 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Scene Reconstruction from Light-Field Images Affected by Rolling Shutter
Dec 04, 2024



This paper presents a dense depth estimation approach from light-field (LF) images that is able to compensate for strong rolling shutter (RS) effects. Our method estimates RS compensated views and dense RS compensated disparity maps. We present a two-stage method based on a 2D Gaussians Splatting that allows for a ``render and compare" strategy with a point cloud formulation. In the first stage, a subset of sub-aperture images is used to estimate an RS agnostic 3D shape that is related to the scene target shape ``up to a motion". In the second stage, the deformation of the 3D shape is computed by estimating an admissible camera motion. We demonstrate the effectiveness and advantages of this approach through several experiments conducted for different scenes and types of motions. Due to lack of suitable datasets for evaluation, we also present a new carefully designed synthetic dataset of RS LF images. The source code, trained models and dataset will be made publicly available at: https://github.com/ICB-Vision-AI/DenseRSLF
Depth-Adapted CNN for RGB-D cameras
Sep 23, 2020
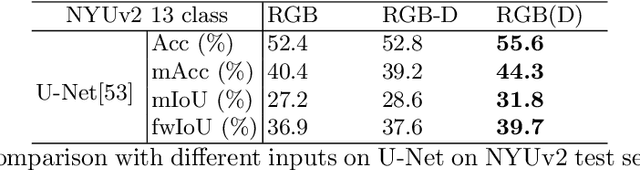
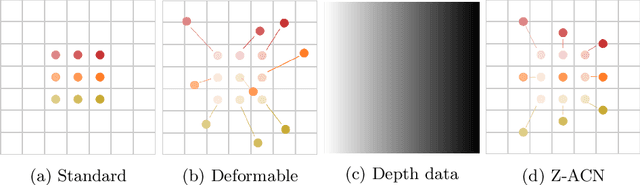
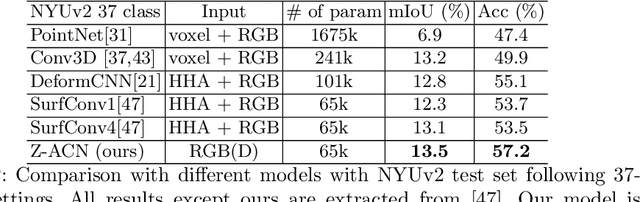
Conventional 2D Convolutional Neural Networks (CNN) extract features from an input image by applying linear filters. These filters compute the spatial coherence by weighting the photometric information on a fixed neighborhood without taking into account the geometric information. We tackle the problem of improving the classical RGB CNN methods by using the depth information provided by the RGB-D cameras. State-of-the-art approaches use depth as an additional channel or image (HHA) or pass from 2D CNN to 3D CNN. This paper proposes a novel and generic procedure to articulate both photometric and geometric information in CNN architecture. The depth data is represented as a 2D offset to adapt spatial sampling locations. The new model presented is invariant to scale and rotation around the X and the Y axis of the camera coordinate system. Moreover, when depth data is constant, our model is equivalent to a regular CNN. Experiments of benchmarks validate the effectiveness of our model.
PanoRoom: From the Sphere to the 3D Layout
Aug 29, 2018

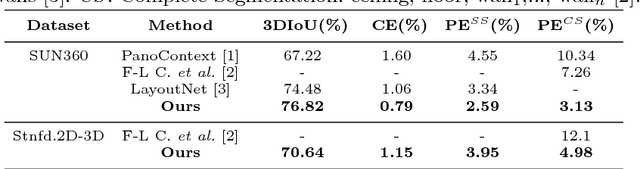

We propose a novel FCN able to work with omnidirectional images that outputs accurate probability maps representing the main structure of indoor scenes, which is able to generalize on different data. Our approach handles occlusions and recovers complex shaped rooms more faithful to the actual shape of the real scenes. We outperform the state of the art not only in accuracy of the 3D models but also in speed.