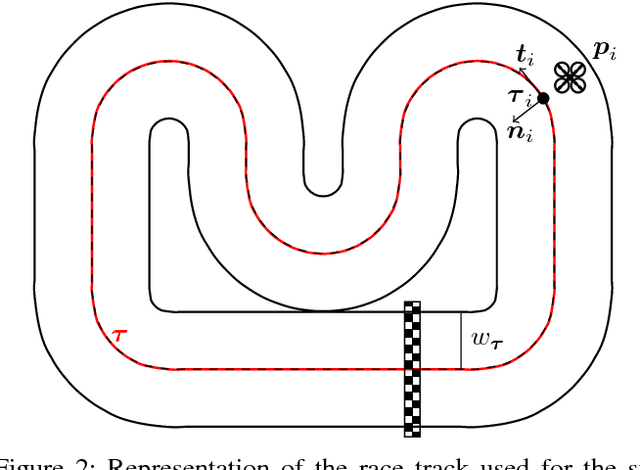
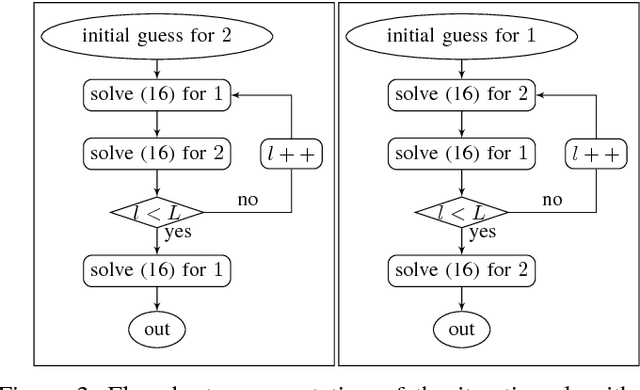
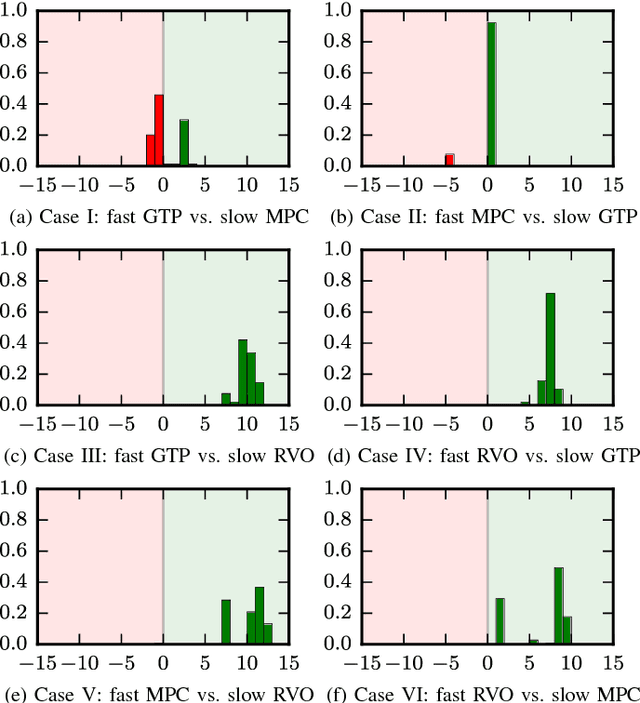
To be successful in multi-player drone racing, a player must not only follow the race track in an optimal way, but also compete with other drones through strategic blocking, faking, and opportunistic passing while avoiding collisions. Since unveiling one's own strategy to the adversaries is not desirable, this requires each player to independently predict the other players' future actions. Nash equilibria are a powerful tool to model this and similar multi-agent coordination problems in which the absence of communication impedes full coordination between the agents. In this paper, we propose a novel receding horizon planning algorithm that, exploiting sensitivity analysis within an iterated best response computational scheme, can approximate Nash equilibria in real time. We also describe a vision-based pipeline that allows each player to estimate its opponent's relative position. We demonstrate that our solution effectively competes against alternative strategies in a large number of drone racing simulations. Hardware experiments with onboard vision sensing prove the practicality of our strategy.
Out-of-focus: Learning Depth from Image Bokeh for Robotic Perception
May 02, 2017
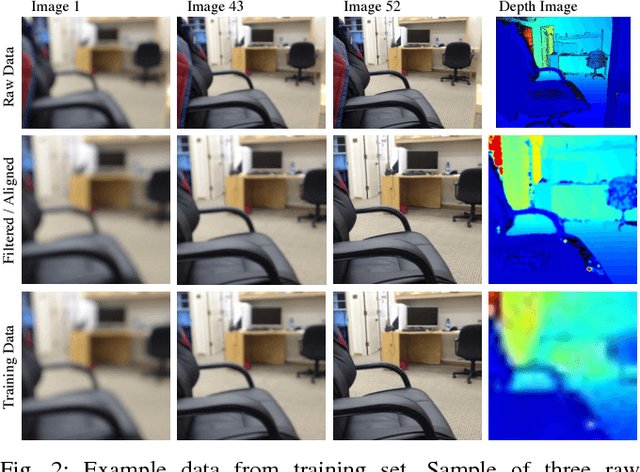

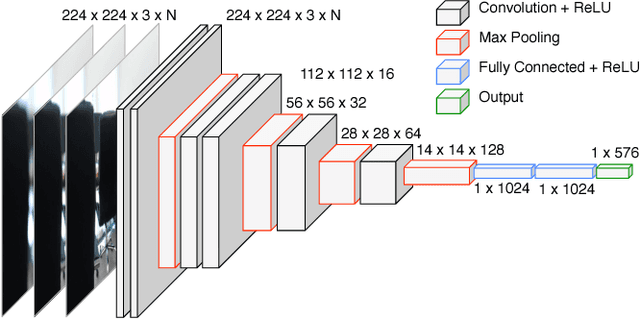
In this project, we propose a novel approach for estimating depth from RGB images. Traditionally, most work uses a single RGB image to estimate depth, which is inherently difficult and generally results in poor performance, even with thousands of data examples. In this work, we alternatively use multiple RGB images that were captured while changing the focus of the camera's lens. This method leverages the natural depth information correlated to the different patterns of clarity/blur in the sequence of focal images, which helps distinguish objects at different depths. Since no such data set exists for learning this mapping, we collect our own data set using customized hardware. We then use a convolutional neural network for learning the depth from the stacked focal images. Comparative studies were conducted on both a standard RGBD data set and our own data set (learning from both single and multiple images), and results verified that stacked focal images yield better depth estimation than using just single RGB image.