 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverage Optimization for Camera View Selection
Apr 06, 2026What makes a good viewpoint? The quality of the data used to learn 3D reconstructions is crucial for enabling efficient and accurate scene modeling. We study the active view selection problem and develop a principled analysis that yields a simple and interpretable criterion for selecting informative camera poses. Our key insight is that informative views can be obtained by minimizing a tractable approximation of the Fisher Information Gain, which reduces to favoring viewpoints that cover geometry that has been insufficiently observed by past cameras. This leads to a lightweight coverage-based view selection metric that avoids expensive transmittance estimation and is robust to noise and training dynamics. We call this metric COVER (Camera Optimization for View Exploration and Reconstruction). We integrate our method into the Nerfstudio framework and evaluate it on real datasets within fixed and embodied data acquisition scenarios. Across multiple datasets and radiance-field baselines, our method consistently improves reconstruction quality compared to state-of-the-art active view selection methods. Additional visualizations and our Nerfstudio package can be found at https://chengine.github.io/nbv_gym/.
Semantic-Metric Bayesian Risk Fields: Learning Robot Safety from Human Videos with a VLM Prior
Dec 09, 2025Humans interpret safety not as a binary signal but as a continuous, context- and spatially-dependent notion of risk. While risk is subjective, humans form rational mental models that guide action selection in dynamic environments. This work proposes a framework for extracting implicit human risk models by introducing a novel, semantically-conditioned and spatially-varying parametrization of risk, supervised directly from safe human demonstration videos and VLM common sense. Notably, we define risk through a Bayesian formulation. The prior is furnished by a pretrained vision-language model. In order to encourage the risk estimate to be more human aligned, a likelihood function modulates the prior to produce a relative metric of risk. Specifically, the likelihood is a learned ViT that maps pretrained features, to pixel-aligned risk values. Our pipeline ingests RGB images and a query object string, producing pixel-dense risk images. These images that can then be used as value-predictors in robot planning tasks or be projected into 3D for use in conventional trajectory optimization to produce human-like motion. This learned mapping enables generalization to novel objects and contexts, and has the potential to scale to much larger training datasets. In particular, the Bayesian framework that is introduced enables fast adaptation of our model to additional observations or common sense rules. We demonstrate that our proposed framework produces contextual risk that aligns with human preferences. Additionally, we illustrate several downstream applications of the model; as a value learner for visuomotor planners or in conjunction with a classical trajectory optimization algorithm. Our results suggest that our framework is a significant step toward enabling autonomous systems to internalize human-like risk. Code and results can be found at https://riskbayesian.github.io/bayesian_risk/.
VISTA: Open-Vocabulary, Task-Relevant Robot Exploration with Online Semantic Gaussian Splatting
Jul 01, 2025We present VISTA (Viewpoint-based Image selection with Semantic Task Awareness), an active exploration method for robots to plan informative trajectories that improve 3D map quality in areas most relevant for task completion. Given an open-vocabulary search instruction (e.g., "find a person"), VISTA enables a robot to explore its environment to search for the object of interest, while simultaneously building a real-time semantic 3D Gaussian Splatting reconstruction of the scene. The robot navigates its environment by planning receding-horizon trajectories that prioritize semantic similarity to the query and exploration of unseen regions of the environment. To evaluate trajectories, VISTA introduces a novel, efficient viewpoint-semantic coverage metric that quantifies both the geometric view diversity and task relevance in the 3D scene. On static datasets, our coverage metric outperforms state-of-the-art baselines, FisherRF and Bayes' Rays, in computation speed and reconstruction quality. In quadrotor hardware experiments, VISTA achieves 6x higher success rates in challenging maps, compared to baseline methods, while matching baseline performance in less challenging maps. Lastly, we show that VISTA is platform-agnostic by deploying it on a quadrotor drone and a Spot quadruped robot. Open-source code will be released upon acceptance of the paper.
GRaD-Nav: Efficiently Learning Visual Drone Navigation with Gaussian Radiance Fields and Differentiable Dynamics
Mar 06, 2025Autonomous visual navigation is an essential element in robot autonomy. Reinforcement learning (RL) offers a promising policy training paradigm. However existing RL methods suffer from high sample complexity, poor sim-to-real transfer, and limited runtime adaptability to navigation scenarios not seen during training. These problems are particularly challenging for drones, with complex nonlinear and unstable dynamics, and strong dynamic coupling between control and perception. In this paper, we propose a novel framework that integrates 3D Gaussian Splatting (3DGS) with differentiable deep reinforcement learning (DDRL) to train vision-based drone navigation policies. By leveraging high-fidelity 3D scene representations and differentiable simulation, our method improves sample efficiency and sim-to-real transfer. Additionally, we incorporate a Context-aided Estimator Network (CENet) to adapt to environmental variations at runtime. Moreover, by curriculum training in a mixture of different surrounding environments, we achieve in-task generalization, the ability to solve new instances of a task not seen during training. Drone hardware experiments demonstrate our method's high training efficiency compared to state-of-the-art RL methods, zero shot sim-to-real transfer for real robot deployment without fine tuning, and ability to adapt to new instances within the same task class (e.g. to fly through a gate at different locations with different distractors in the environment).
HAMMER: Heterogeneous, Multi-Robot Semantic Gaussian Splatting
Jan 24, 2025



3D Gaussian Splatting offers expressive scene reconstruction, modeling a broad range of visual, geometric, and semantic information. However, efficient real-time map reconstruction with data streamed from multiple robots and devices remains a challenge. To that end, we propose HAMMER, a server-based collaborative Gaussian Splatting method that leverages widely available ROS communication infrastructure to generate 3D, metric-semantic maps from asynchronous robot data-streams with no prior knowledge of initial robot positions and varying on-device pose estimators. HAMMER consists of (i) a frame alignment module that transforms local SLAM poses and image data into a global frame and requires no prior relative pose knowledge, and (ii) an online module for training semantic 3DGS maps from streaming data. HAMMER handles mixed perception modes, adjusts automatically for variations in image pre-processing among different devices, and distills CLIP semantic codes into the 3D scene for open-vocabulary language queries. In our real-world experiments, HAMMER creates higher-fidelity maps (2x) compared to competing baselines and is useful for downstream tasks, such as semantic goal-conditioned navigation (e.g., ``go to the couch"). Accompanying content available at hammer-project.github.io.
SAFER-Splat: A Control Barrier Function for Safe Navigation with Online Gaussian Splatting Maps
Sep 15, 2024SAFER-Splat (Simultaneous Action Filtering and Environment Reconstruction) is a real-time, scalable, and minimally invasive action filter, based on control barrier functions, for safe robotic navigation in a detailed map constructed at runtime using Gaussian Splatting (GSplat). We propose a novel Control Barrier Function (CBF) that not only induces safety with respect to all Gaussian primitives in the scene, but when synthesized into a controller, is capable of processing hundreds of thousands of Gaussians while maintaining a minimal memory footprint and operating at 15 Hz during online Splat training. Of the total compute time, a small fraction of it consumes GPU resources, enabling uninterrupted training. The safety layer is minimally invasive, correcting robot actions only when they are unsafe. To showcase the safety filter, we also introduce SplatBridge, an open-source software package built with ROS for real-time GSplat mapping for robots. We demonstrate the safety and robustness of our pipeline first in simulation, where our method is 20-50x faster, safer, and less conservative than competing methods based on neural radiance fields. Further, we demonstrate simultaneous GSplat mapping and safety filtering on a drone hardware platform using only on-board perception. We verify that under teleoperation a human pilot cannot invoke a collision. Our videos and codebase can be found at https://chengine.github.io/safer-splat.
Splat-MOVER: Multi-Stage, Open-Vocabulary Robotic Manipulation via Editable Gaussian Splatting
May 14, 2024



We present Splat-MOVER, a modular robotics stack for open-vocabulary robotic manipulation, which leverages the editability of Gaussian Splatting (GSplat) scene representations to enable multi-stage manipulation tasks. Splat-MOVER consists of: (i) ASK-Splat, a GSplat representation that distills latent codes for language semantics and grasp affordance into the 3D scene. ASK-Splat enables geometric, semantic, and affordance understanding of 3D scenes, which is critical for many robotics tasks; (ii) SEE-Splat, a real-time scene-editing module using 3D semantic masking and infilling to visualize the motions of objects that result from robot interactions in the real-world. SEE-Splat creates a "digital twin" of the evolving environment throughout the manipulation task; and (iii) Grasp-Splat, a grasp generation module that uses ASK-Splat and SEE-Splat to propose candidate grasps for open-world objects. ASK-Splat is trained in real-time from RGB images in a brief scanning phase prior to operation, while SEE-Splat and Grasp-Splat run in real-time during operation. We demonstrate the superior performance of Splat-MOVER in hardware experiments on a Kinova robot compared to two recent baselines in four single-stage, open-vocabulary manipulation tasks, as well as in four multi-stage manipulation tasks using the edited scene to reflect scene changes due to prior manipulation stages, which is not possible with the existing baselines. Code for this project and a link to the project page will be made available soon.
$\textbf{Splat-MOVER}$: Multi-Stage, Open-Vocabulary Robotic Manipulation via Editable Gaussian Splatting
May 07, 2024We present Splat-MOVER, a modular robotics stack for open-vocabulary robotic manipulation, which leverages the editability of Gaussian Splatting (GSplat) scene representations to enable multi-stage manipulation tasks. Splat-MOVER consists of: (i) $\textit{ASK-Splat}$, a GSplat representation that distills latent codes for language semantics and grasp affordance into the 3D scene. ASK-Splat enables geometric, semantic, and affordance understanding of 3D scenes, which is critical for many robotics tasks; (ii) $\textit{SEE-Splat}$, a real-time scene-editing module using 3D semantic masking and infilling to visualize the motions of objects that result from robot interactions in the real-world. SEE-Splat creates a "digital twin" of the evolving environment throughout the manipulation task; and (iii) $\textit{Grasp-Splat}$, a grasp generation module that uses ASK-Splat and SEE-Splat to propose candidate grasps for open-world objects. ASK-Splat is trained in real-time from RGB images in a brief scanning phase prior to operation, while SEE-Splat and Grasp-Splat run in real-time during operation. We demonstrate the superior performance of Splat-MOVER in hardware experiments on a Kinova robot compared to two recent baselines in four single-stage, open-vocabulary manipulation tasks, as well as in four multi-stage manipulation tasks using the edited scene to reflect scene changes due to prior manipulation stages, which is not possible with the existing baselines. Code for this project and a link to the project page will be made available soon.
Splat-Nav: Safe Real-Time Robot Navigation in Gaussian Splatting Maps
Mar 05, 2024We present Splat-Nav, a navigation pipeline that consists of a real-time safe planning module and a robust state estimation module designed to operate in the Gaussian Splatting (GSplat) environment representation, a popular emerging 3D scene representation from computer vision. We formulate rigorous collision constraints that can be computed quickly to build a guaranteed-safe polytope corridor through the map. We then optimize a B-spline trajectory through this corridor. We also develop a real-time, robust state estimation module by interpreting the GSplat representation as a point cloud. The module enables the robot to localize its global pose with zero prior knowledge from RGB-D images using point cloud alignment, and then track its own pose as it moves through the scene from RGB images using image-to-point cloud localization. We also incorporate semantics into the GSplat in order to obtain better images for localization. All of these modules operate mainly on CPU, freeing up GPU resources for tasks like real-time scene reconstruction. We demonstrate the safety and robustness of our pipeline in both simulation and hardware, where we show re-planning at 5 Hz and pose estimation at 20 Hz, an order of magnitude faster than Neural Radiance Field (NeRF)-based navigation methods, thereby enabling real-time navigation.
CATNIPS: Collision Avoidance Through Neural Implicit Probabilistic Scenes
Feb 24, 2023
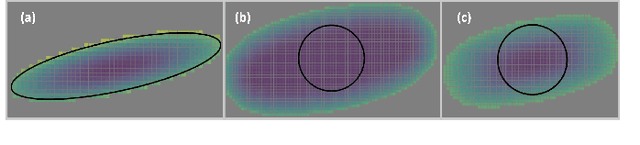
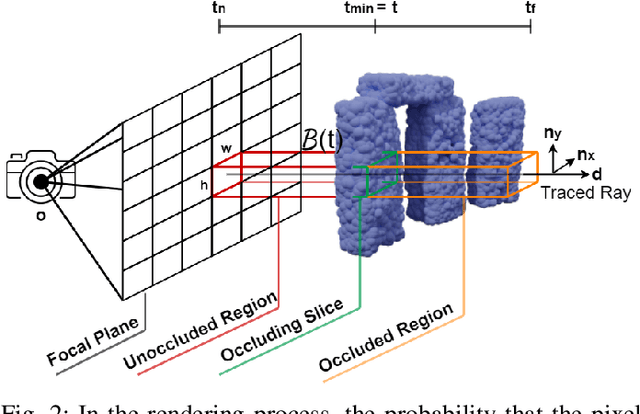

We formalize a novel interpretation of Neural Radiance Fields (NeRFs) as giving rise to a Poisson Point Process (PPP). This PPP interpretation allows for rigorous quantification of uncertainty in NeRFs, in particular, for computing collision probabilities for a robot navigating through a NeRF environment model. The PPP is a generalization of a probabilistic occupancy grid to the continuous volume and is fundamental to the volumetric ray-tracing model underlying radiance fields. Building upon this PPP model, we present a chance-constrained trajectory optimization method for safe robot navigation in NeRFs. Our method relies on a voxel representation called the Probabilistic Unsafe Robot Region (PURR) that spatially fuses the chance constraint with the NeRF model to facilitate fast trajectory optimization. We then combine a graph-based search with a spline-based trajectory optimization to yield robot trajectories through the NeRF that are guaranteed to satisfy a user-specific collision probability. We validate our chance constrained planning method through simulations, showing superior performance compared with two other methods for trajectory planning in NeRF environment models.