 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Image Distortions in Deep Feature Space
Paper and Code
Feb 26, 2020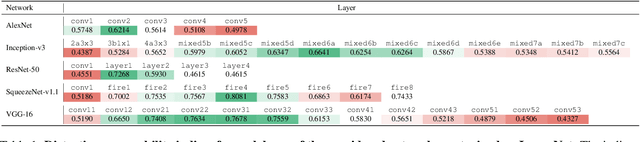

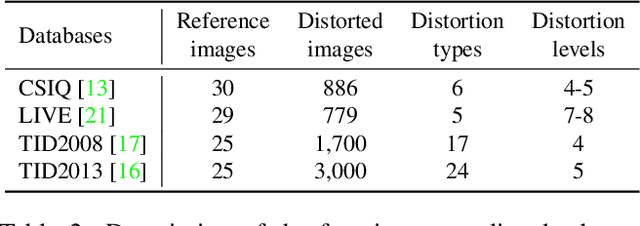
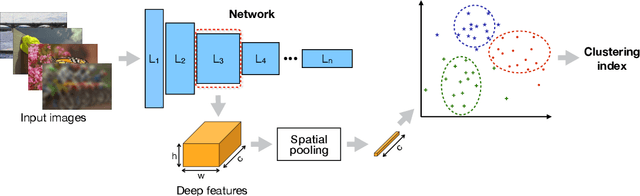
Previous literature suggests that perceptual similarity is an emergent property shared across deep visual representations. Experiments conducted on a dataset of human-judged image distortions have proven that deep features outperform, by a large margin, classic perceptual metrics. In this work we take a further step in the direction of a broader understanding of such property by analyzing the capability of deep visual representations to intrinsically characterize different types of image distortions. To this end, we firstly generate a number of synthetically distorted images by applying three mainstream distortion types to the LIVE database and then we analyze the features extracted by different layers of different Deep Network architectures. We observe that a dimension-reduced representation of the features extracted from a given layer permits to efficiently separate types of distortions in the feature space. Moreover, each network layer exhibits a different ability to separate between different types of distortions, and this ability varies according to the network architecture. As a further analysis, we evaluate the exploitation of features taken from the layer that better separates image distortions for: i) reduced-reference image quality assessment, and ii) distortion types and severity levels characterization on both single and multiple distortion databases. Results achieved on both tasks suggest that deep visual representations can be unsupervisedly employed to efficiently characterize various image distortions.