 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Uncertainty in Shape Completion to Improve Grasp Quality
Apr 22, 2025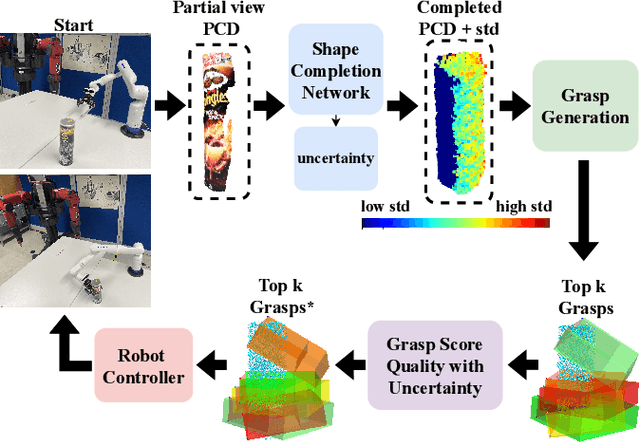
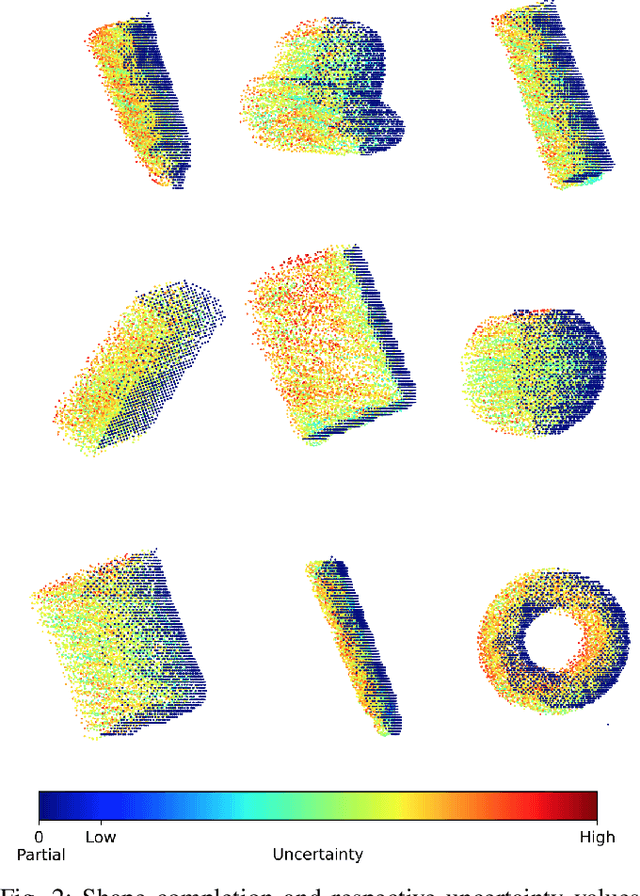

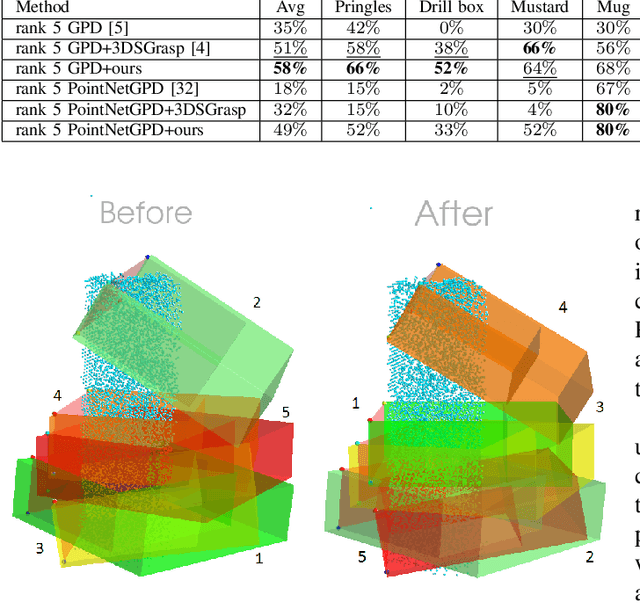
Shape completion networks have been used recently in real-world robotic experiments to complete the missing/hidden information in environments where objects are only observed in one or few instances where self-occlusions are bound to occur. Nowadays, most approaches rely on deep neural networks that handle rich 3D point cloud data that lead to more precise and realistic object geometries. However, these models still suffer from inaccuracies due to its nondeterministic/stochastic inferences which could lead to poor performance in grasping scenarios where these errors compound to unsuccessful grasps. We present an approach to calculate the uncertainty of a 3D shape completion model during inference of single view point clouds of an object on a table top. In addition, we propose an update to grasp pose algorithms quality score by introducing the uncertainty of the completed point cloud present in the grasp candidates. To test our full pipeline we perform real world grasping with a 7dof robotic arm with a 2 finger gripper on a large set of household objects and compare against previous approaches that do not measure uncertainty. Our approach ranks the grasp quality better, leading to higher grasp success rate for the rank 5 grasp candidates compared to state of the art.
Force Feedback Control For Dexterous Robotic Hands Using Conditional Postural Synergies
Mar 10, 2023



We present a force feedback controller for a dexterous robotic hand equipped with force sensors on its fingertips. Our controller uses the conditional postural synergies framework to generate the grasp postures, i.e. the finger configuration of the robot, at each time step based on forces measured on the robot's fingertips. Using this framework we are able to control the hand during different grasp types using only one variable, the grasp size, which we define as the distance between the tip of the thumb and the index finger. Instead of controlling the finger limbs independently, our controller generates control signals for all the hand joints in a (low-dimensional) shared space (i.e. synergy space). In addition, our approach is modular, which allows to execute various types of precision grips, by changing the synergy space according to the type of grasp. We show that our controller is able to lift objects of various weights and materials, adjust the grasp configuration during changes in the object's weight, and perform object placements and object handovers.
3DSGrasp: 3D Shape-Completion for Robotic Grasp
Jan 02, 2023



Real-world robotic grasping can be done robustly if a complete 3D Point Cloud Data (PCD) of an object is available. However, in practice, PCDs are often incomplete when objects are viewed from few and sparse viewpoints before the grasping action, leading to the generation of wrong or inaccurate grasp poses. We propose a novel grasping strategy, named 3DSGrasp, that predicts the missing geometry from the partial PCD to produce reliable grasp poses. Our proposed PCD completion network is a Transformer-based encoder-decoder network with an Offset-Attention layer. Our network is inherently invariant to the object pose and point's permutation, which generates PCDs that are geometrically consistent and completed properly. Experiments on a wide range of partial PCD show that 3DSGrasp outperforms the best state-of-the-art method on PCD completion tasks and largely improves the grasping success rate in real-world scenarios. The code and dataset will be made available upon acceptance.
One-shot action recognition towards novel assistive therapies
Feb 17, 2021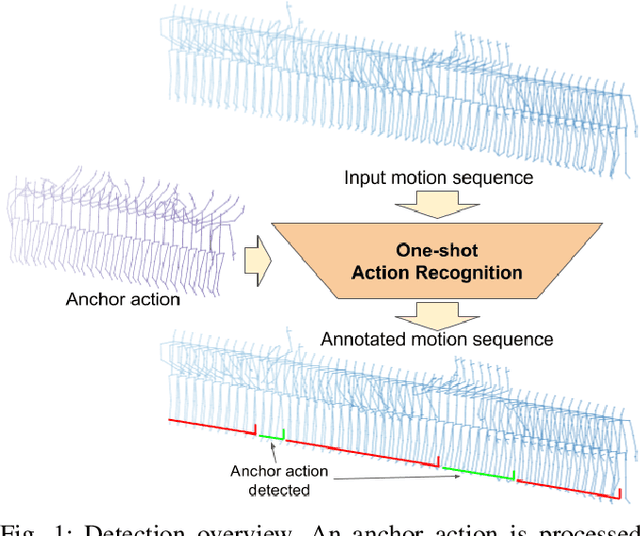
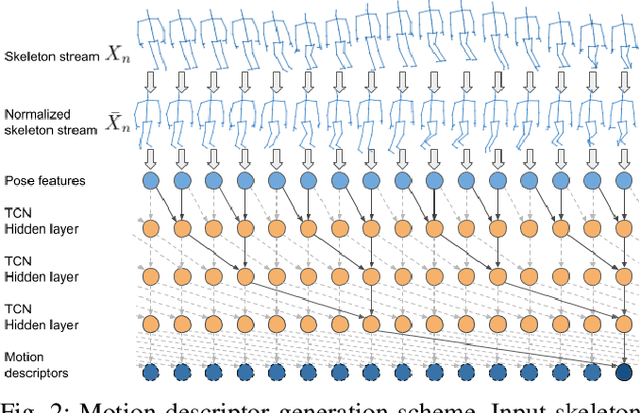
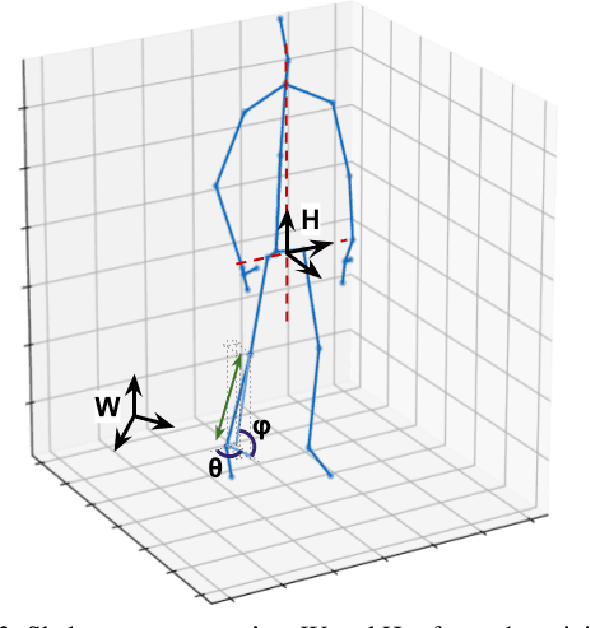

One-shot action recognition is a challenging problem, especially when the target video can contain one, more or none repetitions of the target action. Solutions to this problem can be used in many real world applications that require automated processing of activity videos. In particular, this work is motivated by the automated analysis of medical therapies that involve action imitation games. The presented approach incorporates a pre-processing step that standardizes heterogeneous motion data conditions and generates descriptive movement representations with a Temporal Convolutional Network for a final one-shot (or few-shot) action recognition. Our method achieves state-of-the-art results on the public NTU-120 one-shot action recognition challenge. Besides, we evaluate the approach on a real use-case of automated video analysis for therapy support with autistic people. The promising results prove its suitability for this kind of application in the wild, providing both quantitative and qualitative measures, essential for the patient evaluation and monitoring.