 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailoring Adverse Event Prediction in Type 1 Diabetes with Patient-Specific Deep Learning Models
Jan 21, 2026Effective management of Type 1 Diabetes requires continuous glucose monitoring and precise insulin adjustments to prevent hyperglycemia and hypoglycemia. With the growing adoption of wearable glucose monitors and mobile health applications, accurate blood glucose prediction is essential for enhancing automated insulin delivery and decision-support systems. This paper presents a deep learning-based approach for personalized blood glucose prediction, leveraging patient-specific data to improve prediction accuracy and responsiveness in real-world scenarios. Unlike traditional generalized models, our method accounts for individual variability, enabling more effective subject-specific predictions. We compare Leave-One-Subject-Out Cross-Validation with a fine-tuning strategy to evaluate their ability to model patient-specific dynamics. Results show that personalized models significantly improve the prediction of adverse events, enabling more precise and timely interventions in real-world scenarios. To assess the impact of patient-specific data, we conduct experiments comparing a multimodal, patient-specific approach against traditional CGM-only methods. Additionally, we perform an ablation study to investigate model performance with progressively smaller training sets, identifying the minimum data required for effective personalization-an essential consideration for real-world applications where extensive data collection is often challenging. Our findings underscore the potential of adaptive, personalized glucose prediction models for advancing next-generation diabetes management, particularly in wearable and mobile health platforms, enhancing consumer-oriented diabetes care solutions.
Lightweight Sequential Transformers for Blood Glucose Level Prediction in Type-1 Diabetes
Jun 09, 2025Type 1 Diabetes (T1D) affects millions worldwide, requiring continuous monitoring to prevent severe hypo- and hyperglycemic events. While continuous glucose monitoring has improved blood glucose management, deploying predictive models on wearable devices remains challenging due to computational and memory constraints. To address this, we propose a novel Lightweight Sequential Transformer model designed for blood glucose prediction in T1D. By integrating the strengths of Transformers' attention mechanisms and the sequential processing of recurrent neural networks, our architecture captures long-term dependencies while maintaining computational efficiency. The model is optimized for deployment on resource-constrained edge devices and incorporates a balanced loss function to handle the inherent data imbalance in hypo- and hyperglycemic events. Experiments on two benchmark datasets, OhioT1DM and DiaTrend, demonstrate that the proposed model outperforms state-of-the-art methods in predicting glucose levels and detecting adverse events. This work fills the gap between high-performance modeling and practical deployment, providing a reliable and efficient T1D management solution.
Deep Learning Hyperspectral Pansharpening on large scale PRISMA dataset
Jul 28, 2023In this work, we assess several deep learning strategies for hyperspectral pansharpening. First, we present a new dataset with a greater extent than any other in the state of the art. This dataset, collected using the ASI PRISMA satellite, covers about 262200 km2, and its heterogeneity is granted by randomly sampling the Earth's soil. Second, we adapted several state of the art approaches based on deep learning to fit PRISMA hyperspectral data and then assessed, quantitatively and qualitatively, the performance in this new scenario. The investigation has included two settings: Reduced Resolution (RR) to evaluate the techniques in a supervised environment and Full Resolution (FR) for a real-world evaluation. The main purpose is the evaluation of the reconstruction fidelity of the considered methods. In both scenarios, for the sake of completeness, we also included machine-learning-free approaches. From this extensive analysis has emerged that data-driven neural network methods outperform machine-learning-free approaches and adapt better to the task of hyperspectral pansharpening, both in RR and FR protocols.
Unsupervised Segmentation of Hyperspectral Remote Sensing Images with Superpixels
Apr 26, 2022
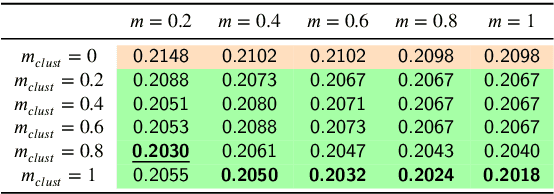
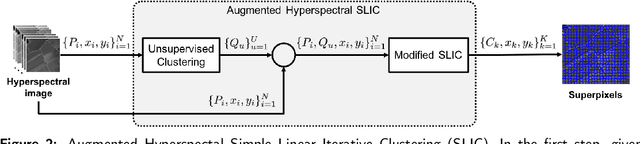
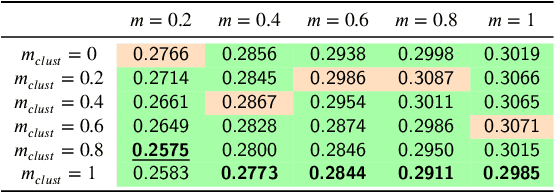
In this paper, we propose an unsupervised method for hyperspectral remote sensing image segmentation. The method exploits the mean-shift clustering algorithm that takes as input a preliminary hyperspectral superpixels segmentation together with the spectral pixel information. The proposed method does not require the number of segmentation classes as input parameter, and it does not exploit any a-priori knowledge about the type of land-cover or land-use to be segmented (e.g. water, vegetation, building etc.). Experiments on Salinas, SalinasA, Pavia Center and Pavia University datasets are carried out. Performance are measured in terms of normalized mutual information, adjusted Rand index and F1-score. Results demonstrate the validity of the proposed method in comparison with the state of the art.