 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Adapted CNNs for RGB-D Semantic Segmentation
Jun 08, 2022
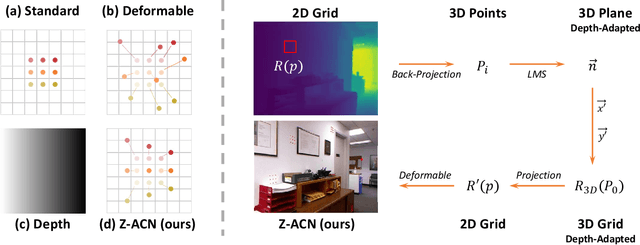
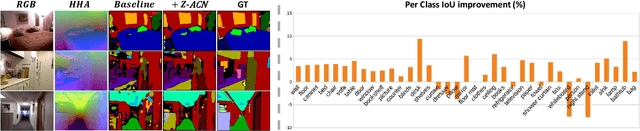
Recent RGB-D semantic segmentation has motivated research interest thanks to the accessibility of complementary modalities from the input side. Existing works often adopt a two-stream architecture that processes photometric and geometric information in parallel, with few methods explicitly leveraging the contribution of depth cues to adjust the sampling position on RGB images. In this paper, we propose a novel framework to incorporate the depth information in the RGB convolutional neural network (CNN), termed Z-ACN (Depth-Adapted CNN). Specifically, our Z-ACN generates a 2D depth-adapted offset which is fully constrained by low-level features to guide the feature extraction on RGB images. With the generated offset, we introduce two intuitive and effective operations to replace basic CNN operators: depth-adapted convolution and depth-adapted average pooling. Extensive experiments on both indoor and outdoor semantic segmentation tasks demonstrate the effectiveness of our approach.
Modality-Guided Subnetwork for Salient Object Detection
Oct 25, 2021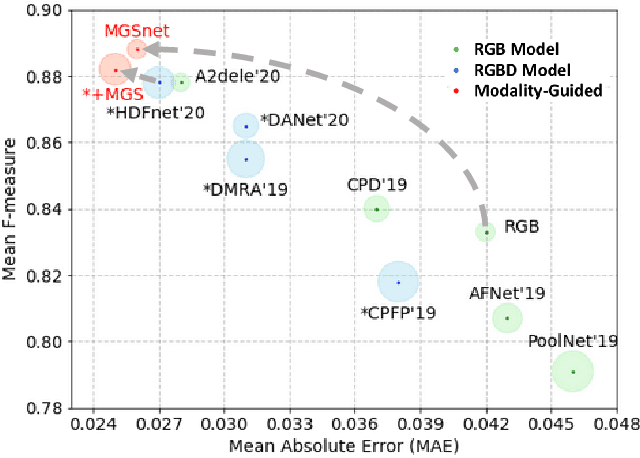
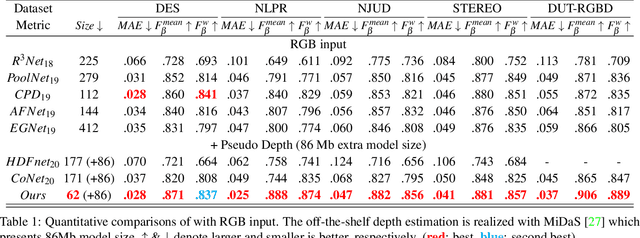
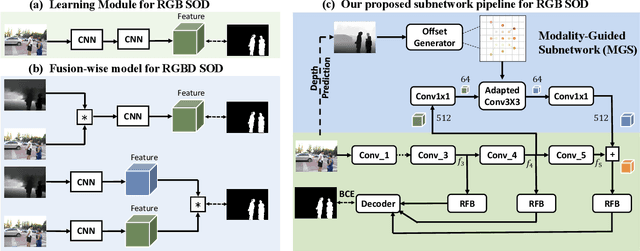
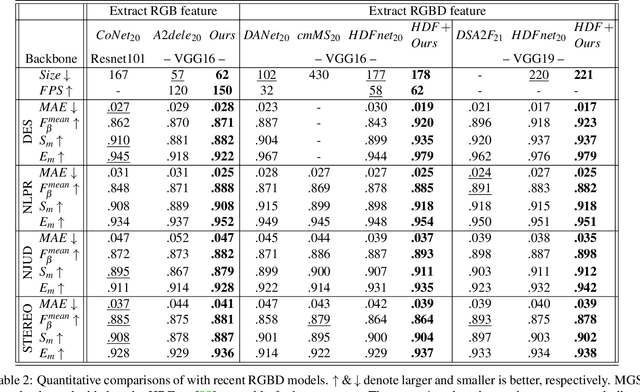
Recent RGBD-based models for saliency detection have attracted research attention. The depth clues such as boundary clues, surface normal, shape attribute, etc., contribute to the identification of salient objects with complicated scenarios. However, most RGBD networks require multi-modalities from the input side and feed them separately through a two-stream design, which inevitably results in extra costs on depth sensors and computation. To tackle these inconveniences, we present in this paper a novel fusion design named modality-guided subnetwork (MGSnet). It has the following superior designs: 1) Our model works for both RGB and RGBD data, and dynamically estimating depth if not available. Taking the inner workings of depth-prediction networks into account, we propose to estimate the pseudo-geometry maps from RGB input - essentially mimicking the multi-modality input. 2) Our MGSnet for RGB SOD results in real-time inference but achieves state-of-the-art performance compared to other RGB models. 3) The flexible and lightweight design of MGS facilitates the integration into RGBD two-streaming models. The introduced fusion design enables a cross-modality interaction to enable further progress but with a minimal cost.
Depth-Adapted CNN for RGB-D cameras
Sep 23, 2020
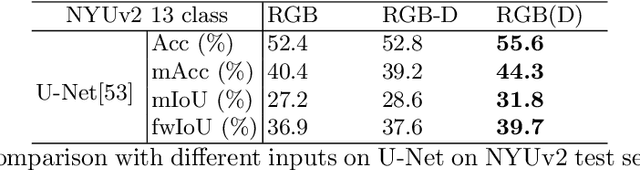
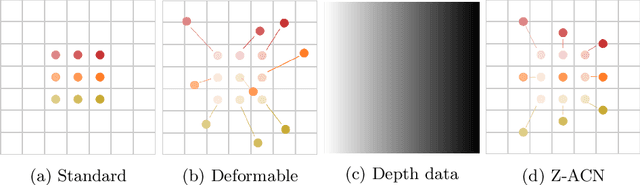
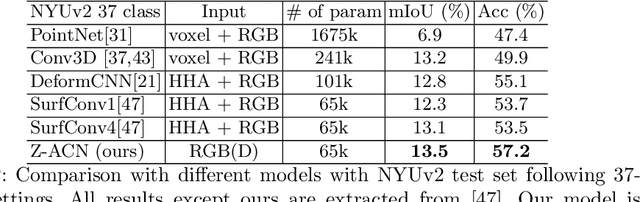
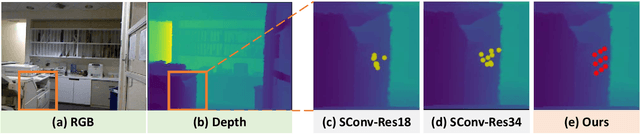
Conventional 2D Convolutional Neural Networks (CNN) extract features from an input image by applying linear filters. These filters compute the spatial coherence by weighting the photometric information on a fixed neighborhood without taking into account the geometric information. We tackle the problem of improving the classical RGB CNN methods by using the depth information provided by the RGB-D cameras. State-of-the-art approaches use depth as an additional channel or image (HHA) or pass from 2D CNN to 3D CNN. This paper proposes a novel and generic procedure to articulate both photometric and geometric information in CNN architecture. The depth data is represented as a 2D offset to adapt spatial sampling locations. The new model presented is invariant to scale and rotation around the X and the Y axis of the camera coordinate system. Moreover, when depth data is constant, our model is equivalent to a regular CNN. Experiments of benchmarks validate the effectiveness of our model.