 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvDNeRF: Reconstructing Event Data with Dynamic Neural Radiance Fields
Oct 03, 2023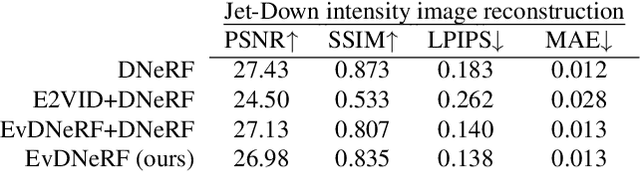


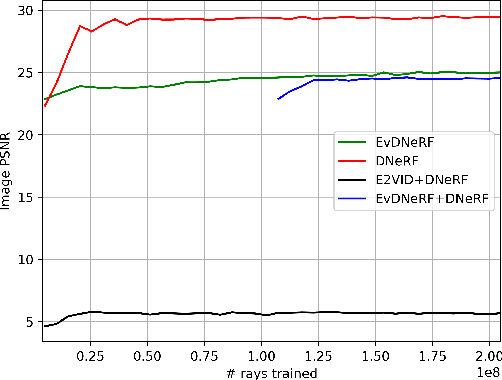
We present EvDNeRF, a pipeline for generating event data and training an event-based dynamic NeRF, for the purpose of faithfully reconstructing eventstreams on scenes with rigid and non-rigid deformations that may be too fast to capture with a standard camera. Event cameras register asynchronous per-pixel brightness changes at MHz rates with high dynamic range, making them ideal for observing fast motion with almost no motion blur. Neural radiance fields (NeRFs) offer visual-quality geometric-based learnable rendering, but prior work with events has only considered reconstruction of static scenes. Our EvDNeRF can predict eventstreams of dynamic scenes from a static or moving viewpoint between any desired timestamps, thereby allowing it to be used as an event-based simulator for a given scene. We show that by training on varied batch sizes of events, we can improve test-time predictions of events at fine time resolutions, outperforming baselines that pair standard dynamic NeRFs with event simulators. We release our simulated and real datasets, as well as code for both event-based data generation and the training of event-based dynamic NeRF models (https://github.com/anish-bhattacharya/EvDNeRF).
Is Imitation All You Need? Generalized Decision-Making with Dual-Phase Training
Jul 18, 2023



We introduce DualMind, a generalist agent designed to tackle various decision-making tasks that addresses challenges posed by current methods, such as overfitting behaviors and dependence on task-specific fine-tuning. DualMind uses a novel "Dual-phase" training strategy that emulates how humans learn to act in the world. The model first learns fundamental common knowledge through a self-supervised objective tailored for control tasks and then learns how to make decisions based on different contexts through imitating behaviors conditioned on given prompts. DualMind can handle tasks across domains, scenes, and embodiments using just a single set of model weights and can execute zero-shot prompting without requiring task-specific fine-tuning. We evaluate DualMind on MetaWorld and Habitat through extensive experiments and demonstrate its superior generalizability compared to previous techniques, outperforming other generalist agents by over 50$\%$ and 70$\%$ on Habitat and MetaWorld, respectively. On the 45 tasks in MetaWorld, DualMind achieves over 30 tasks at a 90$\%$ success rate.
SMART: Self-supervised Multi-task pretrAining with contRol Transformers
Jan 24, 2023



Self-supervised pretraining has been extensively studied in language and vision domains, where a unified model can be easily adapted to various downstream tasks by pretraining representations without explicit labels. When it comes to sequential decision-making tasks, however, it is difficult to properly design such a pretraining approach that can cope with both high-dimensional perceptual information and the complexity of sequential control over long interaction horizons. The challenge becomes combinatorially more complex if we want to pretrain representations amenable to a large variety of tasks. To tackle this problem, in this work, we formulate a general pretraining-finetuning pipeline for sequential decision making, under which we propose a generic pretraining framework \textit{Self-supervised Multi-task pretrAining with contRol Transformer (SMART)}. By systematically investigating pretraining regimes, we carefully design a Control Transformer (CT) coupled with a novel control-centric pretraining objective in a self-supervised manner. SMART encourages the representation to capture the common essential information relevant to short-term control and long-term control, which is transferrable across tasks. We show by extensive experiments in DeepMind Control Suite that SMART significantly improves the learning efficiency among seen and unseen downstream tasks and domains under different learning scenarios including Imitation Learning (IL) and Reinforcement Learning (RL). Benefiting from the proposed control-centric objective, SMART is resilient to distribution shift between pretraining and finetuning, and even works well with low-quality pretraining datasets that are randomly collected.
AirSim Drone Racing Lab
Mar 12, 2020



Autonomous drone racing is a challenging research problem at the intersection of computer vision, planning, state estimation, and control. We introduce AirSim Drone Racing Lab, a simulation framework for enabling fast prototyping of algorithms for autonomy and enabling machine learning research in this domain, with the goal of reducing the time, money, and risks associated with field robotics. Our framework enables generation of racing tracks in multiple photo-realistic environments, orchestration of drone races, comes with a suite of gate assets, allows for multiple sensor modalities (monocular, depth, neuromorphic events, optical flow), different camera models, and benchmarking of planning, control, computer vision, and learning-based algorithms. We used our framework to host a simulation based drone racing competition at NeurIPS 2019. The competition binaries are available at our github repository.
Learning Controls Using Cross-Modal Representations: Bridging Simulation and Reality for Drone Racing
Sep 16, 2019
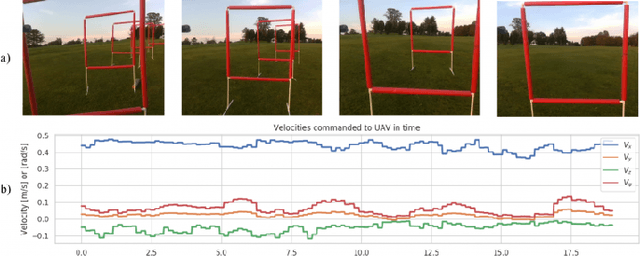


Machines are a long way from robustly solving open-world perception-control tasks, such as first-person view (FPV) drone racing. While recent advances in Machine Learning, especially Reinforcement and Imitation Learning show promise, they are constrained by the need of large amounts of difficult to collect real-world data for learning robust behaviors in diverse scenarios. In this work we propose to learn rich representations and policies by leveraging unsupervised data, such as video footage from an FPV drone, together with easy to generate simulated labeled data. Our approach takes a cross-modal perspective, where separate modalities correspond to the raw camera sensor data and the system states relevant to the task, such as the relative pose gates to the UAV. We fuse both data modalities into a novel factored architecture that learns a joint low-dimensional representation via Variational Auto Encoders. Such joint representations allow us to leverage rich labeled information from simulations together with the diversity of possible experiences via the unsupervised real-world data. We present experiments in simulation that provide insights into the rich latent spaces learned with our proposed representations, and also show that the use of our cross-modal architecture improves control policy performance in over 5X in comparison with end-to-end learning or purely unsupervised feature extractors. Finally, we present real-life results for drone navigation, showing that the learned representations and policies can generalize across simulation and reality.