 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Only Robot Navigation in a Neural Radiance World
Oct 01, 2021
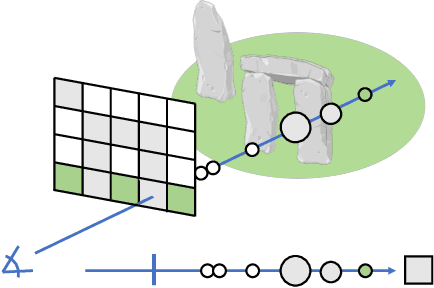
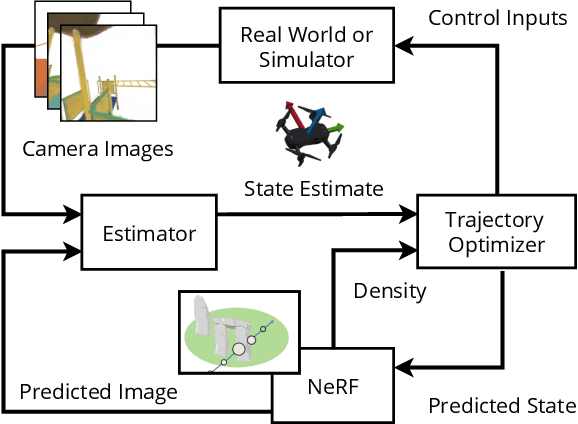
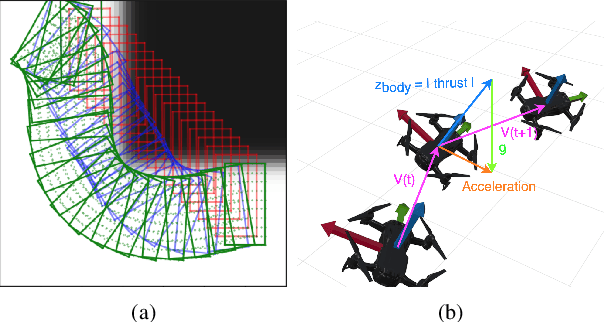
Neural Radiance Fields (NeRFs) have recently emerged as a powerful paradigm for the representation of natural, complex 3D scenes. NeRFs represent continuous volumetric density and RGB values in a neural network, and generate photo-realistic images from unseen camera viewpoints through ray tracing. We propose an algorithm for navigating a robot through a 3D environment represented as a NeRF using only an on-board RGB camera for localization. We assume the NeRF for the scene has been pre-trained offline, and the robot's objective is to navigate through unoccupied space in the NeRF to reach a goal pose. We introduce a trajectory optimization algorithm that avoids collisions with high-density regions in the NeRF based on a discrete time version of differential flatness that is amenable to constraining the robot's full pose and control inputs. We also introduce an optimization based filtering method to estimate 6DoF pose and velocities for the robot in the NeRF given only an onboard RGB camera. We combine the trajectory planner with the pose filter in an online replanning loop to give a vision-based robot navigation pipeline. We present simulation results with a quadrotor robot navigating through a jungle gym environment, the inside of a church, and Stonehenge using only an RGB camera. We also demonstrate an omnidirectional ground robot navigating through the church, requiring it to reorient to fit through the narrow gap. Videos of this work can be found at https://mikh3x4.github.io/nerf-navigation/ .
Determining Question-Answer Plausibility in Crowdsourced Datasets Using Multi-Task Learning
Nov 10, 2020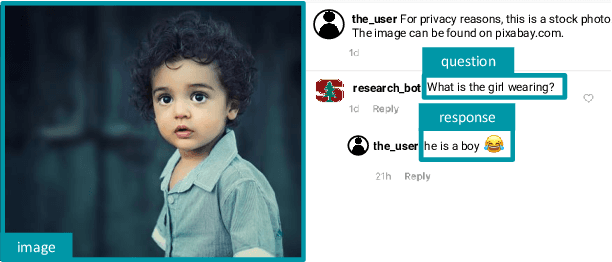
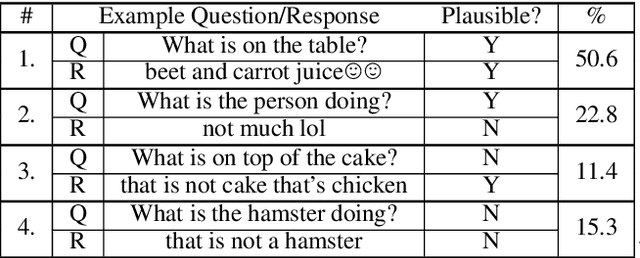
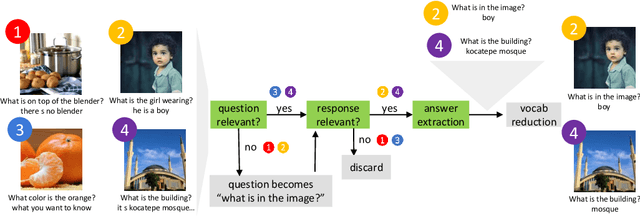

Datasets extracted from social networks and online forums are often prone to the pitfalls of natural language, namely the presence of unstructured and noisy data. In this work, we seek to enable the collection of high-quality question-answer datasets from social media by proposing a novel task for automated quality analysis and data cleaning: question-answer (QA) plausibility. Given a machine or user-generated question and a crowd-sourced response from a social media user, we determine if the question and response are valid; if so, we identify the answer within the free-form response. We design BERT-based models to perform the QA plausibility task, and we evaluate the ability of our models to generate a clean, usable question-answer dataset. Our highest-performing approach consists of a single-task model which determines the plausibility of the question, followed by a multi-task model which evaluates the plausibility of the response as well as extracts answers (Question Plausibility AUROC=0.75, Response Plausibility AUROC=0.78, Answer Extraction F1=0.665).
Variable Impedance Control in End-Effector Space: An Action Space for Reinforcement Learning in Contact-Rich Tasks
Aug 02, 2019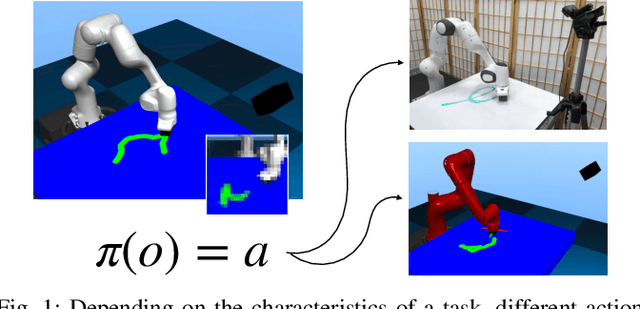
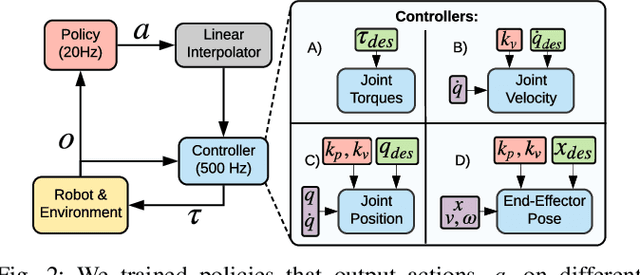
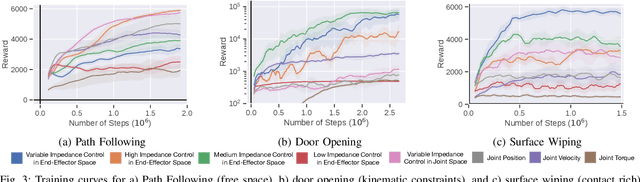
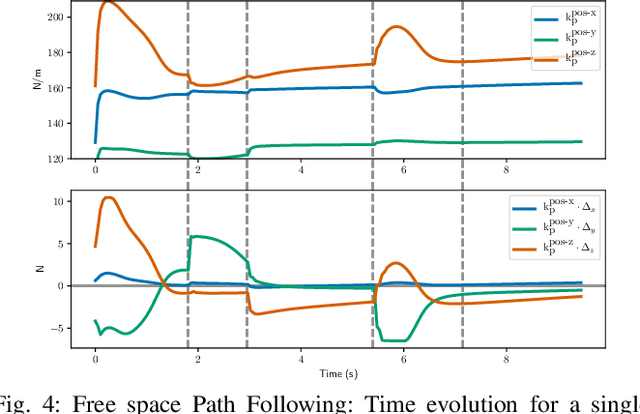
Reinforcement Learning (RL) of contact-rich manipulation tasks has yielded impressive results in recent years. While many studies in RL focus on varying the observation space or reward model, few efforts focused on the choice of action space (e.g. joint or end-effector space, position, velocity, etc.). However, studies in robot motion control indicate that choosing an action space that conforms to the characteristics of the task can simplify exploration and improve robustness to disturbances. This paper studies the effect of different action spaces in deep RL and advocates for Variable Impedance Control in End-effector Space (VICES) as an advantageous action space for constrained and contact-rich tasks. We evaluate multiple action spaces on three prototypical manipulation tasks: Path Following (task with no contact), Door Opening (task with kinematic constraints), and Surface Wiping (task with continuous contact). We show that VICES improves sample efficiency, maintains low energy consumption, and ensures safety across all three experimental setups. Further, RL policies learned with VICES can transfer across different robot models in simulation, and from simulation to real for the same robot. Further information is available at https://stanfordvl.github.io/vices.