 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Multispectral Sensors for Color Correction in Mobile Cameras
Dec 09, 2025Recent advances in snapshot multispectral (MS) imaging have enabled compact, low-cost spectral sensors for consumer and mobile devices. By capturing richer spectral information than conventional RGB sensors, these systems can enhance key imaging tasks, including color correction. However, most existing methods treat the color correction pipeline in separate stages, often discarding MS data early in the process. We propose a unified, learning-based framework that (i) performs end-to-end color correction and (ii) jointly leverages data from a high-resolution RGB sensor and an auxiliary low-resolution MS sensor. Our approach integrates the full pipeline within a single model, producing coherent and color-accurate outputs. We demonstrate the flexibility and generality of our framework by refactoring two different state-of-the-art image-to-image architectures. To support training and evaluation, we construct a dedicated dataset by aggregating and repurposing publicly available spectral datasets, rendering under multiple RGB camera sensitivities. Extensive experiments show that our approach improves color accuracy and stability, reducing error by up to 50% compared to RGB-only and MS-driven baselines. Datasets, code, and models will be made available upon acceptance.
NTIRE 2024 Challenge on Night Photography Rendering
Jun 18, 2024


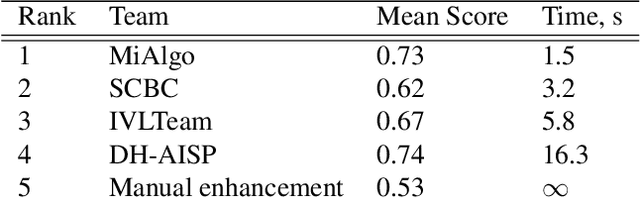
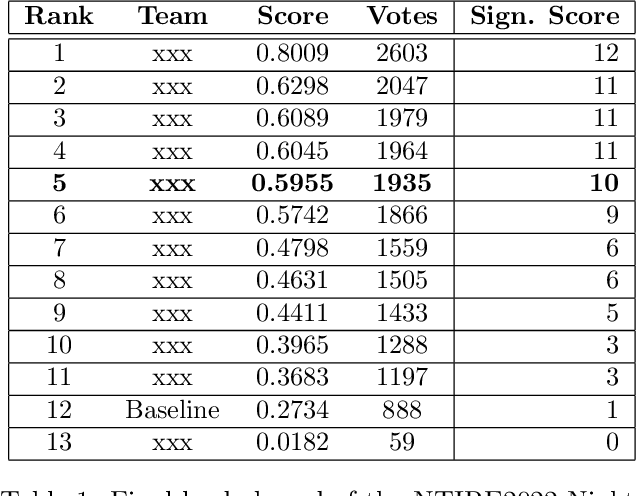
This paper presents a review of the NTIRE 2024 challenge on night photography rendering. The goal of the challenge was to find solutions that process raw camera images taken in nighttime conditions, and thereby produce a photo-quality output images in the standard RGB (sRGB) space. Unlike the previous year's competition, the challenge images were collected with a mobile phone and the speed of algorithms was also measured alongside the quality of their output. To evaluate the results, a sufficient number of viewers were asked to assess the visual quality of the proposed solutions, considering the subjective nature of the task. There were 2 nominations: quality and efficiency. Top 5 solutions in terms of output quality were sorted by evaluation time (see Fig. 1). The top ranking participants' solutions effectively represent the state-of-the-art in nighttime photography rendering. More results can be found at https://nightimaging.org.
Enhancing Perceptual Quality in Video Super-Resolution through Temporally-Consistent Detail Synthesis using Diffusion Models
Nov 27, 2023



In this paper, we address the problem of video super-resolution (VSR) using Diffusion Models (DM), and present StableVSR. Our method significantly enhances the perceptual quality of upscaled videos by synthesizing realistic and temporally-consistent details. We turn a pre-trained DM for single image super-resolution into a VSR method by introducing the Temporal Conditioning Module (TCM). TCM uses Temporal Texture Guidance, which provides spatially-aligned and detail-rich texture information synthesized in adjacent frames. This guides the generative process of the current frame toward high-quality and temporally-consistent results. We introduce a Frame-wise Bidirectional Sampling strategy to encourage the use of information from past to future and vice-versa. This strategy improves the perceptual quality of the results and the temporal consistency across frames. We demonstrate the effectiveness of StableVSR in enhancing the perceptual quality of upscaled videos compared to existing state-of-the-art methods for VSR. The code is available at https://github.com/claudiom4sir/StableVSR.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022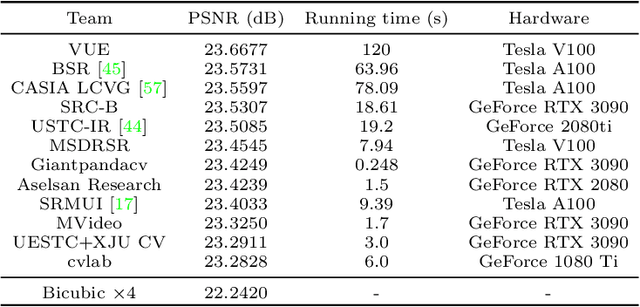
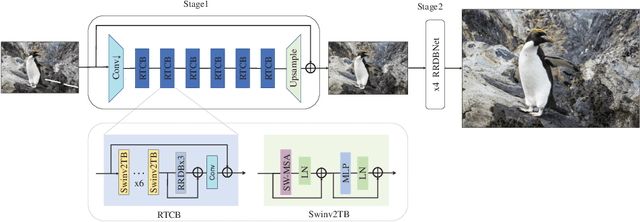

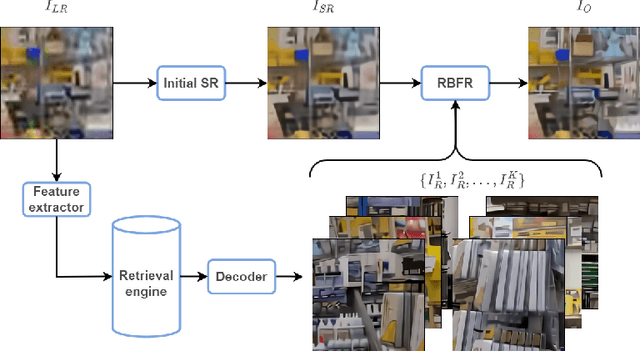
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
Shallow camera pipeline for night photography rendering
Apr 19, 2022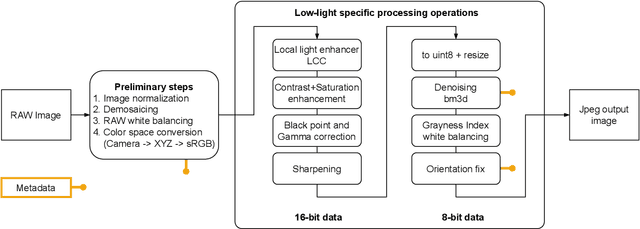

We introduce a camera pipeline for rendering visually pleasing photographs in low light conditions, as part of the NTIRE2022 Night Photography Rendering challenge. Given the nature of the task, where the objective is verbally defined by an expert photographer instead of relying on explicit ground truth images, we design an handcrafted solution, characterized by a shallow structure and by a low parameter count. Our pipeline exploits a local light enhancer as a form of high dynamic range correction, followed by a global adjustment of the image histogram to prevent washed-out results. We proportionally apply image denoising to darker regions, where it is more easily perceived, without losing details on brighter regions. The solution reached the fifth place in the competition, with a preference vote count comparable to those of other entries, based on deep convolutional neural networks. Code is available at www.github.com/AvailableAfterAcceptance.
Planckian jitter: enhancing the color quality of self-supervised visual representations
Feb 16, 2022
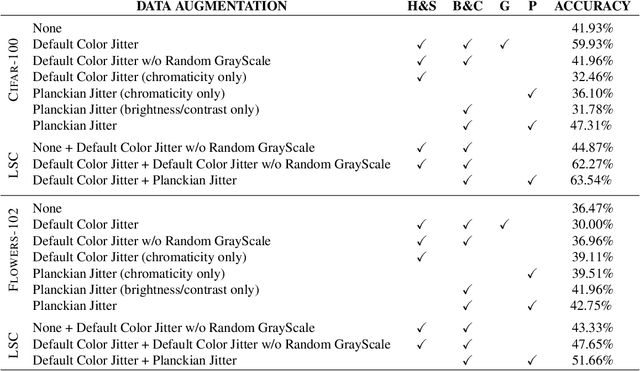
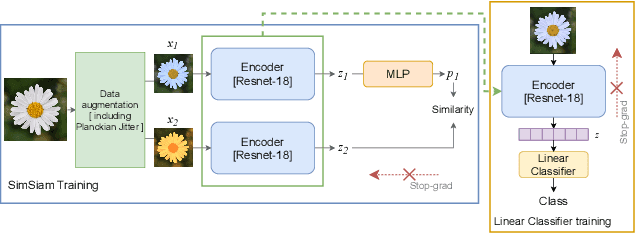
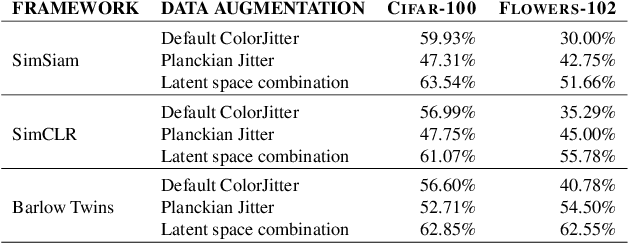
Several recent works on self-supervised learning are trained by mapping different augmentations of the same image to the same feature representation. The set of used data augmentations is of crucial importance for the quality of the learned feature representation. We analyze how the traditionally used color jitter negatively impacts the quality of the color features in the learned feature representation. To address this problem, we replace this module with physics-based color augmentation, called Planckian jitter, which creates realistic variations in chromaticity, producing a model robust to llumination changes that can be commonly observed in real life, while maintaining the ability to discriminate the image content based on color information. We further improve the performance by introducing a latent space combination of color-sensitive and non-color-sensitive features. These are found to be complementary and the combination leads to large absolute performance gains over the default data augmentation on color classification tasks, including on Flowers-102 (+15%), Cub200 (+11%), VegFru (+15%), and T1K+ (+12%). Finally, we present a color sensitivity analysis to document the impact of different training methods on the model neurons and we show that the performance of the learned features is robust with respect to illuminant variations.
Illumination Estimation Challenge: experience of past two years
Dec 31, 2020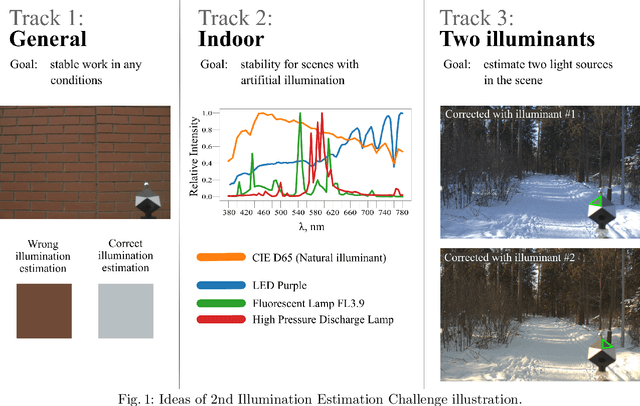
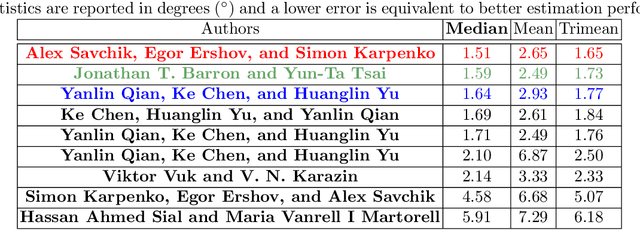

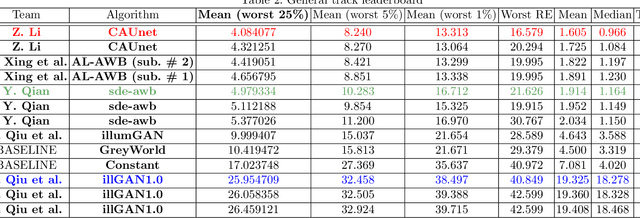
Illumination estimation is the essential step of computational color constancy, one of the core parts of various image processing pipelines of modern digital cameras. Having an accurate and reliable illumination estimation is important for reducing the illumination influence on the image colors. To motivate the generation of new ideas and the development of new algorithms in this field, the 2nd Illumination estimation challenge~(IEC\#2) was conducted. The main advantage of testing a method on a challenge over testing in on some of the known datasets is the fact that the ground-truth illuminations for the challenge test images are unknown up until the results have been submitted, which prevents any potential hyperparameter tuning that may be biased. The challenge had several tracks: general, indoor, and two-illuminant with each of them focusing on different parameters of the scenes. Other main features of it are a new large dataset of images (about 5000) taken with the same camera sensor model, a manual markup accompanying each image, diverse content with scenes taken in numerous countries under a huge variety of illuminations extracted by using the SpyderCube calibration object, and a contest-like markup for the images from the Cube+ dataset that was used in IEC\#1. This paper focuses on the description of the past two challenges, algorithms which won in each track, and the conclusions that were drawn based on the results obtained during the 1st and 2nd challenge that can be useful for similar future developments.
Learning Illuminant Estimation from Object Recognition
May 23, 2018



In this paper we present a deep learning method to estimate the illuminant of an image. Our model is not trained with illuminant annotations, but with the objective of improving performance on an auxiliary task such as object recognition. To the best of our knowledge, this is the first example of a deep learning architecture for illuminant estimation that is trained without ground truth illuminants. We evaluate our solution on standard datasets for color constancy, and compare it with state of the art methods. Our proposal is shown to outperform most deep learning methods in a cross-dataset evaluation setup, and to present competitive results in a comparison with parametric solutions.
Deep Learning for Logo Recognition
May 03, 2017



In this paper we propose a method for logo recognition using deep learning. Our recognition pipeline is composed of a logo region proposal followed by a Convolutional Neural Network (CNN) specifically trained for logo classification, even if they are not precisely localized. Experiments are carried out on the FlickrLogos-32 database, and we evaluate the effect on recognition performance of synthetic versus real data augmentation, and image pre-processing. Moreover, we systematically investigate the benefits of different training choices such as class-balancing, sample-weighting and explicit modeling the background class (i.e. no-logo regions). Experimental results confirm the feasibility of the proposed method, that outperforms the methods in the state of the art.
* Preprint accepted in Neurocomputing